社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前一篇Kafka框架设计来自英文原文(Kafka Architecture Design)的翻译及整理文章,很有借鉴性,本文是从一个企业使用Kafka框架的角度来记录及整理的Kafka框架的技术资料,也很有借鉴价值,为了便于阅读与分享,我将其整理一篇Blog。本文内容目录摘要如下:
1)apache kafka消息服务
2)kafka在zookeeper中存储结构3)kafka log4j配置
4)kafka replication设计机制5)apache kafka监控系列-监控指标
6)kafka.common.ConsumerRebalanceFailedException异常解决办法7)kafak安装与使用
8)apache kafka中server.properties配置文件参数说明9)apache kafka的consumer初始化时获取不到消息
10)Kafka Producer处理逻辑11)apache kafka源代码工程环境搭建(IDEA)
12)apache kafka监控系列-KafkaOffsetMonitor
13)Kafka Controller设计机制
14)Kafka性能测试报告(虚拟机版)15)apache kafka监控系列-kafka-web-console
16)apache kafka迁移与扩容工具用法17)kafka LeaderNotAvailableException
18)apache kafka jmx监控指标参数19)apache kafka性能测试命令使用和构建kafka-perf
20)apache kafka源码构建打包
21)Apache kafka客户端开发-java
22) kafka broker内部架构
23)apache kafka源码分析走读-kafka整体结构分析24)apache kafka源码分析走读-Producer分析
25)apache kafka性能优化架构分析26)apache kafka源码分析走读-server端网络架构分析
27)apache kafka源码分析走读-ZookeeperConsumerConnector分析28)kafka的ZkUtils类的java版本部分代码
29)kafka & mafka client开发与实践30) kafka文件系统设计那些事
31)kafka的ZookeeperConsumer实现
详细内容如下所示:
1)apache kafka消息服务
http://kafka.apache.org/documentation.html
消息队列分类:
点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。这里要注意:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
背景介绍
kafka是最初由Linkedin公司开发,使用Scala语言编写,Kafka是一个分布式、分区的、多副本的、多订阅者的日志系统(分布式MQ系统),可以用于web/nginx日志,搜索日志,监控日志,访问日志等等。
