社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在文章开始前,复习机器学习算法有一段时间了,私下有一些不成熟的想法,就先闲聊个五毛钱的,把自己的想法分享出来,一方面提醒自己思考,另一方面以供大家指正。
个人认为,机器学习最优的入门路径应该是这样的:
首先,对于机器学习乃至人工智能的大的框架有一个认识以及自己的体会,这一步免不了要有大量的阅读量及思考作为铺垫。
然后,才可以从机器学习角度出发,学习其最基本的原理,抛弃现在火热的框架,从理论角度出发,这一个过程学习的不仅仅是对其公式的应用理解还有对应的数据的操作,以及更重要的对数据的理解。以围绕相关博客和书籍辅助以对应的讲解视频,以每一个基础算法为基本单位,同时体会自己的学习路径。
最后,在自己的学习路径基础上,精细化自己所学到的知识,包括对于已经学习到的算法的扩展,这一步就可以大量练习热门的机器学习框架。最好可以和自身结合,不一定要开辟自己的项目,要思考自己学习到的机器学习算法可以应用到什么地方,一方面可以给自己找到继续学习的热情,另一方面也可能有意外的收获。
在记录我的学习路径之前我还是提一下喽,非常欢迎志同道合的同学加入我们的交流群,可以讨论相关的所有内容,我也会把包括我文章资源在内的所有资源尽数分享给大家,一起学习一起进步,欢迎进群~~~
ps :以后文章中提到的书和相关信息我都会分享在群里哦

源码与数据:
链接: https://pan.baidu.com/s/1IsQQJaUeEkRUZ4cHy_ZtcA 提取码: xk8j
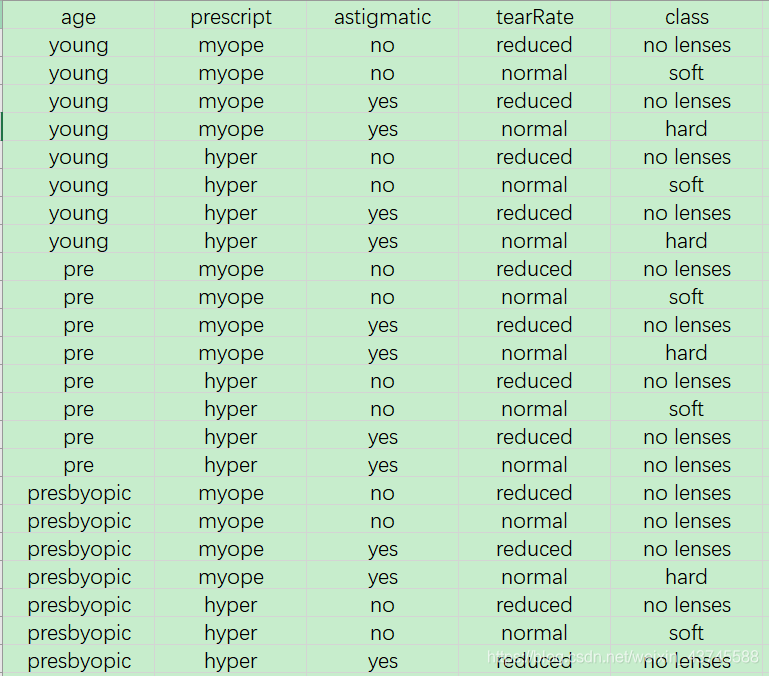
通过有关信息判断患者需要的隐形眼镜的类型。
隐形眼镜数据集是非常著名的数据集,它包含很多换着眼部状态的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)。也就是对应的上一篇文章的(放贷或者不放贷)。
数据一共有24组数据,数据的Labels依次是age、prescript、astigmatic、tearRate、class,也就是第一列是年龄,第二列是症状,第三列是是否散光,第四列是眼泪数量,第五列是最终的分类标签。
我们就是根据这四列信息来做出隐形眼镜class的判断的。
在代码之前必须安装Graphviz
Graphviz不能使用pip进行安装,我们需要手动安装,我将其和数据也放在了源码之中。
安装后记住自己的安装路径,因为还需要设置对应的环境变量。添加完环境变量就可以正常运行程序,注意这里需要的导入的库,如果没有需要自行添加。
show me the code
# -*- coding: UTF-8 -*-
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# from sklearn.externals.six import StringIO
from six import StringIO
from sklearn import tree
import pandas as pd
import numpy as np
import pydotplus
'''
注释:从with open 到dataframe都是为了将数据转化为dataframe格式,认为可以直接使用pandas读取数据
'''
if __name__ == '__main__':
with open('lenses.txt', 'r') as fr: #加载文件
lenses = [inst.strip().split('t') for inst in fr.readlines()] #处理文件
lenses_target = [] #提取每组数据的类别,保存在列表里
for each in lenses:
lenses_target.append(each[-1])
# print(lenses_target)
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签
lenses_list = [] #保存lenses数据的临时列表
lenses_dict = {} #保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels: #提取信息,生成字典
for each in lenses:
print(lensesLabels.index(each_label))
print(each[lensesLabels.index(each_label)])
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
# print(lenses_dict) #打印字典信息
lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame
# print(lenses_pd) #打印pandas.DataFrame
le = LabelEncoder() #创建LabelEncoder()对象,用于序列化
'''
注意:这里的序列化就是将对应序列下的不同值用从0开始的实数代替,将字符串转换为增量值,同样的转换方式还有one-hot编码
'''
print(lenses_pd)
lenses_pd.to_csv('p.csv')
for col in lenses_pd.columns: #序列化
lenses_pd[col] = le.fit_transform(lenses_pd[col])
print(lenses_pd) #打印编码信息
lenses_pd.to_csv('a.csv')
clf = tree.DecisionTreeClassifier(max_depth = 4)
# 创建DecisionTreeClassifier()类
# print(lenses_pd)
# print(lenses_target)lensen_target对应的是最终的判断情况,也就是隐形眼镜是哪一种
print(lenses_pd.values.tolist())
#注意使用values也是一种dataframe转换为list的方法
clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
dot_data = StringIO()
print(lenses_pd.keys())
print(clf.classes_)#判断的最终分类类别,也就是眼睛的种类
tree.export_graphviz(clf, out_file = dot_data, #绘制决策树
feature_names = lenses_pd.keys(),
class_names = clf.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf") #保存绘制好的决策树,以PDF的形式存储。
print(clf.predict([[0,1,1,0]]))
仔细体会其中所包含的信息,一定会有所收获。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
