社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Java中I/O操作主要是指使用Java进行输入,输出操作。Java所有的I/O机制都是基于数据流进行输入输出,这些数据流表示了字符或者字节数据的流动序列。Java的I/O流提供了读写数据的标准方法。任何Java中表示数据源的对象都会提供以数据流的方式读写它的数据的方法。
在JavaAPI中,可以从其中读入一个字节序列的对象称做输入流,而可以向其中写入一个字节序列的对象称做输出流。这些字节序列的来源地和目的地可以是文件,而且通常都是文件,但是也可以是网络连接,甚至是内存块。抽象类Inputstream和Outputstream构成了输人/输出(I/O)类层次结构的基础。此抽象类是表示字节输入流的所有类的超类。这也是网络中说的字节流。
因为面向字节的流不便于处理以Unicode形式存储的信息,所以从抽象类Reader和Writer中继承出来了一个专门用于处理Unicode字符的单独的类层次结构。这些类拥有的读入和写出操作都是基于两字节的Unicode码元的,而不是基于单字节的字符。这也是网络定义的字符流。
字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的,而字符流在操作的时候是使用到缓冲区。
字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容。
如下图所示:
缓冲区可以简单地理解为一段内存区域。
可以简单地把缓冲区理解为一段特殊的内存。
某些情况下,如果一个程序频繁地操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入到内存的一块区域之中,以后直接从此区域中读取数据即可,因为读取内存速度会比较快,这样可以提升程序的性能。
在字符流的操作中,所有的字符都是在内存中形成的,在输出前会将所有的内容暂时保存在内存之中,所以使用了缓冲区暂存数据。在实际使用中,所有的文件在硬盘或在传输时都是以字节的方式进行的,包括图片等都是按字节的方式存储的,而字符是只有在内存中才会形成,所以在开发中,字节流使用较为广泛。而且为了提高性能和使用方便,字节流也提供了BufferedInputStream,PipedInputStream等。
字节流转化为字符流时,实际上就是byte[]转化为String,比如:public String(byte bytes[], String charsetName) 。
字符流转化为字节流时,实际上是String转化为byte[],比如:byte[] String.getBytes(String charsetName)。
下图展示了最基层的Inputstream和Outputstream的结构:
Closeable 是可以关闭的数据源或目标。调用 close 方法可释放对象保存的资源。
这里介绍Inputstream类有一个抽象的方法abstract int read(),这个方法将读入一个字节,并返回读入的字节,或者在遇到输入源结尾时返回 -1。在输入数据可用、检测到流末尾或者抛出异常前,此方法一直阻塞。在设计具体的输入流类时,必须覆盖这个方法以提供适用的功能,例如,在Filelnputstream类中,这个方法将从某个文件中读人一个字节,而System.in(它是Inputstream的一个子类的预定义对象)却是从键盘读入信息。
Outputstream对应着还有一个:abstract void write(int b)。Outputstream抽象类是表示输出字节流的所有类的超类。输出流接受输出字节并将这些字节发送到某个接收器。
AutoCloseable 是Java7之后引入的接口请看 https://blog.csdn.net/ydonghao2/article/details/82316191
IO各种类型的接口可以看:https://blog.csdn.net/ydonghao2/article/details/82317505
InputStream
| 方法摘要 | |
|---|---|
int |
available() 返回此输入流下一个方法调用可以不受阻塞地从此输入流读取(或跳过)的估计字节数。 |
void |
close() 关闭此输入流并释放与该流关联的所有系统资源。 |
void |
mark(int readlimit) 在此输入流中标记当前的位置。 |
boolean |
markSupported() 测试此输入流是否支持 mark 和 reset 方法。 |
abstract int |
read() 从输入流中读取数据的下一个字节。 |
int |
read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。 |
int |
read(byte[] b, int off, int len) 将输入流中最多 len 个数据字节读入 byte 数组。 |
void |
reset() 将此流重新定位到最后一次对此输入流调用 mark 方法时的位置。 |
long |
skip(long n) 跳过和丢弃此输入流中数据的 n 个字节。 |
OutputStream
| 方法摘要 | |
|---|---|
void |
close() 关闭此输出流并释放与此流有关的所有系统资源。 |
void |
flush() 刷新此输出流并强制写出所有缓冲的输出字节。 |
void |
write(byte[] b) 将 b.length 个字节从指定的 byte 数组写入此输出流。 |