kafka目前支持多种客户端语言:java,python,c++,php等等。
kafka名词解释和工作方式:
kafka(MQ)要实现从producer到consumer之间的可靠的消息传送和分发。传统的MQ系统通常都是通过broker和consumer间的确认(ack)机制实现的,并在broker保存消息分发的状态。
即使这样一致性也是很难保证的(参考原文)。kafka的做法是由consumer自己保存状态,也不要任何确认。这样虽然consumer负担更重,但其实更灵活了。
因为不管consumer上任何原因导致需要重新处理消息,都可以再次从broker获得。
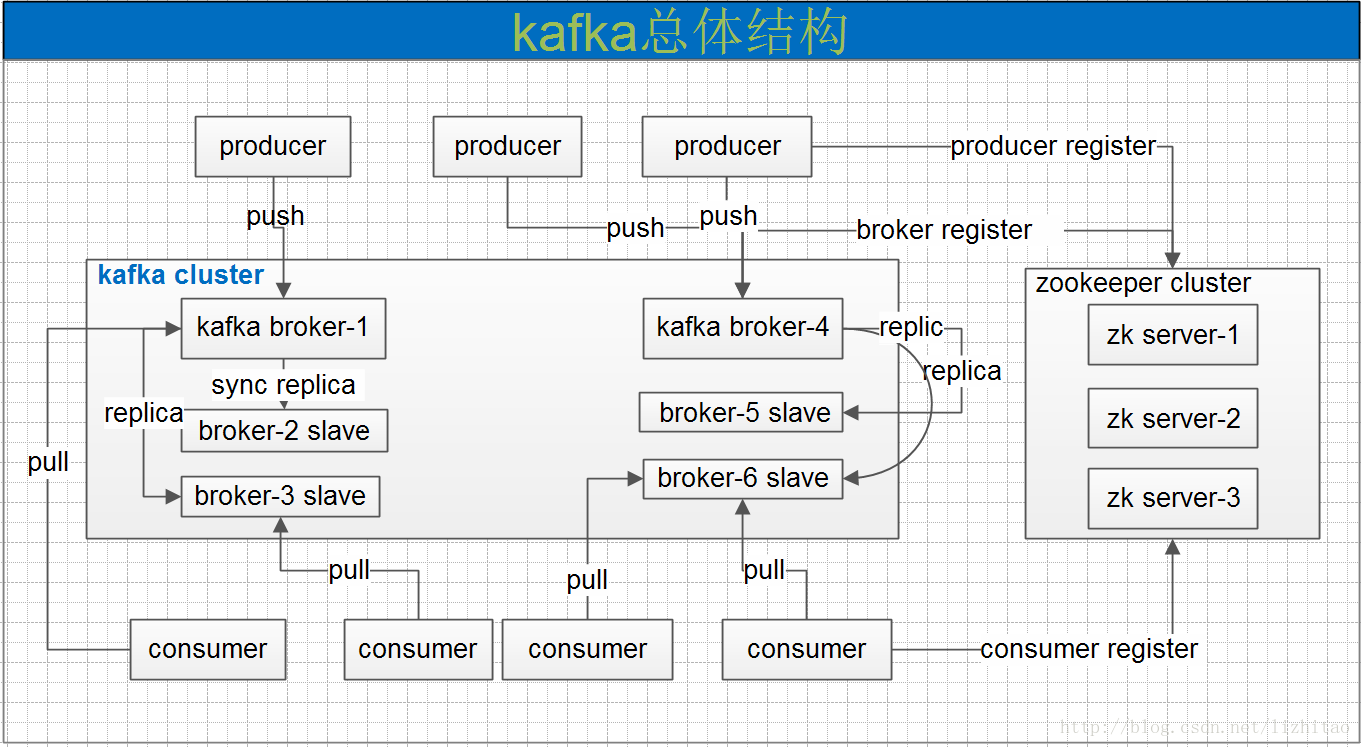
kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。
而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除broker时,各broker间仍能自动实现负载均衡。
高吞吐量是其核心设计之一。
由于kafka broker会持久化数据,broker没有cahce压力,因此,consumer比较适合采取pull的方式消费数据,具体特别如下:
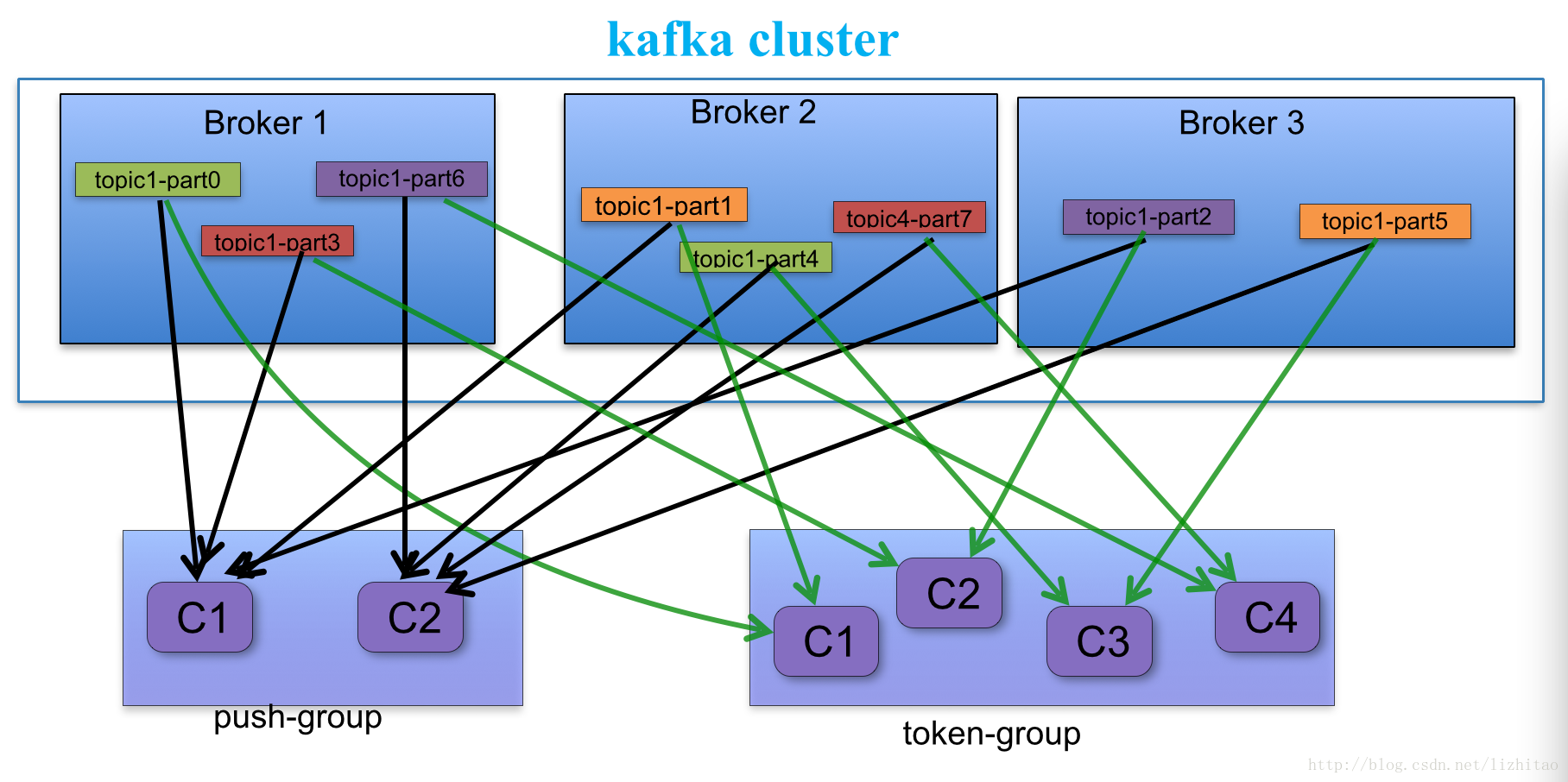
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.对于Topic中的一条特定的消息,
只会被订阅此Topic的每个group中的一个consumer消费,此消息不会发送给一个group的多个consumer;那么一个group中所有的consumer将会交错的消费整个Topic.
如果所有的consumer都具有相同的group,这种情况和JMS queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息.
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的.事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的.
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效,
那么其消费的partitions将会有其他consumer自动接管.kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,
否则将意味着某些consumer将无法得到消息.
kafka集群中的任何一个broker,都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"
等信息(请参看zookeeper中的节点信息).当producer获取到metadata信心之后, producer将会和Topic下所有partition leader保持socket连接;
