社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在写这篇文章之前,我也是不是很清楚,感觉Elasticsearch的ingest node的功能越来越强大。在一次聚会上,我的一个同事也告诉我现在使用ingest node在社区里越来越普及。他们感觉到Elasticsearch ingest node的便利,同时也可以不需额外的安装和部署,并且还可以做其它的用途。的确随着Elasticsearch新的ingest node的功能越来越强大,它和Logstash的很多功能也有重叠的地方。那么我们在实际的应用中,到底是选择Logstash还是ingest node呢。Ingest node里也含有很多的processors供我们使用。你如果对Elasticsearch ingest node里的processors还不是很了解的话,请参阅官方的链接https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest-processors.html
Logstash是Elastic Stack的原始组件之一,长期以来一直是需要分析,丰富或处理数据时使用的工具。多年来,已添加了大量输入,输出和过滤器插件,使其成为一种非常灵活且功能强大的工具,可以使其在各种不同的体系结构中工作。
在Elasticsearch 5.0中引入了ingest节点,作为在索引之前处理Elasticsearch中的文档的一种方式。它们允许使用最少的组件的简单架构,其中应用程序将数据直接发送到Elasticsearch进行处理和索引。这通常可以简化Elastic Stack的入门,但是也可以随着数据量的增长而扩展。
但是,ingest节点的确复制了Logstash中的某些功能,因此,我们用户的一个常见问题是他们应该使用哪个功能。在此博客文章中,我们讨论了在两者之间进行选择时需要考虑的体系结构方面,以帮助您做出更明智的决策。
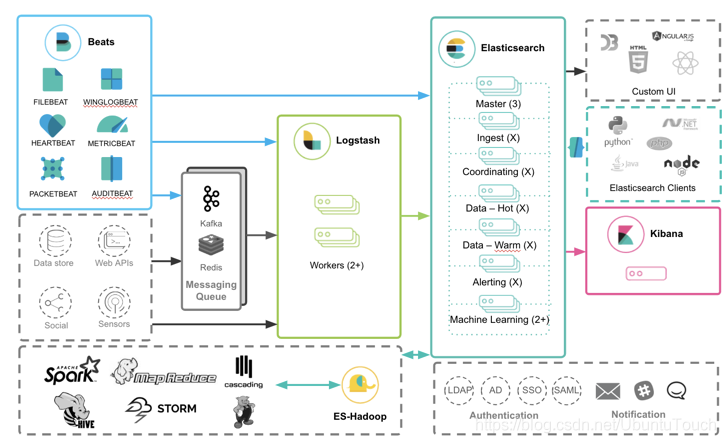
从上面的图中,我们可以看出来:针对beats的数据来说,我们可以通过如下的三条途径:
在我们的实际的使用中,我们应该选择哪一种途径呢?
Logstash与ingest节点之间的主要区别之一是数据的进出方式。
当ingest节点在Elasticsearch的索引流中运行时,必须通过批量或索引请求将数据推送到该节点。 因此,必须有一个将数据主动写入Elasticsearch的过程。 接收节点无法从外部源(例如消息队列或数据库)中提取数据。
处理完数据后,存在类似的限制-唯一的选择是将数据本地索引到Elasticsearch中。
另一方面,Logstash具有各种各样的输入和输出插件,可用于支持各种不同的体系结构。 它可以充当服务器并接受客户端通过TCP,UDP和HTTP推送的数据,并主动从 数据库和消息队列。 当涉及到输出时,有很多可用的选项,例如消息队列(例如Kafka和RabbitMQ)或S3或HDFS上的长期数据归档。
将数据发送到Elasticsearch时,无论是直接发送数据还是通过ingest管道发送数据,每个客户端都必须能够处理Elasticsearch无法保持或接受更多数据的情况。这就是我们所说的施加背压(back-pressure)。如果数据节点不能接受数据,则接收节点也将停止接受数据。
如果在Elasticsearch无法访问或无法长时间接受数据的情况下,无论是在源头还是在过程中,在处理管道中都没有建立排队机制的体系结构都有可能遭受数据丢失的困扰(目前有些beats,比如Filebeat含有背压支持)。这包括无法存储和读取文件数据的Beats以及其他能够直接写入Elasticsearch的进程,例如syslog-ng。
Logstash能够使用其持久队列功能在磁盘上将数据排队,从而使Logstash至少可以提供一次传输保证,并通过摄取高峰在本地缓冲数据。 Logstash还支持与许多不同类型的消息队列的集成,从而允许支持多种部署模式。
