社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Base on go 1.13
golang runtime的另外一大主题就是内存分配器,内存分配策略与协程栈、堆、GC等话题息息相关。
tcmalloc 的机制可以参考::TCMalloc : Thread-Caching Malloc 论文翻译
golang的内存分配器虽然思想来源于tcmalloc但是实际上与tcmalloc有很大区别,其中很重要一点是Go 语言被设计为没有显式的内存分配与释放,完全依靠编译器与 runtime 的配合来自动处理,因此也就造就为了内存分配器、垃圾回收器两大组件。
在计算机领域性能优化基本离不开空间换时间,时间换空间,统一管理内存会提前分配或一次性释放一大块内存,进而减少与操作系统沟通造成的开销,进而提高程序的运行性能。支持内存管理另一个优势就是能够更好的支持垃圾回收,这一点我们留到垃圾回收器一节中进行讨论。
核心的结构就是:
页是向操作系统申请内存的最小单位,目前设计为 8kb。
这些结构之间的关系比较复杂,后面我们将一点点梳理他们之间的关系。
在golang里面内存分为部分,传统意义上的栈由 runtime 统一管理,用户态不感知。而传统意义上的堆内存,又被 Go 运行时划分为了两个部分,
Go 堆负责了用户态对象的存放以及 goroutine 的执行栈。
Golang 的堆由很多个 arena 组成,每个 arena 在 64 位机器上是 64MB,且起始地址与 arena 的大小对齐,
所有的 arena 覆盖了整个 Golang 堆的地址空间。
heapArena 对象存储了一个 heap arena的元数据,heapArena对象自身存储在Go heap之外,并且通过mheap_.arenas index 来访问。heapArena对象直接从操作系统分配的,所以理想情况下应该是系统页面大小的倍数。
const(
pageSize = 8192//8KB
heapArenaBytes = 67108864 //一个heapArena是64MB
heapArenaBitmapBytes = heapArenaBytes / 32 // 一个heapArena的bitmap占用2MB
pagesPerArena = heapArenaBytes / pageSize // 一个heapArena包含8192个页
)
//go:notinheap
type heapArena struct {
bitmap [heapArenaBitmapBytes]byte //2,097,152
spans [pagesPerArena]*mspan //
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
}
简而言之,heapArena 描述了一个 heap arena 的元信息。
arenaHint结构比较简单,是 arenaHint 链表的节点结构,保存了arena 的起始地址、是否为最后一个 arena,以及下一个 arenaHint 指针。
//go:notinheap
type arenaHint struct {
addr uintptr
down bool
next *arenaHint
}
前面说了,heapArena 的内存大小是64M,直接管理这么粗粒度的内存明显不符合实践。golang使用span机制来减少碎片. 每个span至少分配1个page(8KB), 划分成固定大小的slot, 用于分配一定大小范围的内存需求,小于 32kb 的小对象则分配在固定大小等级的 span 上,否则直接从 mheap 上进行分配。
mspan 是相同大小等级的 span 的双向链表的一个节点,每个节点还记录了自己的起始地址、指向的 span 中页的数量。
//go:notinheap
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
//......
freeindex uintptr
//......
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
state mSpanStateBox // mSpanInUse etc; accessed atomically (get/set methods)