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层".事实上,消息被路由到哪个partition上,有producer客户端决定.
比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的.
在producer端的配置文件中,开发者可以指定partition路由的方式.
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据consumer.id排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
kafka中,replication策略是基于partition,而不是topic;kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);
备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower就像一个"consumer",
消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.
当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它,这种同步策略,就要求follower和leader之间必须具有良好的网络环境.
即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(备注:不同于其他分布式存储,比如hbase需要"多数派"存活才行)
kafka判定一个follower存活与否的条件有2个:
1) follower需要和zookeeper保持良好的链接
2) 它必须能够及时的跟进leader,不能落后太多.
如果同时满足上述2个条件,那么leader就认为此follower是"活跃的".如果一个follower失效(server失效)或者落后太多,
leader将会把它从同步列表中移除[备注:如果此replicas落后太多,它将会继续从leader中fetch数据,直到足够up-to-date,
然后再次加入到同步列表中;kafka不会更换replicas宿主!因为"同步列表"中replicas需要足够快,这样才能保证producer发布消息时接受到ACK的延迟较小。
当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.kafka中leader选举并没有采用"投票多数派"的算法,
因为这种算法对于"网络稳定性"/"投票参与者数量"等条件有较高的要求,而且kafka集群的设计,还需要容忍N-1个replicas失效.对于kafka而言,
每个partition中所有的replicas信息都可以在zookeeper中获得,那么选举leader将是一件非常简单的事情.选择follower时需要兼顾一个问题,
就是新leader server上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.
