随着大规模并行分布处理系统,特别是网络工作站集群的广泛应用。如何采取有效的调度策略来平衡各节点的负载,从而提高整个系统资源的利用率,已成为人们的研究热点。
集群具有可扩展性、 高可用性、高性能、高性价比等优点,作为存储区域网的存储设备具有天生的优势。随着PC机的发展,硬盘的价格越来越低,其存储容量越来越大,每台PC机也可配置多块硬盘,且可扩充能力极高,作为集群中的节点管理也相当方便,并具有一定的计算能力。如何采取有效的调度策略来平衡各节点的负载,从而提高整个系统资源的利用率,成为研究的重点。
1 负载均衡的目标
- 要保持所有处理机处于忙碌状态,而不是保证他们平分负载
- 提供最短的平均任务响应时间
- 具有一定的自适应性,能适于变化的负载
- 是可靠的,避免负载的轻重跳跃,避免处理机抖动,减少不必要的通讯开销
2 影响分布式系统性能的因素
主要有这些因素影响着分布式系统的性能:网络延迟、数据通信效能、CU处理能力、任务的分割、无法预算处理时间、任务的颠簸等等。
我们在寻求分布式计算调度算法时,就是有针对性的以解决这些问题为目的,从各个角度,不同侧面,利用一种或者集中方法结合起来的形式,从而达到最优解,使得系统效率相对最高。
3 几种基本的调度算法
获得网络负载均衡有几个基本的方法,这些方法可以结合使用,形成更高级的算法,以下是几种基本的方法:
3.1 轮转法
轮转算法是所有算法中最简单也最容易实现的一种方法,轮转法简单地在一串节点中线性轮转,平衡器将新请求发给节点表中的下一个节点。如此连续下去。
这个算法在DNS域名轮询中被广泛使用。但是简单应用轮转法DNS转换,可能造成持续访问同一节点,从而干扰正常的网络负载平衡,使网络平衡系统无法高效工作。轮转法典型适用于集群中所有节点的处理能力和性能均相同的情况,在实际应用中,一般将它与其他简单方法联合使用时比较有效。
3.2 加权法
加权算法根据节点的优先级或权值来分配负载。权值是基于各节点能力的假设或估计值。加权方法智能与其它方法结合使用,是它们一个很好的补充。
3.3 散列法
散列法也叫哈希法(Hash),通过单射不可逆的Hash函数,按照某种规则将网络请求发往集群节点。与简单加权法相似。
3.4 最少连接法
针对TCP连接进行在最少连接法中,管理节点纪录目前所有活跃连接,把下一个新的请求发给当前含有最少连接数的节点。
缺陷是某些应用层会话要消耗更多的系统资源,尽管集群中连接数平衡了,但是处理量可能差别很大,连接数无法反映出真实的应用负载。
3.5 最低缺失法
在最低缺失法中,管理节点长期纪录到各节点的请求情况,把下个请求发给历史上处理请求最少的节点。与最少连接法不同的是,最低缺失记录过去的连接数而不是当前的连接数。
3.6 最快响应法
管理节点记录自身到每一个集群节点的网络响应时间,并将下一个到达的连接请求分配给响应时间最短的节点。在大多数基于LAN的集群中,最快响应算法工作的并不是很好,大多数与以太网连接的现代系统,有部分负载时,可在1ms或更短时间内响应,这使得这种方法没有意义。
4 几种高级的调度算法
4.1 基于遗传算法的分布式任务调度策略
- 符号串表示
符号串表示必须能够唯一地表示搜索空间中的所有搜索节点。对于多处理器调度问题,一个有效的调度必须满足下列条件:
(一)调度任务之间的先后关系;
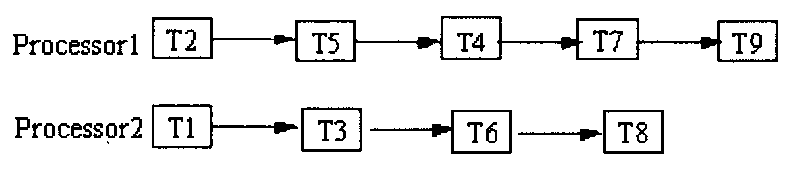
(二)完整性和唯一性条件(每一个任务都在调度中出现且出现一次)。监控任务表是满足这种条件的可行方法,每个表对应于一个处理器上运行的监控任务子集。一个调度的描述如下图所示。