elemsize uintptr // computed from sizeclass or from npages
}
这里举一个例子:32byte的span,span占用一个页,所以总共有256个slot: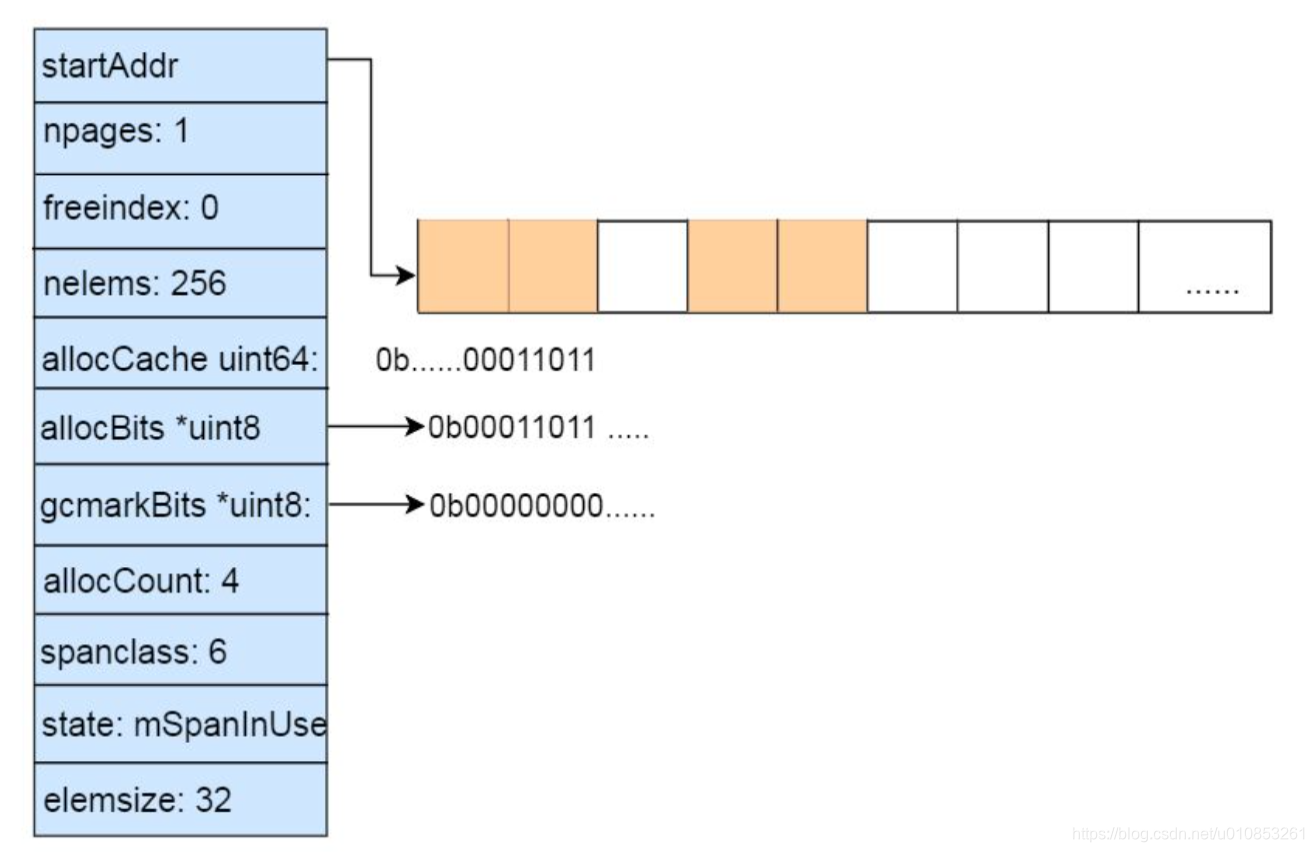
前面一直都说,spanclass可以确定当前span的page数以及分配的对象的大小:
// sizeclasses.go
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
// 12 176 8192 46 96 9.59%
// 13 192 8192 42 128 9.25%
// 14 208 8192 39 80 8.12%
// 15 224 8192 36 128 8.15%
// 16 240 8192 34 32 6.62%
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
// 26 576 8192 14 128 12.33%
// 27 640 8192 12 512 15.48%
// 28 704 8192 11 448 13.93%
// 29 768 8192 10 512 13.94%
// 30 896 8192 9 128 15.52%
// 31 1024 8192 8 0 12.40%
// 32 1152 8192 7 128 12.41%
// 33 1280 8192 6 512 15.55%
// 34 1408 16384 11 896 14.00%
// 35 1536 8192 5 512 14.00%
// 36 1792 16384 9 256 15.57%
// 37 2048 8192 4 0 12.45%
// 38 2304 16384 7 256 12.46%
// 39 2688 8192 3 128 15.59%
// 40 3072 24576 8 0 12.47%
// 41 3200 16384 5 384 6.22%
// 42 3456 24576 7 384 8.83%
// 43 4096 8192 2 0 15.60%
// 44 4864 24576 5 256 16.65%
// 45 5376 16384 3 256 10.92%
// 46 6144 24576 4 0 12.48%
// 47 6528 32768 5 128 6.23%
// 48 6784 40960 6 256 4.36%
// 49 6912 49152 7 768 3.37%
// 50 8192 8192 1 0 15.61%
// 51 9472 57344 6 512 14.28%
// 52 9728 49152 5 512 3.64%
// 53 10240 40960 4 0 4.99%
// 54 10880 32768 3 128 6.24%
// 55 12288 24576 2 0 11.45%
// 56 13568 40960 3 256 9.99%
// 57 14336 57344 4 0 5.35%
// 58 16384 16384 1 0 12.49%
// 59 18432 73728 4 0 11.11%
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%
const (
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 67
_PageShift = 13
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
主要就是数组class_to_size和数组class_to_allocnpages。 数组的size 都是67,也就是0-66。index对应的value分别就是对象的大小以及span占用page数目。
class0表示分配一个>32KB对象的span, 有67个 size, 每个size两种, 用于分配有指针和无指针对象, 所以代码里面总共有67*2=134个class。比如 spanClass 是1,那么对应分配对象就是8bytes,然后一个span占用 一个页内存,也就是8Kb。
// Central list of free objects of a given size.
