社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
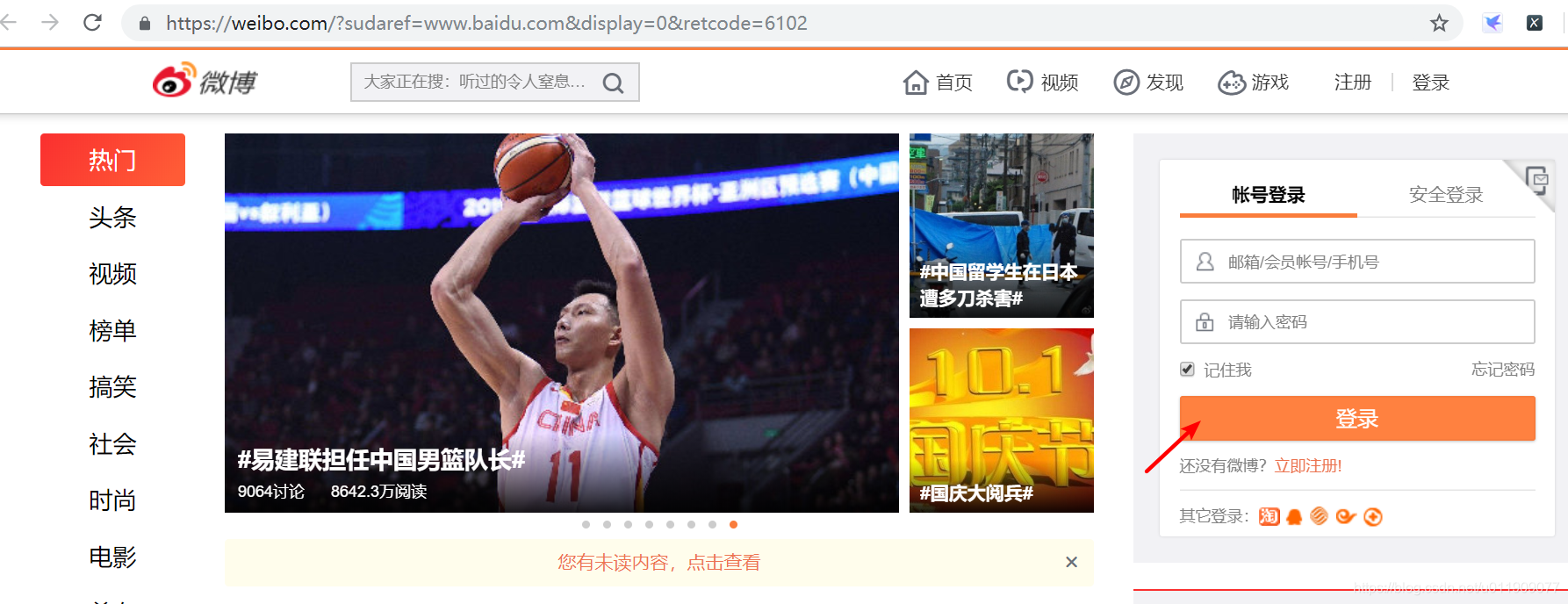
前两天看了一篇大佬模拟登录淘宝的blog感觉收获颇多,刚好这两天比较闲,研究了下微博的登录方式
琢磨了两天找到了两种方式
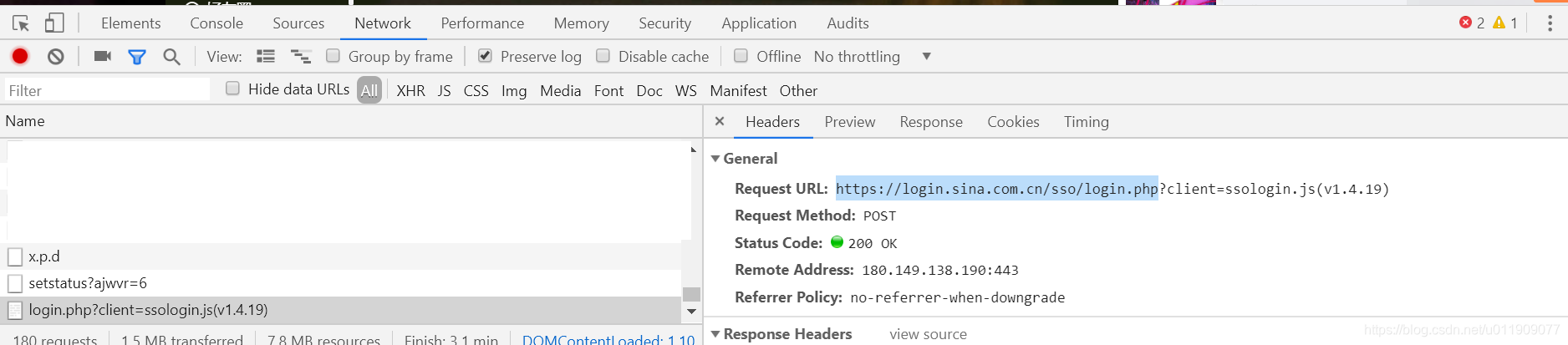
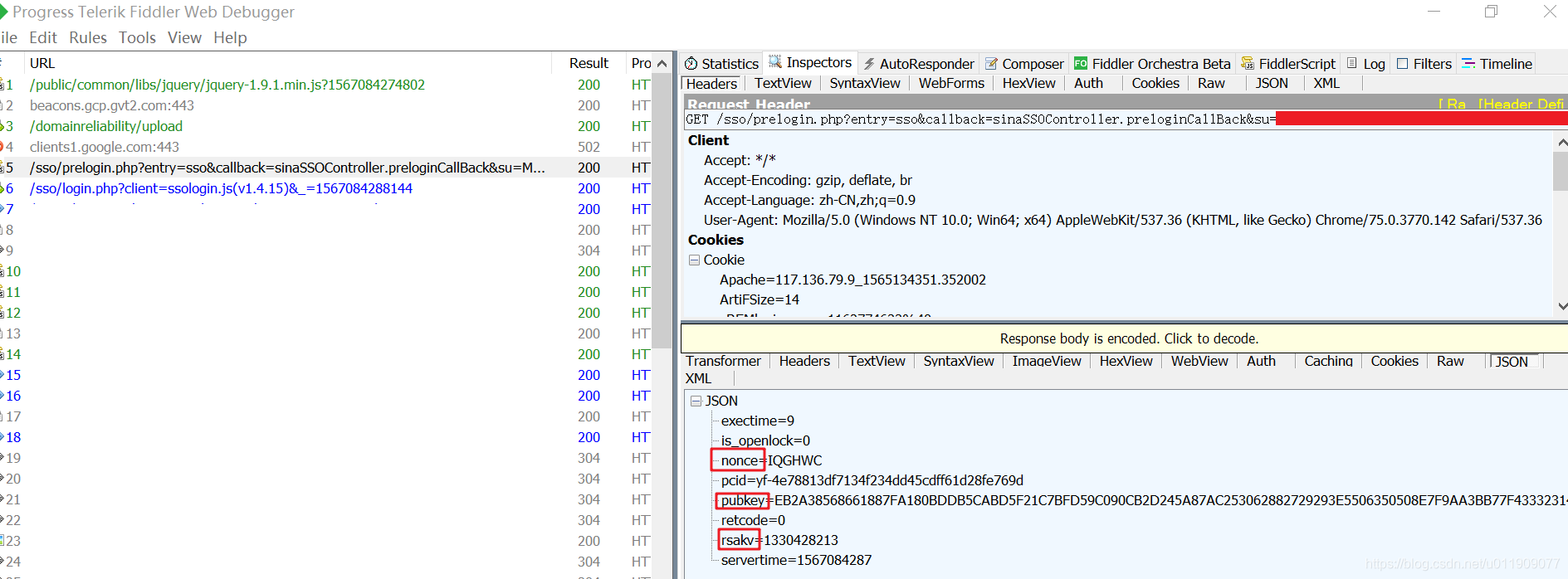
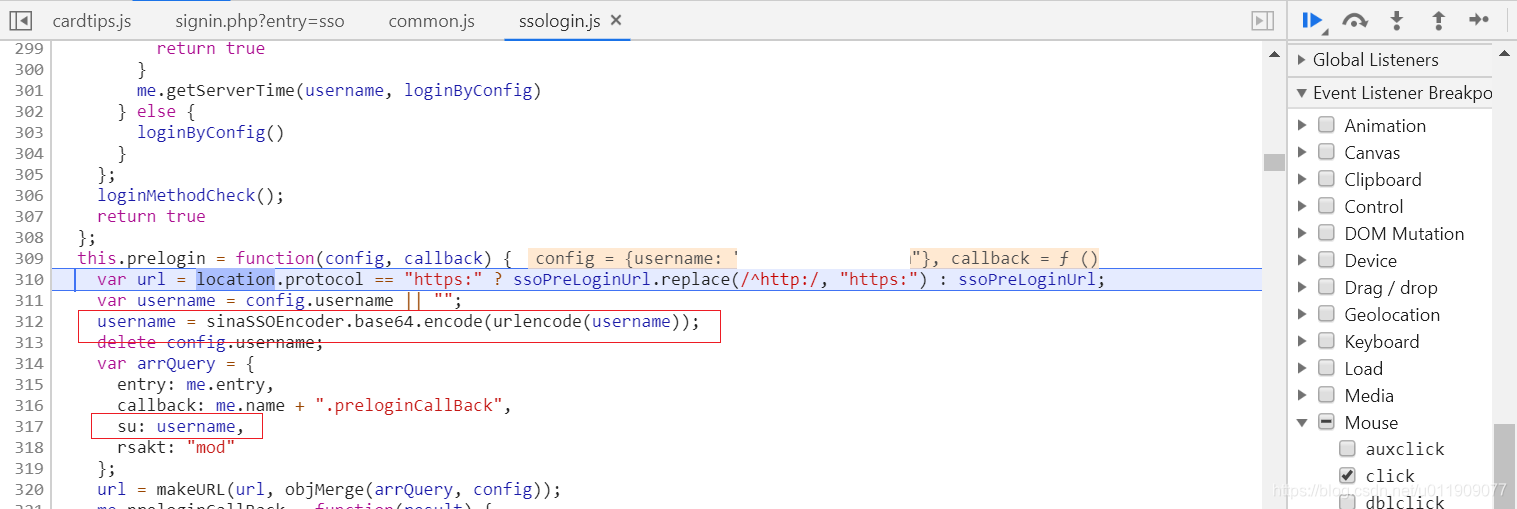
1.向’https://login.sina.com.cn/sso/prelogin.php’发送预登录的get请求
2.向’https://login.sina.com.cn/sso/login.php’发送正式登录的post请求
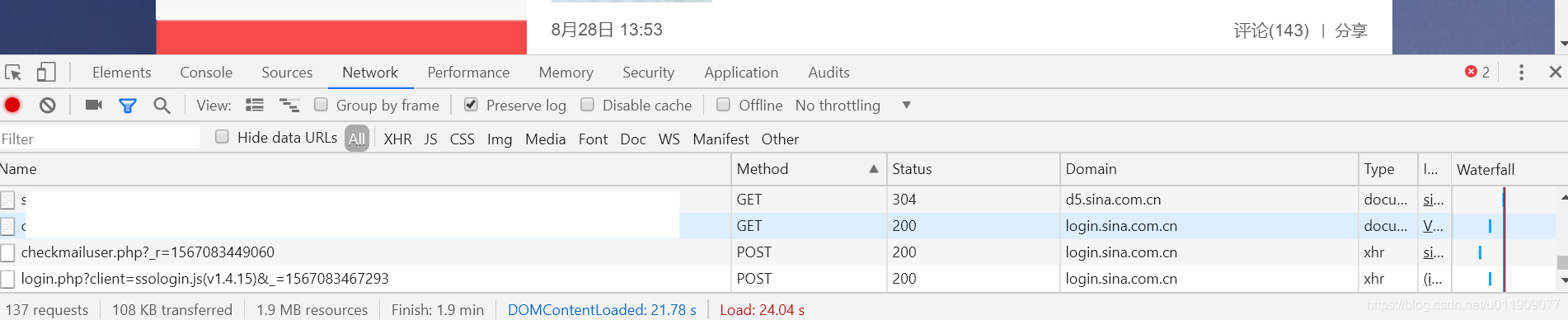
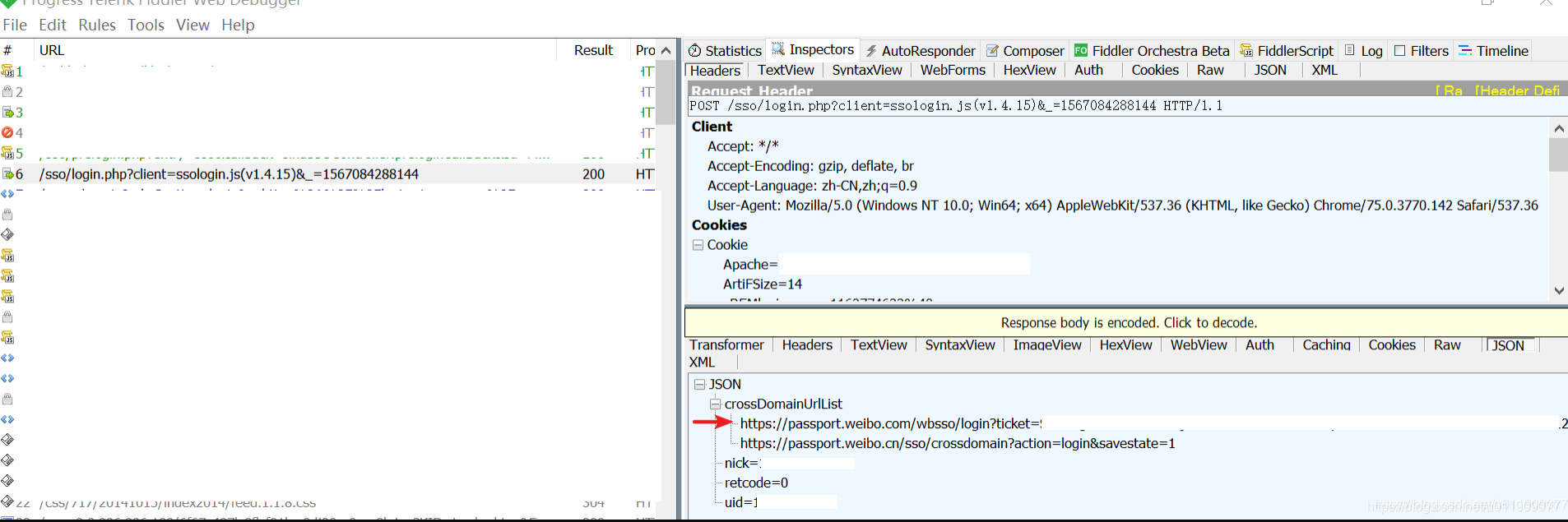
3.向’https://passport.weibo.com/wbsso/login?ticket=*****&ssosavestate=*****’发送get请求(****根据上一个请求响应而定,后面会说)
三步完成后进入登录状态,可以访问个人主页和做其他事情了~
这里是思路,可以直接跳过看代码
from time import time
import requests
import base64
from urllib import parse
import re
import json
import rsa
import binascii
from lxml import etree
import os
# 建立一个会话对象,使cookie可以跨请求保留
SESSION = requests.session()
# cookies保留再本地的路径
COOKIES_FILE_PATH = 'weibo_login_cookies.json'
class WeiboLogin:
def __init__(self, username, password):
"""
需传入两个参数
:param username:用户名
:param password: 密码
"""
# 预登录url
self.pre_login_url = 'https://login.sina.com.cn/sso/prelogin.php'
