社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Java中的RandomAccessFile提供了对文件的读写功能。RandomAccessFile 虽然属于java.io下的类,但它不是InputStream或者OutputStream的子类;它也不同于FileInputStream和FileOutputStream。 FileInputStream 只能对文件进行读操作,而FileOutputStream 只能对文件进行写操作;但是,RandomAccessFile 与输入流和输出流不同之处就是RandomAccessFile可以访问文件的任意地方同时支持文件的读和写,并且它支持随机访问。RandomAccessFile包含InputStream的三个read方法,也包含OutputStream的三个write方法。
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.RandomAccessFile;
public class WriteStreamAppend {
/**
* 追加文件:使用FileOutputStream,在构造FileOutputStream时,把第二个参数设为true
*
* @param fileName
* @param content
*/
public static void method1(String file, String conent) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file, true)));
out.write(conent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 追加文件:使用FileWriter
*
* @param fileName
* @param content
*/
public static void method2(String fileName, String content) {
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
FileWriter writer = new FileWriter(fileName, true);
writer.write(content);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 追加文件:使用RandomAccessFile
*
* @param fileName
* 文件名
* @param content
* 追加的内容
*/
public static void method3(String fileName, String content) {
try {
// 打开一个随机访问文件流,按读写方式
RandomAccessFile randomFile = new RandomAccessFile(fileName, "rw");
// 文件长度,字节数
long fileLength = randomFile.length();
// 将写文件指针移到文件尾。
randomFile.seek(fileLength);
randomFile.writeBytes(content);
randomFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
System.out.println("start");
method1("c:/test.txt", "追加到文件的末尾");
System.out.println("end");
} 1、分区写,减少单台机器压力
2、消息顺序写入磁盘
3、批量写
4、内存映射文件MMAP(Memory Mapped Files)
(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)
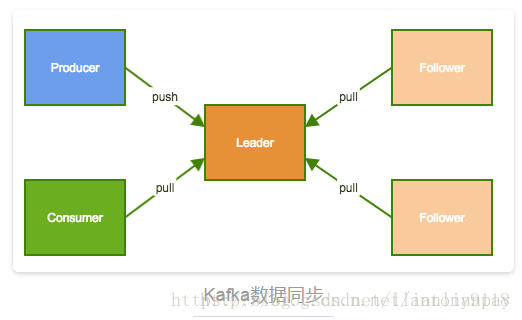
Producer和Consumer都只与Leader交互,每个Follower从Leader拉取数据进行同步。
ISR (In-Sync Replicas),这个是指副本同步队列
具体参数设置:
request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功。
min.insync.replicas: 设置为>=2,保证ISR中至少两个Replica。
request.required.acks:
0: 表示Producer从来不等待来自broker的确认信息。这个选择提供了最小的时延但同时风险最大(因为当server宕机时,数据将会丢失)。
1:表示获得Leader replica已经接收了数据的确认信息。这个选择时延较小同时确保了server确认接收成功。
