社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
打开智联招聘网页,搜索数据分析师,出来很多招聘岗位,限定全国范围,从下图看出有12354个职位,一共有90页,看最后一页职位已经只是和数据分析师相关而已。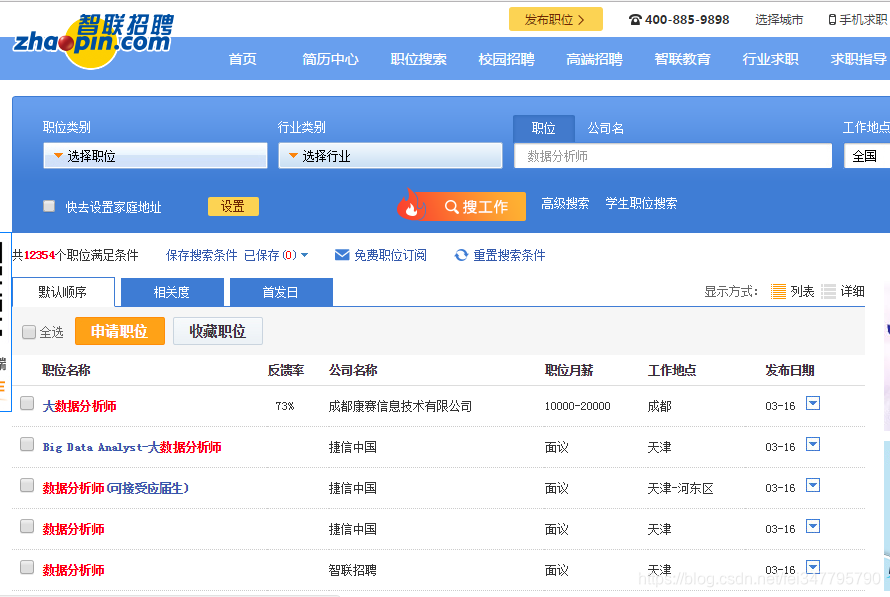
看看最后一页搜索结果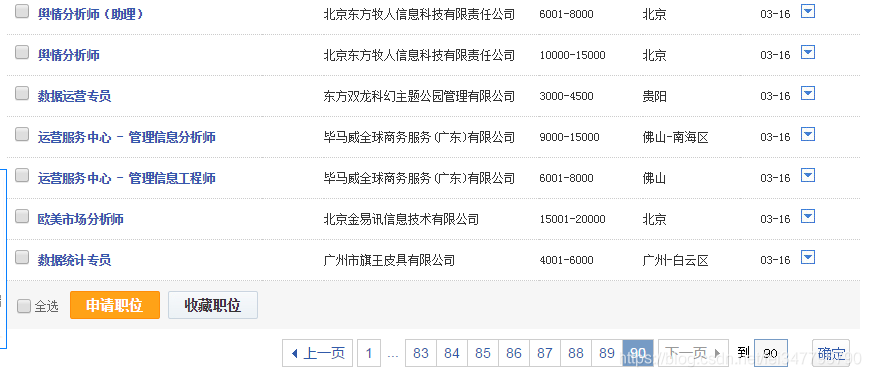
PS:小技巧,在页面下部跳转页面输入一个很大的数字,比如10000可以跳到最后一页。
右键查看网页源代码,CTRL+F搜索关键要爬取信息,如下图红框内容
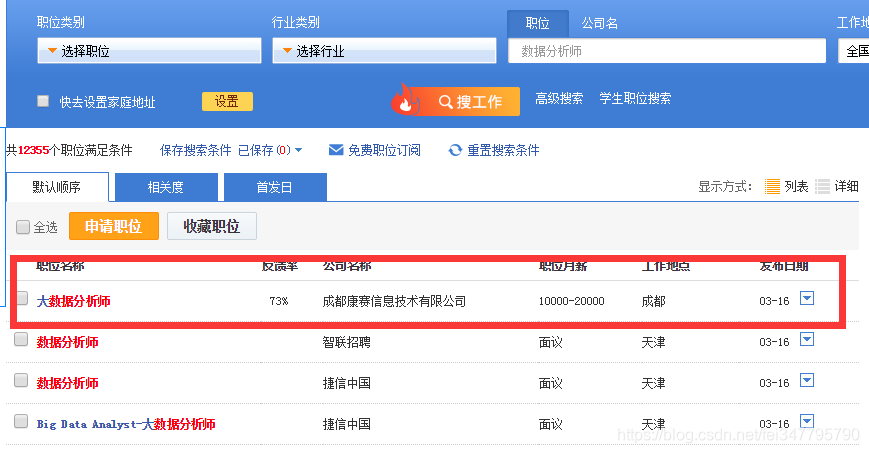
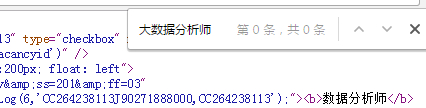
页面红框上的 大数据分析师 字样竟然搜不到!!!