在选举新leader,需要考虑到"负载均衡",partition leader较少的broker将会更有可能成为新的leader.
在整几个集群中,只要有一个replicas存活,那么此partition都可以继续接受读写操作.
1) Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
2) Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
3) Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息.
目前我已经在虚拟机上做了性能测试。
测试环境:cpu: 双核 内存 :2GB 硬盘:60GB
|
测试指标
|
性能相关说明
|
结论
|
|---|---|---|
| 消息堆积压力测试 |
单个kafka broker节点测试,启动一个kafka broker和Producer,Producer不断向broker发送数据, 直到broker堆积数据为18GB为止(停止Producer运行)。启动Consumer,不间断从broker获取数据, 直到全部数据读取完成为止,最后查看Producer==Consumer数据,没有出现卡死或broker不响应现象 |
数据大量堆积不会出现broker卡死 或不响应现象 |
| 生产者速率 | 1.200byte/msg,4w/s左右。2.1KB/msg,1w/s左右 | 性能上是完全满足要求,其性能主要由磁盘决定 |
| 消费者速率 | 1.200byte/msg,4w/s左右。2.1KB/msg,1w/s左右 | 性能上是完全满足要求,其性能主要由磁盘决定 |
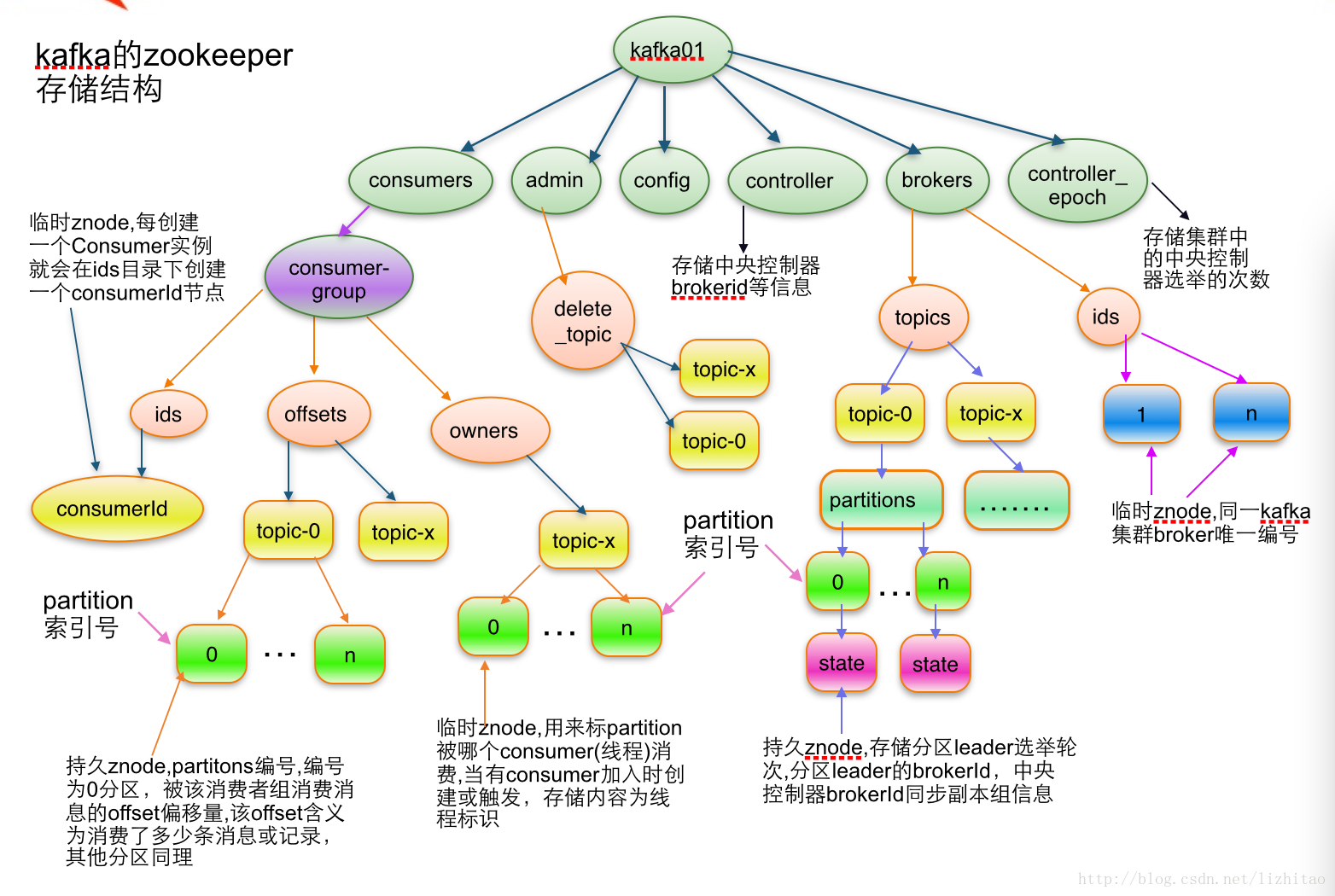
/brokers/topics/[topic] :
存储某个topic的partitions所有分配信息
Schema:"version": "版本编号目前固定为数字1", "partitions": { "partitionId编号": [ 同步副本组brokerId列表 ], "partitionId编号": [ 同步副本组brokerId列表 ], ....... } } Example:
{
"version": 1, "partitions": { "0": [1, 2], "1": [2, 1], "2": [1, 2], } }
说明:紫红色为patitions编号,蓝色为同步副本组brokerId列表
|
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
Schema:"controller_epoch": 表示kafka集群中的中央控制器选举次数, "leader": 表示该partition选举leader的brokerId, "version": 版本编号默认为1, "leader_epoch": 该partition leader选举次数, "isr": [同步副本组brokerId列表] } Example:"controller_epoch": 1, "leader": 2, "version": 1, "leader_epoch": 0, "isr": [2, 1] } |
每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时znode(EPHEMERAL)