- 起始群体
在遗传算法的每一次迭代中,必须维持一个符号串的群体。起始的符号串群体通常是随机生成的。假定以下条件:在调度中每个处理器上的任务都按高度升序排列于表中。这样可以保证低高度的任务优先执行,保证算法的有效性。有时高度排序条件并不是充分条件,在此前提下,高度的定义被修正以减小这种情况出现的可能性。
- 适应度函数
对于MSP,适应度函数需要考虑吞吐量、完成时间以及处理器的使用等因素。而对上面问题,适应度函数仅取决于调度的完成时间。一个调度完成时间定义为任务图中所有任务执行完成所用的时间,这个使时间最小的调度就是最优调度。
- 遗传操作
(一)交叉
如果交叉截点的选取使得每个交叉截点两侧任务的高度都是不同的,并且交叉截点前面最近任务的高度都是一样的,则新生成的符号串一定有效。
(二)繁殖
繁殖操作通过从旧的群体中选取适应度值最大的符号串来构成新的群体。选取的准则为:具有较高适应度值的符号串应有较多的机会在下一代中存活。这是因为“好的”的符号串具有较高的适应度值并应被保留到下一代。
(三)突变
对于MSP,突变由随机变换两个高度相同的任务来实现突变算法如下:
1、随机选取一个任务T1;
2、比较高度,找出符号串中高度相同的任务T2;
3、交换任务,通过在调度中交换任务T1和T2来生成一个新的符号串;
4、突变操作用突变概率来控制,这一算法在一个符号串上施用突变操作以生成一个新的符号串。
(5)完整的遗传算法
问题求解的完整遗传算法如下:
Genetic-Algorithm()
{
调用调度生成算法N次并将生成的符号串存入Group;
Do
{
计算Group中每个符号串的适应度值;
调用繁殖算法;
令BESTSIRING为Group中适应值最大的符号串;
For(i=1 ; i<=GroupNum/2; i++)
{
从Group中取出两个符号串并以概率P¬1调用交叉操作;
if(交叉操作发生)
将生成的符号串加入Temp;
else
将原符号串加入Temp;
}
对Temp中的每一个符号串,以概率P2调用突变算法;
if(突变操作发生)
将新生成的符号串加入NewGroup;
else
将原符号串加入NewGroup;
用BESTSIRNG取代Group中适应度值最小的符号串;
}
while(算法尚未满足收敛准则);
}
4.2 蚁群算法求解分布式系统任务分配问题
- 基本蚁群算法
Dorigo 首先提出了蚁群算法。蚁群算法是模仿真实的蚁群行为而提出的一种模拟进化算法。蚂蚁个体之间是通过一种称之为信息素的物质进行信息传递,从而能相互协作,完成复杂的任务。蚂蚁在运动过程中,能够在它所经过的路径上留下信息素,而且蚂蚁在运动过程中能够感知这种物质的存在及其强度,并以此指导自己的运动方向,蚂蚁倾向于朝着该物质强度高的方向移动。因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。蚂蚁个体之间就是通过这种信息素的交流,搜索到一条从蚁巢到食物源的可能的较短路径。
蚁群算法的步骤可简要地表述为:①设置所有参数,信息素痕迹初始化;②每只蚂蚁根据状态转移规则建立一个完整的解,状态转移规则主要取决于信息素和启发式信息;③更新信息素。这3 个过程重复直到满足终止条件。
- 蚁群算法求解任务分配问题
在用于任务分配问题求解的蚁群算法中,每一个人工蚂蚁是具有下述特性的智能体:
当它选择把任务指派给处理器时,它会在连接上留下一种称为痕迹的物质(等价于信息素);
它以一定的概率为一指定任务选择处理器,该概率为在连接, 上的启发式信息和的痕迹量的函数;