//go:notinheap
type mcentral struct {
lock mutex
spanclass spanClass
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
nmalloc uint64
}
当 mcentral 中 nonempty 列表中也没有可分配的 span 时,则会向 mheap 提出请求,从而获得新的 span,并进而交给 mcache。
mcache是一个 per-P 的缓存,它是一个包含不同大小等级的 span 链表的数组,其中 mcache.alloc 的每一个数组元素都是某一个特定大小的 mspan 的链表头指针。
const numSpanClasses = _NumSizeClasses << 1 // means (67<<1)
// Per-thread (in Go, per-P) cache for small objects.
// No locking needed because it is per-thread (per-P).
//
// mcaches are allocated from non-GC'd memory, so any heap pointers
// must be specially handled.
//
//go:notinheap
type mcache struct {
......
// Allocator cache for tiny objects w/o pointers.
// See "Tiny allocator" comment in malloc.go.
// tiny points to the beginning of the current tiny block, or
// nil if there is no current tiny block.
//
// tiny is a heap pointer. Since mcache is in non-GC'd memory,
// we handle it by clearing it in releaseAll during mark
// termination.
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
stackcache [_NumStackOrders]stackfreelist
// Local allocator stats, flushed during GC.
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
......
}
当 mcache 中 span 的数量不够使用时,会向 mcentral 的 nonempty 列表中获得新的 span。
//go:notinheap
type mheap struct {
lock mutex
free mTreap // free spans
......
allspans []*mspan // all spans out there
......
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
......
arenaHints *arenaHint
arena linearAlloc
......
// central free lists for small size classes.
// the padding makes sure that the mcentrals are
// spaced CacheLinePadSize bytes apart, so that each mcentral.lock
// gets its own cache line.
// central is indexed by spanClass.
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
treapalloc fixalloc // allocator for treapNodes*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
......
}
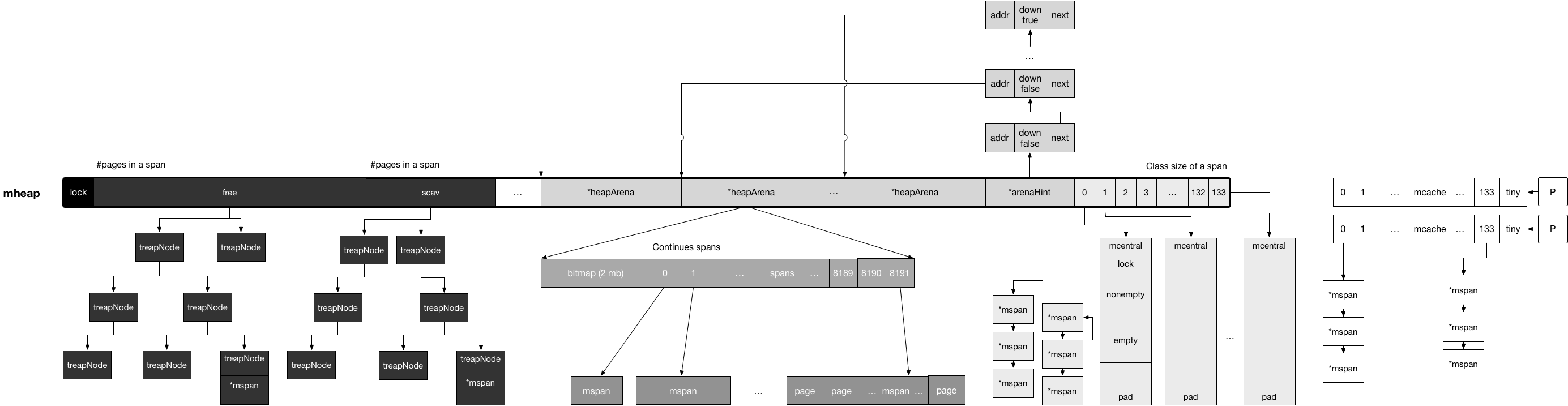
heap是中间的一行:
分配的整体顺序是从右向左,代价也越来越大。
golang程序的运行是基于 goroutine 的,goroutine 和传统意义上的程序一样,也有栈和堆的概念,在
Go runtime 内部分别对应:goroutine 执行栈以及 Go 堆。goroutine 的执行栈和我们传统意义上的栈一样,当函数返回时,在栈的对象都会被自动回收,从而无需 GC 的标记;而堆则麻烦一些,Go 支持垃圾回收,只要对象生存在堆上,Go 的runtime GC 会在后台自动进行标记、整理以及在垃圾回收时候回收内存,GC的存在会导致额外的开销。
举个简单的程序:
func f1() *int {
y := 2
return &y
}
func main() {
y := f1()
println(y)
}
go build -gcflags '-m -l -N' memory_alloc.go
输出:
# command-line-arguments
./memory_alloc.go:5:2: moved to heap: y
我们看到变量y分配到了heap上。我们再看看 f1() 汇编代码:
"".f1 STEXT size=79 args=0x8 locals=0x18
......