# 正式登录url
self.login_url = 'https://login.sina.com.cn/sso/login.php'
# 个人主页url
self.mysina_url = 'http://my.sina.com.cn/'
# 微博用户名
self.username = username
# 微博密码
self.password = password
def per_login(self):
"""
预登录,此步骤仅验证用户名
:return:正式登录时要用上的5个参数值,su,nonce,servertime,pubkey,rsakv
"""
# su参数是用户名经过url编码和base64转码后的字符串
su = base64.b64encode(parse.quote(username).encode('utf-8')).decode('utf-8')
per_login_params = {
'entry': "account",
'callback': "sinaSSOController.preloginCallBack",
'su': su,
'rsakt': "mod",
'client': "ssologin.js(v1.4.15)",
'_': int(time()*1000),
}
try:
response = SESSION.get(self.pre_login_url, params=per_login_params)
# 响应异常时,抛出异常信息
response.raise_for_status()
except Exception as error:
print('预登录失败,原因:')
raise error
# 返回值是非标注格式的json字符串
response_json = re.search(r'((.*?))', response.text).group(1)
response_dict = json.loads(response_json)
# 提取出需要的其他4个参数
nonce = response_dict['nonce']
servertime = response_dict['servertime']
pubkey = response_dict['pubkey']
rsakv = response_dict['rsakv']
if nonce:
print('预登录成功, nonce参数为: %s' % nonce)
return su, nonce, servertime, pubkey, rsakv
