
任务:对全国充电桩信息进行爬取
对于实战练习不像平时小练习,需要抓取的数据完整,准确,数据量相对较大,这种情况下就需要考虑到一些问题,比如速率,数据量大容易被反爬,cookie失效,还有重要的一个就是断点续传等问题。
由于数据量较大,中间容易各种原因断掉,比如网络,连接数过大,cookie失效等原因,因此为了避免大量数据重新爬取,需要做断点续传,断点续传的方法也较多,这里我使用的是redis去重,简单来说就是将每一个充电桩的code爬取出来之后,往redis中已建好的一个集合gaode_id中丢,如果成功则表示未爬取过需要爬取,如果失败,则表示已经爬取过不做处理,大大缩短重复爬取的时间
对应代码:

通过浏览器开发者工具查找,发现每个充电桩的code信息在url:http://admin.bjev520.com/jsp/beiqi/pcmap/pages/pcmap_Left.jsp'中,不同地市返回的code不一样,但是此url是一样的,区别在于headers中的referer信息不同,该信息为上一个url的链接地址,这其中包含有地市信息。
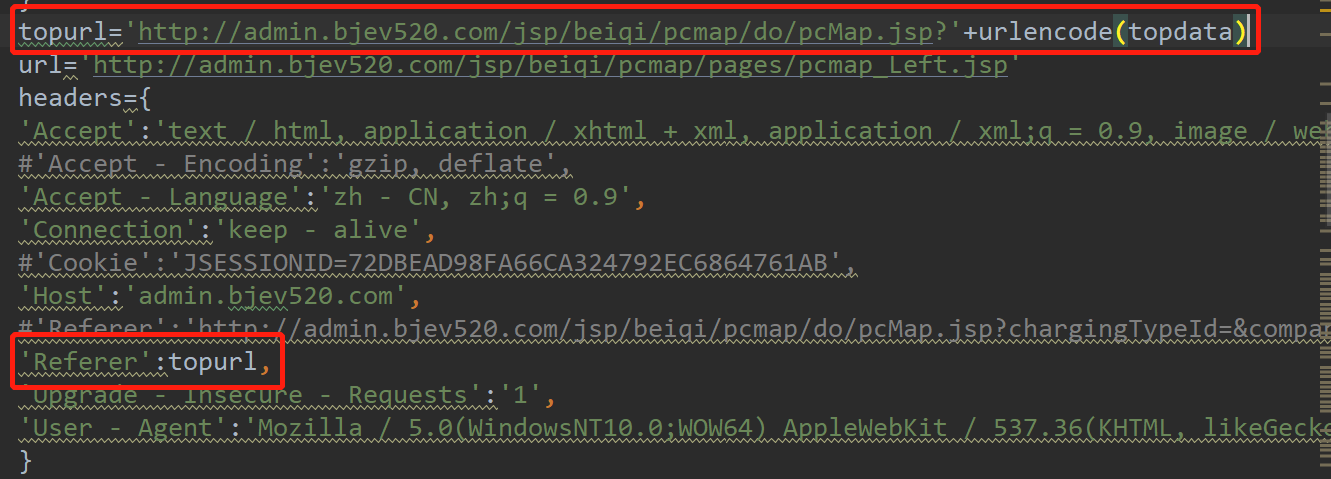
但是仅仅在这里传入地市信息,还无法得到正确的code信息,尝试爬取会发现,所有地市爬取到的code都是一样的,并未起作用。通过观察发现,每爬取下一个城市的code信息时,需要在城市列表中手动选择需要爬取的城市,之后页面会被刷新,会得到真正的code信息,因此在爬取这一步之前,先python要get一下上一条城市列表信息,且要建立同一条session,对应的cookie去掉,才能达到最终目的。

总结:
1. 写爬虫时一定要养成良好习惯,规范,该省的代码不能省,不管数据量大还是小,建好redis以便断点续传,防止重复抓取。
2. 对于一些特殊问题如此次页面刷新的问题,多点开几个url,观察规律,多测试不同代码的区别找到最终解决的方法。