Ingest节点带有20多种不同的处理器,涵盖了最常用的Logstash插件的功能。 但是,一个限制是,摄取节点管道只能在单个事件的上下文中工作。 处理器通常也无法调出其他系统或从磁盘读取数据,这在某种程度上限制了可以执行的扩充类型。
Logstash有很多可供选择的插件。 这包括基于配置文件,Elasticsearch或关系数据库中的查找来添加或转换内容的插件。
Beats和Logstash还支持根据可配置的标准过滤和删除事件,这在摄取节点中目前是不可能的。
这是一个非常主观的话题,取决于您的背景和习惯。每个摄取节点管道均在JSON文档中定义,该文档存储在Elasticsearch中。可以定义大量不同的管道,但是每个文档在通过摄取节点时只能由单个管道处理。这种格式可能比Logstash配置文件格式更容易使用,至少对于相当简单且定义明确的管道而言。对于处理多种数据格式的更复杂的管道,Logstash允许使用条件控制流的事实通常使它更易于使用。 Logstash还支持定义多个逻辑上独立的管道,这些管道可以通过基于Kibana的用户界面进行管理。
还值得注意的是,在Logstash中,测量和优化管道性能通常更容易,因为它支持监视并且具有出色的管道查看器UI,可用于快速查找瓶颈和潜在问题。如果你想对Logstash的监控感兴趣的话,请参阅我之前的文章“Logstash: 启动监控及集中管理”。
关于ingest节点的一大优点是它允许非常简单的架构,Beats可以将其直接写入摄取节点管道。 Elasticsearch集群中的每个节点都可以充当摄取节点,这至少可以在较小的用例中降低硬件占用空间并降低架构的复杂性。
一旦数据量增加或处理变得更加复杂,从而导致群集中的CPU负载更高,通常建议切换到使用专用的接收节点。 此时,将需要额外的硬件来托管专用摄取节点或Logstash,并且硬件占用空间的任何差异都将在很大程度上取决于用例。
到目前为止,似乎Ingest节点仅提供Logstash支持的功能的子集-但是,这并不完全准确。
Ingest节点支持ingest attachment processor plugin,该插件可用于处理和索引常见格式的附件,例如PPT,XLS和PDF。当前没有等效的插件可用于Logstash,因此,如果您打算索引各种类型的附件,则可能需要ingest节点。
由于ingest管道会在索引数据之前执行,因此它也是添加时间戳的最可靠方法,该时间戳指示何时对事件进行索引,例如为了准确地测量和分析ingest延迟。在数据成功到达Elasticsearch之前进行设置可能会产生误导,因为设置时间戳和将数据索引到Elasticsearch之间可能会有延迟,例如如果正在施加背压,或者客户端被迫多次尝试对数据进行索引。此类时间戳可用于衡量每个文档的 ingest delay per document。
即使选择常常是一个自己的喜好,但由于Logstash支持将数据发送到ingest管道,因此自然也可以将它们一起使用。 对于更复杂的体系结构,可能还会有多个逻辑流,它们可能具有非常不同的要求。 有些可能会通过Logstash,而另一些可能会直接发送到Elasticsearch接收节点。 使用对每个数据流最有意义的方法通常会使体系结构更易于维护。
在实际的使用中,由于使用多个组件一起使用,也可能会使得我们的系统的稳定性带来一定的影响。
Logstash和Elasticsearch ingest节点之间的功能存在重叠。 这意味着可以使用两种技术来实现某些体系结构。 但是,这两种选择都有各自的优缺点,因此分析整个处理管道的要求和体系结构并根据此博客文章中讨论的标准选择最合适的方法非常重要。 选择并不总是一个接一个,因为它们可以一起或并行用于处理管道的不同部分。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