可能藏在json文件里了
那就再试试,搜一下 数据分析师

大和后面的数据分析中间有个标签,这是什么意思,吓得我赶紧百度了一下
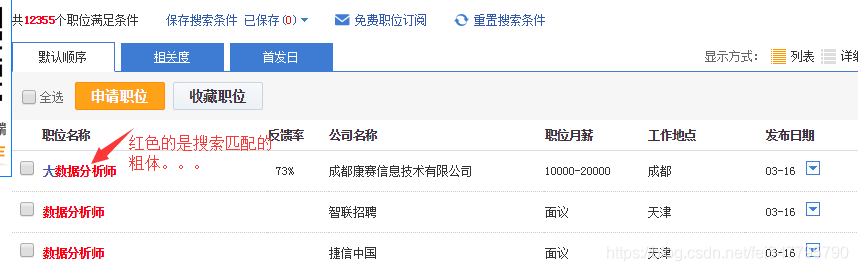
继续观察源代码,发现我想要的信息都在这(下图红框),看来不用抓包分析辣~
开始写爬虫程序
打开我最爱的pycharm(直译为py的魅力)不信你百度看
from urllib import request
import re
import os,glob
import xlwt
导入一些模块
PS:
1.request模块主要是会自动解码来自服务器的内容
2.re模块是写正则表达式提取信息用
3.glob是一个文件操作相关模块,用它可以查找符合自己目的的文件,类似于Windows下的文件搜索
4.os模块提供了一个统一的操作系统接口函数
5.xlwt模块读写excel文件需要
book = xlwt.Workbook()
sheet = book.add_sheet('sheet', cell_overwrite_ok=True)
path = 'D:\work'
os.chdir(path)
以上是设置路径和为最后数据写入excel文件做铺垫
result11=[]
result21=[]
result31=[]
result41=[]
result51=[]
建立五个空的列表放我要抓的最终信息
经尝试网站是gbk编码,我实际操作中发现和上图红框内中文有关,所以encode和decode总是报错,我想找个不含中文的同样网址,试试F12吧
在网页按下F12,刷新网页,观察到请求的url是下图红框中的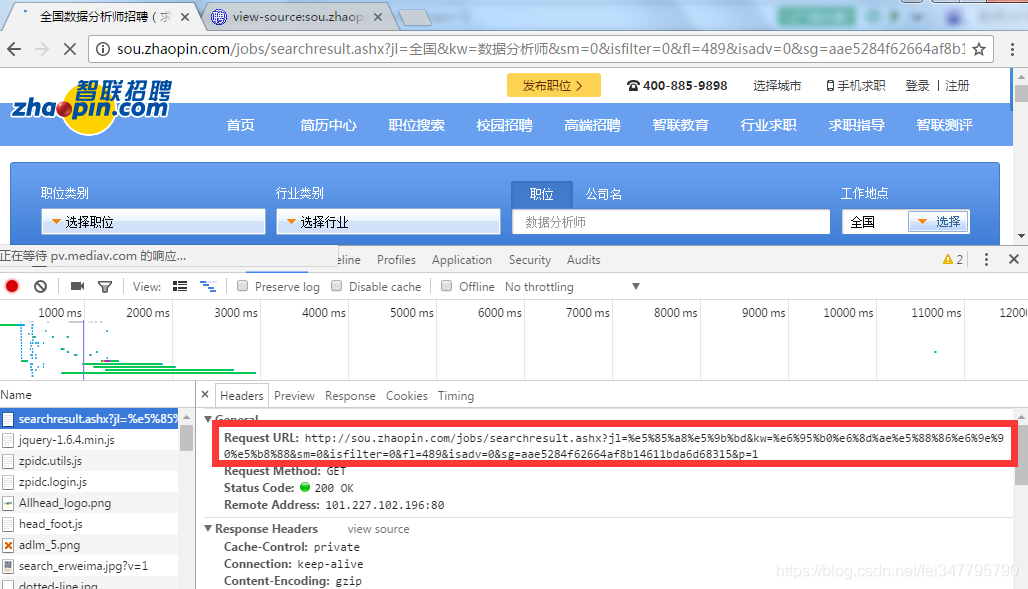
里面没有中文啊,复制出来访问看看。
果然一样!!!
注意到这个url最后有个p=1,这很可能是页码,我换成5试试吧
看上图,果然是这样,我试试最后第90页
果然是这样,接下来继续写代码
for k in range(1,91):
html=request.urlopen("http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e5%85%a8%e5%9b%bd&kw=%e6%95%b0%e6%8d%ae%e5%88%86%e6%9e%90%e5%b8%88&sm=0&isfilter=0&fl=489&isadv=0&sg=aae5284f62664af8b14611bda6d68315&p="+str(k)).read() #读取网页源代码内容
pat1 = 'onclick="submitLog.*?">(.*?)</a>'
pat2 = '<td class="gsmc"><a href="https://ask.hellobi.com/(.*?)" target='
pat3 = '<td class="zwyx">(.*?)</td>'
pat4 = '<td class="gzdd">(.*?)</td>'
pat5 = 'target="_blank">(.*?)<'
