社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
一、命令行操作
1.查看当前服务器中的所有topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
2.创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --replication-factor 3 --partitions 1 --topic first
参数说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3.删除topic
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic first
需要server.properties中设置delete.topic.enable = true 否则只是标记删除或者直接重启
4.发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic first
在输入需要发送的内容
5.消费消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic first
--from-beginning:会吧first主题中以往所有的数据都读出来。更具业务场景选择是否增加该配置。
6.查看某个Topic的详情
bin/kafka-topics.sh --zookeeper loaclhost:2181 --describe --topic first
二、生产者写入流程
1.写入方式
Producer采用推(push)模式将消息发送到broker,每条消息都被追加(append)到分区(partition)中,属于顺序写磁盘(顺序写磁盘效率比随机写要高,保障kafka吞吐率,在读取使用的时候读取速度也会更快)。
2.分区(partition)
kafka集群有多个消息代理服务器(broker-server)组成,发布到Kafka集群的每条消息都有一个类别,用主题(topic)来表示。通常,不同应用产生不同类型的数据,可以设置不同的主题。一个主题一般会有多个消息的订阅者,当生产者发布消息到某个主题时,订阅了这个主题的消费者都可以接收到生产者写入的新消息。
kafka集群为每一个主题维护了分布式的分区(partition)日志文件,物理意义上可以把主题(topic)看作进行了分区的日志文件(partition log)。主题的每个分区都是一个有序的、不可变的记录序列,新的消息会不断追加到日志中。分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,叫做偏移量(offset),这个偏移量能够唯一的定位当前分区的每一条消息。
消息发送时都被发送到一个topic,本质就是一个目录,而topic是由一些partitionLogs(分区日志)组成,其组织结构如下。
图中的topic有3个分区,每个分区的偏移量都从0开始,不同分区之间的偏移量都是独立的,不会互相影响。