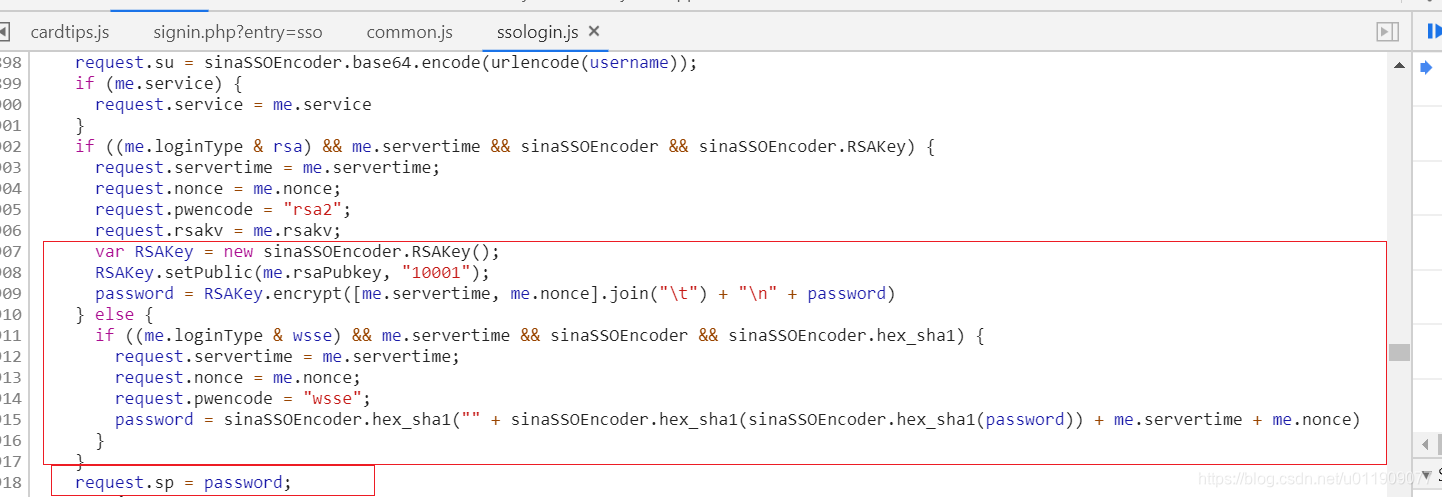
def encrypt_password(self, pubkey, servertime, nonce):
"""
构造sp参数,sp参数是经过rsa加密的密码
:params pubkey, servertime, nonce: 预登录取得
:return: sp参数
"""
# 接收方(微博服务器)提供的pubkey,转16进制
rsa_publickey = int(pubkey, 16)
# 加载公钥,传入参数n和参数e(关于参数的解释可参考这篇大佬文章 https://blog.csdn.net/chengqiuming/article/details/70139817)
key = rsa.PublicKey(rsa_publickey, int('10001', 16))
# 加载明文m
message = str(servertime) + 't' + nonce + 'n' + password
# 加密成密文c,有c = m^e mod n(解密的时候是还原m, m = c^d mod n, 其中d为私钥)
encrypt_message = rsa.encrypt(message.encode('utf-8'), key)
# 16进制密文
sp = binascii.b2a_hex(encrypt_message).decode('utf-8')
return sp
def login(self):
"""
构造form data发送post请求,正式登录
:return: 登录成功的cookies
"""
# 加载本地cookies文件,加载成功则跳过登录,直接访问个人主页
if self.load_cookies():
return True
# cookies过期,正常进行登录
login_params = {
'client': "ssologin.js(v1.4.15)",
'_': int(time() * 1000),
}
# 预登录,返回5个参数
su, nonce, servertime, pubkey, rsakv = self.per_login()
# sp参数
sp = self.encrypt_password(pubkey, servertime, nonce)
# 构造表单
login_form_data = {
'entry': "account",
'gateway': "1",
'from': "null",