在构造一个完整的解时,已经被处理的任务被加以禁止,所有分配到处理器的任务的KOP需求如果超过该处理器的能力限制,则该处理器也被禁止,如此重复直到所有的任务都已被处理器处理为止。
该启发式算法使用由只蚂蚁组成的群体来一步步地进行解的构造。每只蚂蚁代表建立解的一个独立过程,这个过程分两步来完成:①蚂蚁选择将要被分配的任务;②对每个已经选择的任务,分配处理器执行它。若干蚂蚁过程之间通过信息素值来交换信息,合作求解并不断优化。所有任务均被处理器处理完意味着蚂蚁建立解过程的结束。
4.3 一种自适应的分布式调度策略
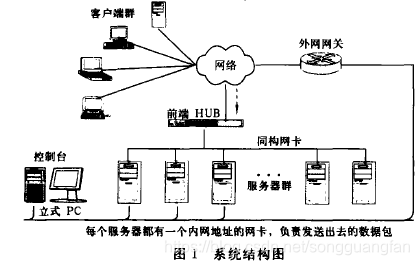
- 总体结构图
系统结构如图1所示,前端的共享介质型集线器(前端HUB)作为集群的单一人口点,借助于集线器的共享介质特征,使褥所有访间集群的数据包都能被内部节点的同构网卡接收并传往它们各自的数据链路层。集群内部所有服务节点都配备两块网卡,上端网卡绑定一个对外的公共IP地址(VIP),以实现集群的单一IP映像;每个下端网卡配备一个内部1P地址,负贵和集群管理控制台进行交互和发送数据包到外部网关。控制台节点机负贵管理和监视各个服务节点的工作状态。
- 调度原理
该系统的调度原理如图2所示。其基本思想是在连接请求建立的初期,根据各个Server节点负载状况对TCP连接的第二次握手信号进行一定的延时,使得当前负载最轻的节点总是最
先响应客户端的连接请求。通常根据连接请求内容和服务类型的不同,各个Server节点的工作负载往往表现出不均衡性,而且这种不均衡性是难以进免的,也是随时间不断变化的。本策略正是利用这种不均衡性,根据负载的动态变化来自动进行调度,在各个Server节点间达到一种自适应的平衡。而且不摇要节点间相互通讯,因此实现简单,开销更小。
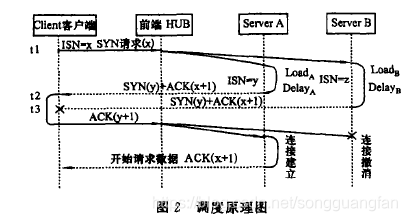
其工作原理描述如下:
- t1时刻,客户端访间集群服务器,给VIP发SYN请求,准备建立连接;
- SYN包到达前端HUB后,以广播的形式发送到各个Server节点的同构网卡;
- 驻留在各个Server上的调度处理模块收到SYN请求后,根据自身的负载情况(由负载收集模块给出)对该请求进行一定的延时.负载重的Server节点延时大,负载轻的Server节点延时小,使得负载较轻的Server节点先发第二次握手信号(即SYN十ACK包)。如在LoadA<LoadB的情况下DelayA<DelayB,于是A的回应先发出;
- t2时刻,Load较小的ServerA节点的应答信息达到客户端,于是客户端给VIP发送第三次握手信号;
- t3时刻,Load较大的ServerB节点的应答信息到达客户端,由于t3>t2,客户端已经收到A的应答,TCP协议栈会自动丢弃B的应答;
- 第三次握手信号经由前端HUB到达各个Server节点,包过滤模块检查该应答信号的ACK序列号是否与自身的初始序列号一致,即判断NACK和(NISN+1)是否相等,如果相等,则允许通过;否则向上层TCP协议栈发送一个RST数据包以撤销该连接。图示中ServerA将建立起连接,ServerB
将撤销连接,从而选择当前负载较轻的ServerA为新来的请求服务。
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/songguangfan/article/details/90052843
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

