社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
曾几何时,我还记得老大曾经给我这么一个任务:
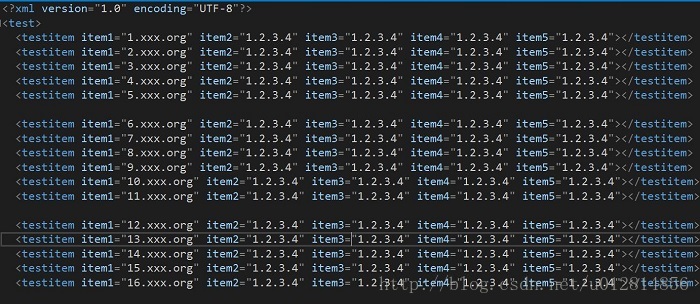
从一个 100 来行的 xml 文件中将所有 testxml 行中的 item5 信息提取出来
这个 xml 文件的结构大概如下图所示(敏感信息我已经替换成了其他字符)。
当时的我还过于稚嫩,刚接触 Python 未能使用 Python 解决这个问题。正好现在学习了 Scrapy 爬虫框架,想到里面的 lxml 和 css 的 selector 编写方式,正好可以用来解析 xml 文件,也正好可以完成这个任务,遂想要把之前那个任务再完成一遍。
使用了 Scrapy 的 selector 之后,这个问题变得简单多了,使用 xpath 或者 css 均可,代码如下:
from scrapy.selector import Selector
# 1. 读取 xml 文件信息
xml = ''
with open('test.xml') as f:
xml = f.read()
# 2. 使用 scrapy.selector.Selector 解析 xml
sel = Selector(text=xml)
# 3. 解析需要的数据到 record.txt 中
with open('record.txt', 'w') as f:
for line in sel.xpath('//testitem'):
f.write('item1 = ' + line.xpath('./@item1').extract_first()
+ ' item5 = ' + line.xpath('./@item5').extract_first()
+ 'rn')
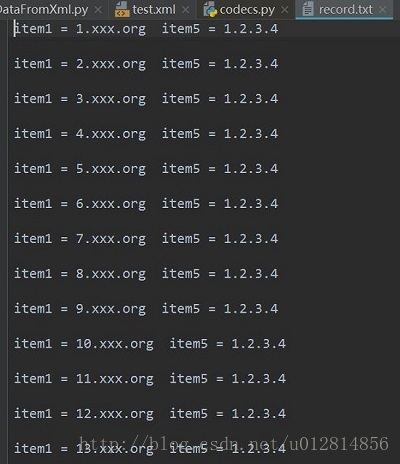
运行之后,生成的 record.txt 文件内容如下:
使用 scrapy.selector 强大的解析功能,也可以在其他方面大大提高我们的工作效率呢。
ps: 想要获取本博客实验代码的同学,可以点击这里
wangying2016/collectDataFromXML
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!