'savestate': "30",
'useticket': "0",
'vsnf': "1",
'su': su,
'service': "account",
'servertime': servertime,
'nonce': nonce,
'pwencode': "rsa2",
'rsakv': rsakv,
'sp': sp,
'sr': "1280*720",
'encoding': "UTF-8",
'cdult': "3",
'domain': "sina.com.cn",
'prelt': "170",
'returntype': "TEXT",
}
login_url = 'https://login.sina.com.cn/sso/login.php'
try:
# 登录请求返回一个json文件,里面有三个url,验证第一个url必须跳转,否则无法成功访问个人主页
response = SESSION.post(login_url, params=login_params, data=login_form_data)
response.raise_for_status()
except Exception as error:
print('登陆失败,原因:')
raise error
# 做一次必要的跳转,跳转的目的是补全cookies信息
cross_url = re.search(r'"(https:.*?)"', response.text).group(1)
cross_url = re.sub(r'\', '', re.sub(r'\', '', cross_url))
if cross_url:
print('登录成功,正在跳转%s' % cross_url)
# 发送get请求,使session自动更新cookies
SESSION.get(cross_url)
# 访问个人主页,成功则保存cookies至本地
if self.verify_login_status():
self.serialize_cookies()
def verify_login_status(self):
"""
访问个人主页,验证登录状态
"""
try:
response = SESSION.get(self.mysina_url)
response.raise_for_status()
except Exception as error:
print('获取个人主页失败,原因: ')
raise error