void |
write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 |
abstract void |
write(int b) 将指定的字节写入此输出流。 |
完整的流家族
InputStream
public static void main(String[] args) {
String rootPath = Thread.currentThread().getContextClassLoader().getResource("").toString().substring(6);
try (FileInputStream fis = new FileInputStream(rootPath+ File.separator+"test.txt");
FileOutputStream fos = new FileOutputStream(rootPath+ File.separator+"test.txt", true)
) {
int b;
while ((b = fis.read()) != -1) {
System.out.print((char)b);
}
fos.write("xxxxxxxxxxxn".getBytes());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
InputStream和OutputStream通过RandomAccessFile关联。
OutputStream
public static void main(String[] args) {
String rootPath = Thread.currentThread().getContextClassLoader().getResource("").toString().substring(6);
List<File> files = new ArrayList<>(100);
try {
for (int i = 8; i < 108; i++) {
String fileName = Integer.toBinaryString(Objects.hashCode(i));
List<Comment> comments = new ArrayList<>(20);
for (int j = 0; j < 20; j++) {
Comment comment = new Comment();
comment.setId(j);
comment.setContent("Love " + fileName);
comments.add(comment);
}
User user = new User();
user.setId(i);
user.setName(fileName);
user.setPassword(Integer.toBinaryString(fileName.hashCode()));
user.setComments(comments);
File file = File.createTempFile(fileName, suffix, new File(rootPath));
try (FileInputStream fis = new FileInputStream(file);
FileOutputStream fos = new FileOutputStream(file, true);
) {
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(user);
ObjectInputStream ois = new ObjectInputStream(fis);
User object = (User) ois.readObject();
System.out.println(object);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
files.forEach(File::deleteOnExit);
}
}
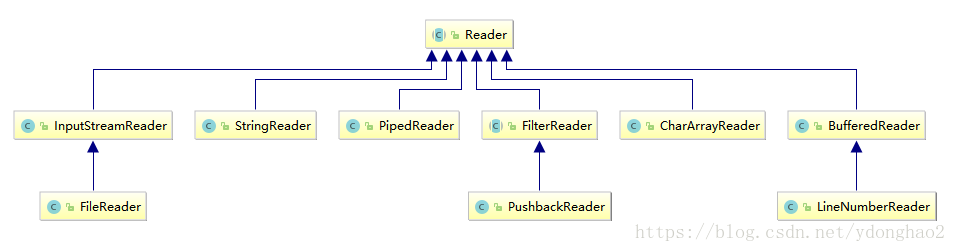
对于字符流(Unicode文本),可以使用抽象类Reader和Writer的子类(请参见下面两张图)。Reader和writer类的基本方法与Inputstream和Outputstream中的方法类似abstract int read(),abstract void write(int c)。read方法将返回一个Unicode码元(一个在0~65535之间的整数),或者在碰到文件结尾时返回 -1。write方法在被调用时,需要传递一个Unicode码元。
所有在java.io中的类都将相对路径名解释为以用户工作目录开始,你可以通过调用System.getProperty("user.dir")来获得这个信息。
警告:由于反斜杠字符在Java字符串中是转义字符,因此要确保在Windows风格的路径名中使用\(例如,C:\Windows\win.ini,在Windows中,还可以使用单斜杠字符(C:/Windows/win.ini),因为大部分Windows文件处理的系统调用都会将斜杠解释成文件分隔符。但是,并不推荐这样做,因为Windows系统函数的行为会因与时俱进而发生变化。
因此,对于可移植的程序来说,应该使用程序所运行平台的文件分隔符,我们可以通过常量字符串java.io.File.separator获得它。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!