result1 = re.compile(pat1).findall(str(html,"utf-8"))
result2 = re.compile(pat2).findall(str(html,"utf-8"))
result3 = re.compile(pat3).findall(str(html,"utf-8"))
result4 = re.compile(pat4).findall(str(html,"utf-8"))
result5 = re.compile(pat5).findall(str(html,"utf-8"))
result11.extend(result1)
result21.extend(result2)
result31.extend(result3)
result41.extend(result4)
result51.extend(result5)
range(1,91)循环爬取1~90页,p="+str(k)是为了构造循环网址(我要把90页全爬下来)
通过观察网页构造选择正则提取
每次提取一页中的所有信息不断循环存在result11~51的列表里
j = 0
for i in range(0,len(result11)):
try:
zhiwei = result11[i]
wangzhi = result21[i]
gongzi = result31[i]
gongzuodidian = result41[i]
gongsimingcheng = result51[i]
sheet.write(i + 1, j, zhiwei)
sheet.write(i + 1, j + 1, wangzhi)
sheet.write(i + 1, j + 2, gongzi)
sheet.write(i + 1, j + 3, gongzuodidian)
sheet.write(i + 1, j + 4, gongsimingcheng)
except Exception as e:
print('出现异常:' + str(e))
continue
book.save('d:\shujufenxishi.xls')
最后把列表文件循环写到本地xls文件中
结果如下图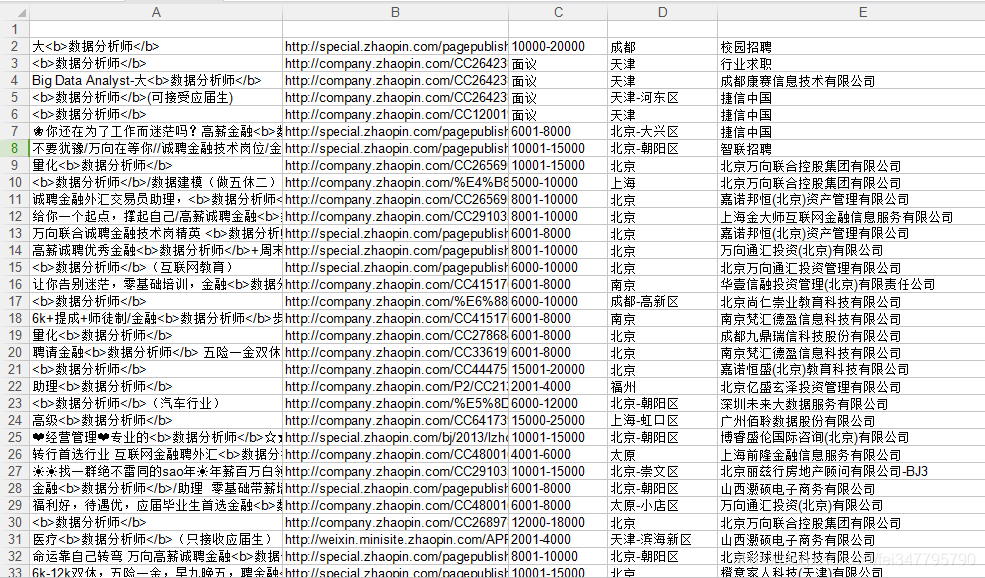
完整代码如下:
from urllib import request
import re
import os,glob
import xlwt
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
book = xlwt.Workbook()
sheet = book.add_sheet('sheet', cell_overwrite_ok=True)
path = 'D:\work'
os.chdir(path)
result11=[]
result21=[]
result31=[]
result41=[]
result51=[]
for k in range(1,91):