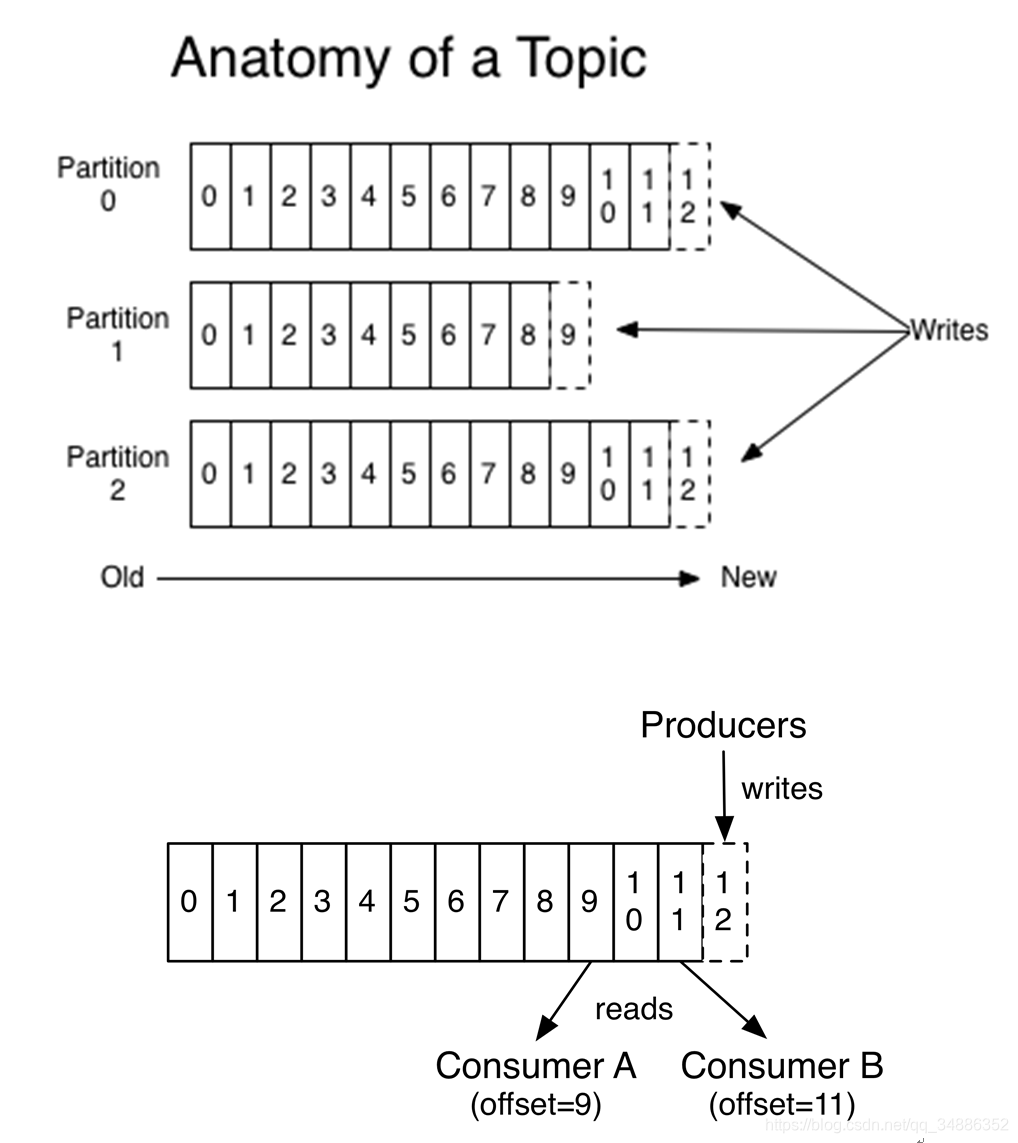
每个partition中的消息都是有序的,生产的消息被不断追加到partition log上,其中的每个消息都被赋予了一个唯一的offset值。
发布到kafka主题的每条消息包括键值和时间戳。消息到达服务器端的指定分区后,都会被分配一个自增的偏移量。原始的消息内容和分配的偏移量以及其他一些元数据信息最后都会存储到分区日志文件中。消息的键也可以不用设置,这个情况下消息会均衡地分布到不同的分区。
1.分区原因
1.方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic有可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了。
2.可以提高并发,因为可以以partition为单位读写了。
传统消息系统在服务端保持消息的顺序,如果有多个消息者消息同一个消息队列,服务端会以消费存储的顺序依次发送给消费者。但由于消息是异步发送给消费者的,消息到达消费者的顺序可能是无序的,这就意味着在并行消费时,传统消息系统无法很好地保证消息被顺序处理。虽然我们可以设置一个专用的消费者值消费一个队列,以此来解决消息顺序的问题,但是这就使得消费处理无法真正执行。
kafka比传统消息系统有更强的顺序性保证,它使用主题的分区作为消息处理的并行单元。kafka以分区作为最小的粒度,将每个分区分配给消费者组中不同的而且是唯一的消费者,并确保一个分区只属于一个消费者,即这个消费者就是这个分区的唯一读取线程。那么只要分区的消息是有序的,消费者处理的消息顺序就有保证。每个主题有多个分区,不同的消费者处理不同的分区,所以kafka不仅保证了消息的有序性,也做到了消费者的负载均衡。
3.副本(Replication)
同一个partition可能会有多个replication(对应server.properties配置中的default.replication.factor=N)。没有replication的情况下,一旦broker宕机,其中所有partition的数据都不可被消费,同时producer也不能再将数据存于其上的partition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader中复制数据。
4.写入流程

producer先从zookeeper的“/brokers/.../state”节点找到该partition的leader
producer将消息发送给该leader
leader将消息写入本地log
followers从leader pull消息,写入本地log后向leader发送ACK
leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit的offset)并向producer发送ACK。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