# 不明原因返回了部分乱码,所以取content再decode
html = etree.HTML(response.content.decode('utf-8'))
nickname = html.xpath('//div[@class="me_w"]//p[@class="me_name"]/text()')[0]
if nickname:
print('已处于登录状态!当前处于[%s]的个人主页' % nickname)
return True
else:
raise RuntimeError('获取微博昵称失败!response: %s' % response.content.decode('utf-8'))
def load_cookies(self):
"""
检查本地cookies是否可用
"""
# 判断cookies文件是否存在
if not os.path.exists(COOKIES_FILE_PATH):
return False
# 加载本地cookies
SESSION.cookies = self.deserialize_cookies()
# 判断cookies是否过期
try:
self.verify_login_status()
except Exception as error:
os.remove(COOKIES_FILE_PATH)
print('本地cookies文件过期,正在删除...')
return False
print('加载新浪微博登录cookies成功!')
return True
def serialize_cookies(self):
"""
保存cookies至本地
"""
cookies_dict = requests.utils.dict_from_cookiejar(SESSION.cookies)
with open(COOKIES_FILE_PATH, 'w+', encoding='utf-8') as file:
json.dump(cookies_dict, file)
print('保存cookies文件成功!文件名: %s' % COOKIES_FILE_PATH)
def deserialize_cookies(self):
"""
读取本地cookies
"""
with open(COOKIES_FILE_PATH, 'r+', encoding='utf-8') as file:
cookies_dict = json.load(file)
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
