核心对象:若某个点的密度达到算法设定的阈值则其为核心点。
ϵ-邻域的距离阈值是我们设定的半径r
直接密度可达:若某点p在点q的 r 邻域内,且q是核心点则p-q直接密度可达。
密度可达:若有一个点的序列q0、q1、…qk,对任意qi~qi-1是直接密度可达的 ,则称从q0到qk密度可达,这实际上是直接密度可达的“传播”。
密度相连:若从某核心点p出发,点q和点k都是密度可达的 ,则称点q和点k是密度相连的。
边界点:属于某一个类的非核心点,不能发展下线了
噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的
相当于某个点距离有点远,可以理解成是没有用的干扰点
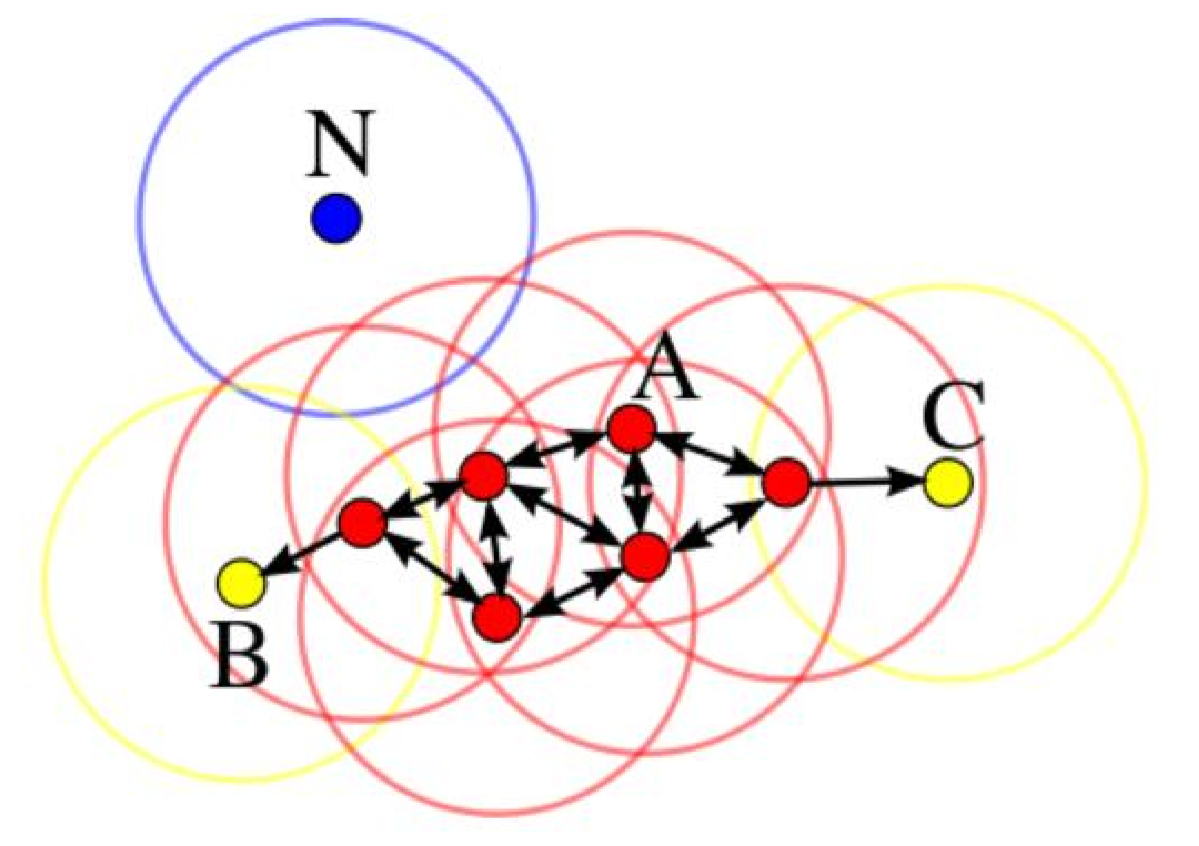
上图中,点的分类分别是:
A——核心对象
B,C——边界点:因为这两个点不能再发展下线了
N——离群点:因为这个点所代表的这一片区域再也找不到其他点了,离群了
参数D:所需数据集
参数ϵ:指定的半径
MinPts:密度阈值
for(数据集D中每个对象p) do
if (p已经归入某个簇或标记为噪声) then
continue;
else
检查对象p的Eps邻域 NEps(p) ;
if (NEps(p)包含的对象数小于MinPts) then
标记对象p为边界点或噪声点;
else
标记对象p为核心点,并建立新簇C, 并将p邻域内所有点加入C
for (NEps(p)中所有尚未被处理的对象q) do
检查其Eps邻域NEps(q),若NEps(q)包含至少MinPts个对象,则将NEps(q)中未归入任何一个簇的对象加入C;
end for
end if
end if
end for
来自:https://blog.csdn.net/zhouxianen1987/article/details/68945844
半径ϵ:可以根据K距离来设定:找突变点 K距离:给定数据集P={p(i); i=0,1,…n},计算点P(i)到集合D的子集S中所有点 之间的距离,距离按照从小到大的顺序排序,d(k)就被称为k-距离
MinPts:k-距离中k的值,一般取的小一些,多次尝试
不需要指定簇的个数,算法会分配好的
可以发现任意形状的簇,这是比K-MEANS强大很多的地方
擅长找到离群点,算法会检测出来的
我们提供两个参数就够了,不用过度费脑
高维度的数据处理还是有些困难
参数难以选择(参数对结果影响很大)
在sklearn中运行效率比较慢(可以采用数据削减策略)
对唐宇迪老师的机器学习教程进行笔记整理
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。