社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
解析PDF常用组件(PdfBox、iText、Tika等)都无法将表格数据解析成有规则的格式。解析后格式基本是TEXT、XHTML等导致处理表格数据变的非常复杂,基本需要全枚举+正则才能处理个70-80%。最近看到Python可以解析表格于是尝试了一下,不过要想让数据可用,还存在很多问题待解决。
PDF文件截图
Tika解析PDF文件
1、TEXT格式
Tika tika = new Tika();
tika.setMaxStringLength(100 * 1024 * 1024);
try (InputStream stream = new FileInputStream(new File("600060_2018_zB.pdf"))) {
return tika.parseToString(stream);
}
Text格式解析结果
2、XHTML格式
ContentHandler handler = new ToXMLContentHandler();
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
try (InputStream stream = new FileInputStream(new File("600060_2018_zB.pdf"))) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
XHTML格式解析结果
Python解析表格
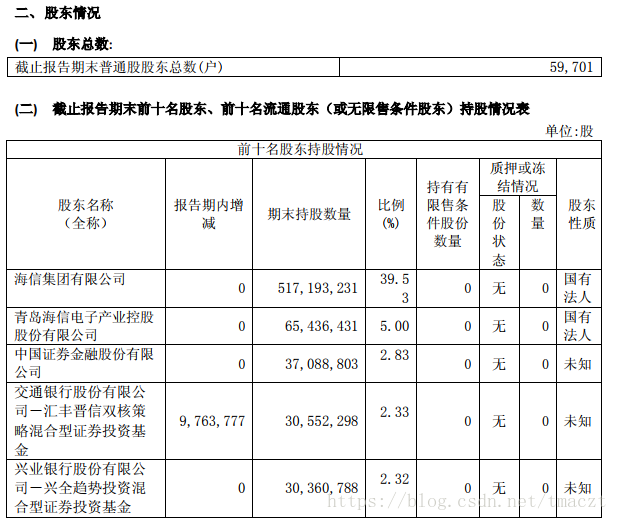
1、前十名股东表格原始数组
2、处理过的财务指标
3、处理过单位后的快报数据
暂时还不通用存在一些问题,如换行、表头、每列占用单元格个数不统一、分页等。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!