return cookies
if __name__ == '__main__':
# 这里输入用户名
username = '*************'
# 这里输入登录密码
password = '*************'
wb_login = WeiboLogin(username, password)
wb_login.login()
程序会在根目录下创建登录成功的cookies文件
如果本地cookies未创建&已过期,运行结果如下:
如果本地cookies未过期,运行结果如下:
selenium常规操作,
1.定位用户名、密码输入框,定位登录按钮
2.输入相应数据,点击登录按钮
3.登录成功(如果在非常用ip登录会弹出图形验证码,代码会报错,用第三方API识别验证码可破)
from selenium import webdriver
# chrome driver所在路径
driver_path = r'C:Users12517PycharmProjectschromedriver.exe'
username = '*************'
password = '*************'
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 如果切换为非常用ip,页面会自动刷新出图形验证码(常用ip直接登陆即可成功)
driver = webdriver.Chrome(executable_path=driver_path, options=options)
driver.get('https://login.sina.com.cn/signup/signin.php')
username_tag = driver.find_element_by_xpath('//input[@id="username"]')
password_tag = driver.find_element_by_xpath('//input[@id="password"]')
login_btn = driver.find_element_by_xpath('//input[@class="W_btn_a btn_34px"]')
username_tag.send_keys(username)
password_tag.send_keys(password)
login_btn.click()
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
