转载:https://tech.meituan.com/about-desk-io.html
顺序读写 VS 随机读写
机械硬盘的连续读写性能很好,但随机读写性能很差,原因有两点:
- 随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上;
- 顺序读可以充分利用文件系统的预读特性,直接从Page Cache内存读取数据,不用进入磁盘;
磁盘性能指标
IOPS
每秒能够处理的IO请求数,随机读写能力的衡量指标,可以推算出磁盘的IOPS = 1000ms / (Tseek + Trotation + Transfer),如果忽略数据传输时间,理论上可以计算出随机读写最大的IOPS。常见磁盘的随机读写最大IOPS为:
- 7200rpm的磁盘 IOPS = 76 IOPS
- 10000rpm的磁盘IOPS = 111 IOPS
- 15000rpm的磁盘IOPS = 166 IOPS
吞吐量
每秒读写磁盘的数据量,顺序读写能力的衡量指标。它主要取决于磁盘阵列的架构,通道的大小以及磁盘的个数。不同的磁盘阵列存在不同的架构,但他们都有自己的内部带宽,一般情况下,内部带宽都设计足够充足,不会存在瓶颈。磁盘阵列与服务器之间的数据通道对吞吐量影响很大,比如一个2Gbps的光纤通道,其所能支撑的最大流量仅为250MB/s。最后,当前面的瓶颈都不再存在时,硬盘越多的情况下吞吐量越大。
Page Cache
IO调用处理分层
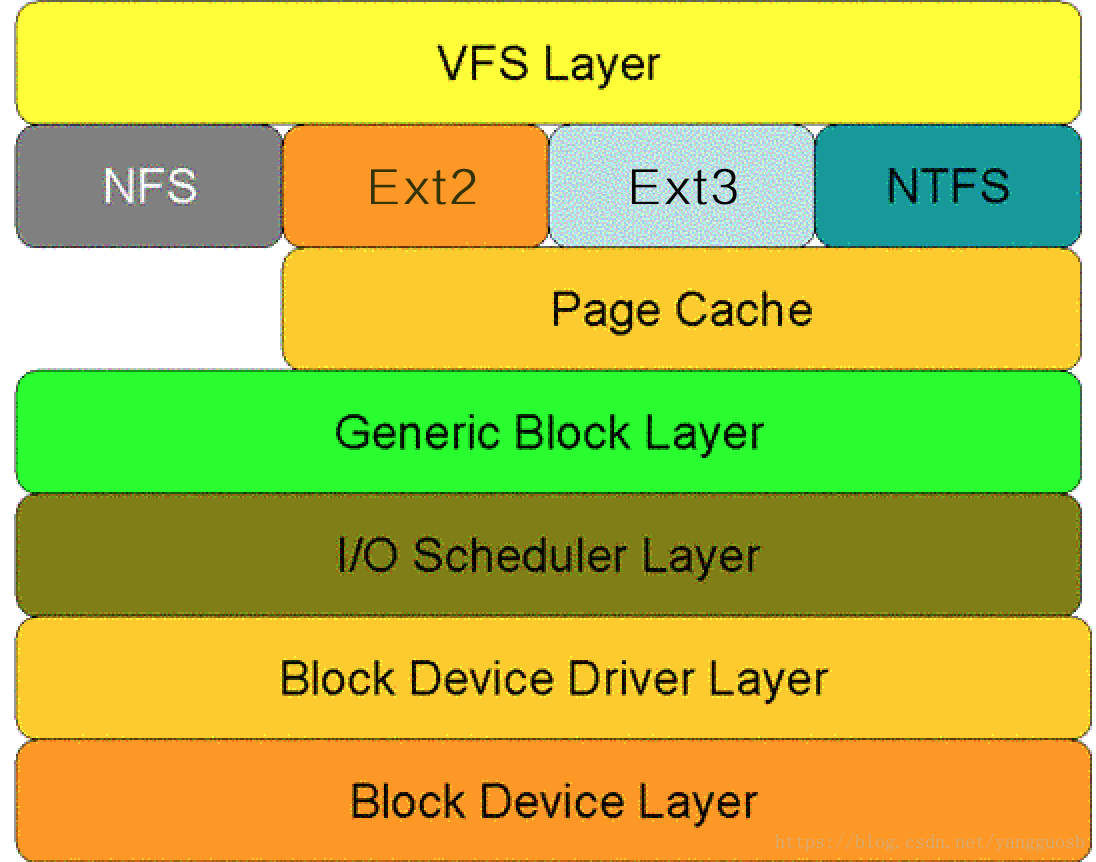
对于一次磁盘IO请求,自上而下的顺序依次为:虚拟文件系统层(VFS Layer),具体的文件系统层(例如Ext2),Cache层(Page Cache Layer)、通用块层(Generic Block Layer)、I/O调度层(I/O Scheduler Layer)、块设备驱动层(Block Device Driver Layer),物理块设备层(Block Device Layer)。
预读和回写
引入Page Cache的目的是为了提高Linux操作系统对磁盘访问的性能,通过预读和回写实现。
- 预读是指读取磁盘数据时,周围数据会同时被载入内存,利用了局部性原理。具体过程是:对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(通常是三个页面),这时的预读称为同步预读。对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的页中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读页的大小扩大一倍,此时预读过程是异步的,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可,这时的预读称为异步预读。任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读的页面中,这时继续进行异步预读;第二种情况是所请求的页面处于预读页面之外,这时系统就要进行同步预读。
- 回写是通过暂时将数据存在Cache里,然后由操作系统统一异步写到磁盘中。通过这种异步的数据I/O模式解决了程序中的计算速度和数据存储速度不匹配的鸿沟,减少了访问底层存储介质的次数,使存储系统的性能大大提高。
回写触发时机
下面两种情况下,脏页会被写回到磁盘:
- 在空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存;