html=request.urlopen("http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e5%85%a8%e5%9b%bd&kw=%e6%95%b0%e6%8d%ae%e5%88%86%e6%9e%90%e5%b8%88&sm=0&isfilter=0&fl=489&isadv=0&sg=aae5284f62664af8b14611bda6d68315&p="+str(k)).read() #读取网页源代码内容
pat1 = 'onclick="submitLog.*?">(.*?)</a>'
pat2 = '<td class="gsmc"><a href="https://ask.hellobi.com/(.*?)" target='
pat3 = '<td class="zwyx">(.*?)</td>'
pat4 = '<td class="gzdd">(.*?)</td>'
pat5 = 'target="_blank">(.*?)<'
#pat6 = '<span>(.*?)</span>'
#pat7 = 'target="_blank">(.*?)</a>'
result1 = re.compile(pat1).findall(str(html,"utf-8"))
result2 = re.compile(pat2).findall(str(html,"utf-8"))
result3 = re.compile(pat3).findall(str(html,"utf-8"))
result4 = re.compile(pat4).findall(str(html,"utf-8"))
result5 = re.compile(pat5).findall(str(html,"utf-8"))
result11.extend(result1)
result21.extend(result2)
result31.extend(result3)
result41.extend(result4)
result51.extend(result5)
j = 0
for i in range(0,len(result11)):
try:
zhiwei = result11[i]
wangzhi = result21[i]
gongzi = result31[i]
gongzuodidian = result41[i]
gongsimingcheng = result51[i]
sheet.write(i + 1, j, zhiwei)
sheet.write(i + 1, j + 1, wangzhi)
sheet.write(i + 1, j + 2, gongzi)
sheet.write(i + 1, j + 3, gongzuodidian)
sheet.write(i + 1, j + 4, gongsimingcheng)
except Exception as e:
print('出现异常:' + str(e))
continue
book.save('d:\shujufenxishi.xls')
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