-1:Producer会获得所有同步replicas都收到数据的确认。同时时延最大,然而,这种方式并没有完全消除丢失消息的风险,因为同步replicas的数量可能是1。
每一条消息被发送到broker中,会根据partition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然可以在topic创建之后去修改partition的数量。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=3在发送一条消息时,可以指定这个消息的key,producer根据这个key和partition机制来判断这个消息发送到哪个partition。partition机制可以通过指定producer的partition.class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。通过调节其副本相关参数,可以使得Kafka在性能和可靠性之间运转的游刃有余。
为了便于说明问题,假设这里只有一个Kafka集群,且这个集群只有一个Kafka broker,即只有一台物理机。在这个Kafka broker中配置(KAFKA_HOME/bin/kafka-topics.sh –create –zookeeper localhost:2181 –partitions 4 –topic topic_vms_test –replication-factor 4)。那么我们此时可以在/tmp/kafka-logs目录中可以看到生成了4个目录:
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-0
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-1
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-2
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-3partition还可以细分为segment,这个segment又是什么?如果就以partition为最小存储单位,我们可以想象当Kafka producer不断发送消息,必然会引起partition文件的无限扩张,这样对于消息文件的维护以及已经被消费的消息的清理带来严重的影响,所以这里以segment为单位又将partition细分。每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等的segment(段)数据文件中(每个segment 文件中消息数量不一定相等)这种特性也方便old segment的删除,即方便已被消费的消息的清理,提高磁盘的利用率。每个partition只需要支持顺序读写就行,segment的文件生命周期由服务端配置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定。
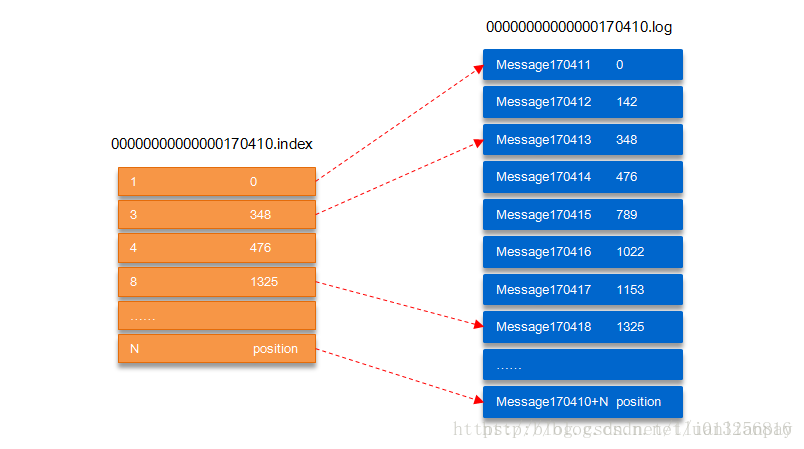
segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为segment索引文件和数据文件。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log以上面的segment文件为例,展示出segment:00000000000000170410的“.index”文件和“.log”文件的对应的关系,如下图:
如上图,“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中message的物理偏移地址。其中以“.index”索引文件中的元数据[3, 348]为例,在“.log”数据文件表示第3个消息,即在全局partition中表示170410+3=170413个消息,该消息的物理偏移地址为348。
Kafka中topic的每个partition有一个预写式的日志文件,虽然partition可以继续细分为若干个segment文件,但是对于上层应用来说可以将partition看成最小的存储单元(一个有多个segment文件拼接的“巨型”文件),每个partition都由一些列有序的、不可变的消息组成,这些消息被连续的追加到partition中。
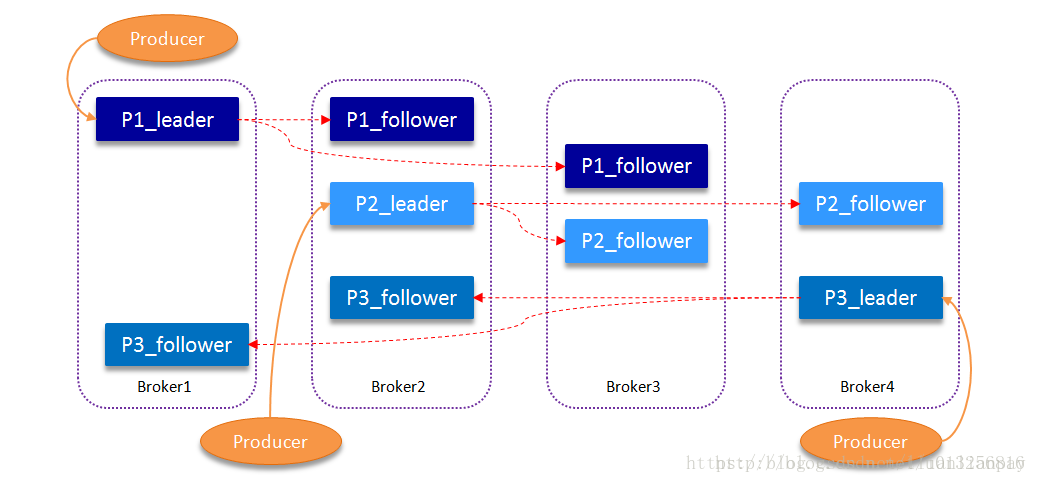
当Kafka集群中一个broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的日志能有序地写到其他节点上,N个replicas中,其中一个replica为leader,其他都为follower, leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。
如下图所示,Kafka集群中有4个broker, 某topic有3个partition,且复制因子即副本个数也为3:
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列)中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
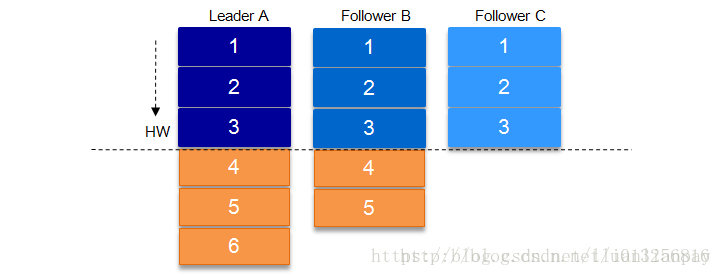
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broKer的读取请求,没有HW的限制。
Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。目前有两个地方会对这个Zookeeper的节点进行维护:
Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时(前面ISR那一节讲到,ISR中的成员由于某些情况会增加也会减少,最少就只剩一个leader),这样就变成了acks=1的情况。
如果要提高数据的可靠性,在设置request.required.acks=-1的同时,也要min.insync.replicas这个参数(可以在broker或者topic层面进行设置)的配合,这样才能发挥最大的功效。
如上图,某个topic的某partition有三个副本,分别为A、B、C。A作为leader肯定是LEO最高,B紧随其后,C机器由于配置比较低,网络比较差,故而同步最慢。这个时候A机器宕机,这时候如果B成为leader,假如没有HW,在A重新恢复之后会做同步(makeFollower)操作,在宕机时log文件之后直接做追加操作,而假如B的LEO已经达到了A的LEO,会产生数据不一致的情况,所以使用HW来避免这种情况。
A在做同步操作的时候,先将log文件截断到之前自己的HW的位置,即3,之后再从B中拉取消息进行同步。
如果失败的follower恢复过来,它首先将自己的log文件截断到上次checkpointed时刻的HW的位置,之后再从leader中同步消息。leader挂掉会重新选举,新的leader会发送“指令”让其余的follower截断至自身的HW的位置然后再拉取新的消息。
当ISR中的个副本的LEO不一致时,如果此时leader挂掉,选举新的leader时并不是按照LEO的高低进行选举,而是按照ISR中的顺序选举。
参考:http://www.importnew.com/25247.html
取正(bytearray生成32位hash值)%numpartitions
这个公式的结果是得到0-(numpartitions-1)间正整数的个数大致相等,也就是说kafka的默认分区策略是无论我们给定多少个分区,我们存放的数据基本上会平均的分到各个分区上。
自定义分区策略
实际开发中会遇到不让数据均匀分布,如按照范围放到不同的分区中,这样就得使用自定义的分区策略了
在创建ProducerRecord时,指定消息的分区值。
int partition = 0;
if(key<100){
partition = 0;
}else if(key<200){
partition = 1;
}else{
partition = 2;
}
ProducerRecord<String,String> records = new ProducerRecord<String,String>(TOPIC,partition,key,value);
kafkaProducer.send(records);public class KafkaCustomPartitioner implements Partitioner {
public void configure(Map<String, ?> arg0) {}
public void close() {}
public int partition(String topic, Object arg1, byte[] keyBytes, Object arg3, byte[] arg4, Cluster arg5) {
//List availablePartitions = cluster.availablePartitionsForTopic(topic);
int partition = availablePartitions.size();
//if(availablePartitions.size() > 0)
int key = Integer.parseInt(new String(keyBytes));
if(key<100){
partition = 0;
}else if(key<200){
partition = 1;
}else{
partition = 2;
}
return partition;
}
}props.put(“partitioner.class”, “xx.xx.KafkaCustomPartitioner”);
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!