- 当脏页在内存中驻留超过一定的阈值时,内核必须将超时的脏页写会磁盘,以确保脏页不会无限期地驻留在内存中。
回写停止时机
回写开始后,会持续写数据,直到满足以下两个条件:
- 已经有指定的最小数目的页被写回到磁盘;
- 空闲内存页已经回升,超过了阈值。
回写缺点
- 数据丢失,如果发生断电或宕机等情况,Page Cache中数据会丢失;
- 回写期间读I/O性能很差;
IO调度层
作用:按照设定的I/O调度算法,通过合并和排序I/O请求队列中的请求,以此大大降低所需的磁盘寻道时间,从而提高整体I/O性能。
常见调度算法
- Noop算法:最简单的I/O调度算法。该算法仅适当合并用户请求,并不排序请求。新的请求通常被插在调度队列的开头或末尾,下一个要处理的请求总是队列中的第一个请求。这种算法是为不需要寻道的块设备设计的,如SSD。因为其他三个算法的优化是基于缩短寻道时间的,而SSD硬盘没有所谓的寻道时间且I/O响应时间非常短。RocketMQ使用此算法提升读性能。
- CFQ算法:算法的主要目标是在触发I/O请求的所有进程中确保磁盘I/O带宽的公平分配。算法使用许多个排序队列,存放了不同进程发出的请求。通过散列将同一个进程发出的请求插入同一个队列中。采用轮询方式扫描队列,从第一个非空队列开始,依次调度不同队列中特定个数(公平)的请求,然后将这些请求移动到调度队列的末尾。
- Deadline算法:算法引入了两个排队队列分别包含读请求和写请求,两个最后期限队列包含相同的读和写请求。本质就是一个超时定时器,当请求被传给电梯算法时开始计时。一旦最后期限队列中的超时时间已到,就想请求移至调度队列末尾。Deadline算法避免了电梯调度策略(为了减少寻道时间,会优先处理与上一个请求相近的请求)带来的对某个请求忽略很长一段时间的可能。
- AS算法:AS算法本质上依据局部性原理,预测进程发出的读请求与刚被调度的请求在磁盘上可能是“近邻”。算法统计每个进程I/O操作信息,当刚刚调度了由某个进程的一个读请求之后,算法马上检查排序队列中的下一个请求是否来自同一个进程。如果是,立即调度下一个请求。否则,查看关于该进程的统计信息,如果确定进程p可能很快发出另一个读请求,那么就延迟一小段时间。
基于磁盘I/O特性设计的技巧
现实:在进行系统设计时,良好的读性能和写性能往往不可兼得。
策略:在许多常见的开源系统中都是优先在保证写性能的前提下来优化读性能。
写操作性能优化
核心思想:顺序写。
- 追加写。
- 批量。
- 磁盘空间预分配。创建文件时为文件分配固定大小的空间,让文件尽可能的占用连续的磁盘扇区,减少后续写入的磁盘寻道(seek)开销。
读操作性能优化
操作系统的优化手段是Page Cache和IO调度算法,应用层常见的优化手段有:
- 大块读取。增加每次访问时读写的数据量,减少文件访问次数;
- 索引+分段。Kafka把一个大文件分成多个小文件段,每个小文件段以偏移量命名,通过多个小文件段,不仅可以使用二分搜索法很快定位消息,同时也容易定期清除或删除已经消费完的文件,减少磁盘占用。为了进一步提高查找效率,Kafka为每个分段后的数据建立了索引文件,并通过索引文件稀疏存储来降低元数据占用大小。一个段中数据对应结构如下图所示:

版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/yangguosb/article/details/80363864
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