Schema:"jmx_port": jmx端口号, "timestamp": kafka broker初始启动时的时间戳, "host": 主机名或ip地址, "version": 版本编号默认为1, "port": kafka broker的服务端端口号,由server.properties中参数port确定 } Example:"jmx_port": 6061,
"timestamp":"1403061899859"
"version": 1, "host": "192.168.1.148", "port": 9092 } |
/controller_epoch -> int (epoch)
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
/controller -> int (broker id of the controller) 存储center controller中央控制器所在kafka broker的信息
Schema:"version": 版本编号默认为1, "brokerid": kafka集群中broker唯一编号, "timestamp": kafka broker中央控制器变更时的时间戳 } Example:"version": 1, "brokerid": 3, "timestamp": "1403061802981" } |
a.每个consumer客户端被创建时,会向zookeeper注册自己的信息;
b.此作用主要是为了"负载均衡".
c.同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer。
d.Consumer Group中的每个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer;
e.一个Consumer group的多个consumer的所有线程依次有序地消费一个topic的所有partitions,如果Consumer group中所有consumer总线程大于partitions数量,则会出现空闲情况;举例说明:kafka集群中创建一个topic为report-log 4 partitions 索引编号为0,1,2,3假如有目前有三个消费者node:注意-->一个consumer中一个消费线程可以消费一个或多个partition.如果每个consumer创建一个consumer thread线程,各个node消费情况如下,node1消费索引编号为0,1分区,node2费索引编号为2,node3费索引编号为3总结:如果每个consumer创建2个consumer thread线程,各个node消费情况如下(是从consumer node先后启动状态来确定的),node1消费索引编号为0,1分区;node2费索引编号为2,3;node3为空闲状态
从以上可知,Consumer Group中各个consumer是根据先后启动的顺序有序消费一个topic的所有partitions的。如果Consumer Group中所有consumer的总线程数大于partitions数量,则可能consumer thread或consumer会出现空闲状态。
Consumer均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据(consumer.id + '-'+ thread序号)排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
/consumers/[groupId]/ids/[consumerIdString]
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!