0x0024 00036 (memory_alloc.go:5) MOVQ AX, (SP)
0x0028 00040 (memory_alloc.go:5) CALL runtime.newobject(SB)
0x002d 00045 (memory_alloc.go:5) PCDATA $0, $1
......
可以发现,对于产生在 golang 堆上分配对象的情况,均调用了运行时的 runtime.newobject 方法。
当然,关键字 new 同样也会被编译器翻译为此函数。
所以 runtime.newobject 就是内存分配的核心入口了。
下面我们看 runtime.newobject 实现:
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
const (
maxSmallSize = 32768 //32kb
maxTinySize = 16 //16byte
)
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// 创建大小为零的对象,例如空结构体
if size == 0 {
return unsafe.Pointer(&zerobase)
}
......
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
......
mp.mallocing = 1
......
// 获取当前 g 所在 M 所绑定 P 的 mcache
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// 微对象分配
......
} else {
// 小对象分配
......
}
} else {
// 大对象分配
......
}
......
mp.mallocing = 0
releasem(mp)
......
return x
}
其中 _type 为 Go 类型的实现,通过其 size 属性能够获得该类型所需要的大小。
在分配过程中,我们会发现需要持有 M 才可进行分配,这是因为分配不仅可能涉及 mcache,还需要将正在分配的 M 标记为 mallocing,用于记录当前 M 的分配状态。
小对象分配
当对一个小对象(<32kB)分配内存时,会将该对象所需的内存大小调整到某个能够容纳该对象的大小等级(size class),并查看 mcache 中对应等级的 mspan,通过扫描 mspan 的 freeindex 来确定是否能够进行分配。
当没有可分配的 mspan 时,会从 mcentral 中获取一个所需大小空间的新的 mspan,从 mcentral 中分配会对其进行加锁,但一次性获取整个 span 的过程均摊了对 mcentral 加锁的成本。
如果 mcentral 的 mspan 也为空时,则它也会发生增长,从而从 mheap 中获取一连串的页,作为一个新的 mspan 进行提供。而如果 mheap 仍然为空,或者没有足够大的对象来进行分配时,则会从操作系统中分配一组新的页(至少 1MB),从而均摊与操作系统沟通的成本。
微对象分配
对于过小的微对象(<16B),它们的分配过程与小对象的分配过程基本类似,但是是直接存储在 mcache 上,并由其以 16B 的块大小直接进行管理和释放
大对象分配
大对象分配非常粗暴,不与 mcache 和 mcentral 沟通,直接绕过并通过 mheap 进行分配。
这里主要是说 fixalloc。fixalloc 是一个基于自由列表的固定大小的分配器。其核心原理是将若干未分配的内存块连接起来,将未分配的区域的第一个字为指向下一个未分配区域的指针使用。
Go 的主分配堆中 malloc(span、cache、treap、finalizer、profile、arena hint 等) 均围绕它为实体进行固定分配和回收。
fixalloc 作为抽象,非常简洁,只包含三个基本操作:初始化、分配、回收
type fixalloc struct {
size uintptr
first func(arg, p unsafe.Pointer) // called first time p is returned
arg unsafe.Pointer
list *mlink
chunk uintptr // use uintptr instead of unsafe.Pointer to avoid write barriers
nchunk uint32
inuse uintptr // in-use bytes now
stat *uint64
zero bool // zero allocations
}
fixalloc 是一个简单的固定大小对象的自由表内存分配器。
Malloc 使用 fixalloc 来管理其 MCache 和 MSpan 对象。
fixalloc.alloc 返回的内存默认为零值,但调用者可以通过将 zero 标志设置为 false来自行负责将分配归零。如果这部分内存永远不包含堆指针,则这样的操作是安全的。
调用方负责锁定 fixalloc 调用。调用方可以在对象中保持状态,但当释放和重新分配时第一个字会被破坏。
Go 语言对于零值有自己的规定,自然也就体现在内存分配器上。而 fixalloc 作为内存分配器内部组件的来源于
操作系统的内存,自然需要自行初始化,因此,fixalloc 的初始化也就不可避免的需要将自身的各个字段归零:
func (f *fixalloc) init(size uintptr, first func(arg, p unsafe.Pointer), arg unsafe.Pointer, stat *uint64) {
f.size = size
f.first = first
f.arg = arg
f.list = nil
f.chunk = 0
f.nchunk = 0
f.inuse = 0
f.stat = stat
f.zero = true
}
fixalloc 基于自由表策略进行实现,分为两种情况:
对于第一种情况,也就是在运行时内存被释放,但这部分内存并不会被立即回收给操作系统,
我们直接从自由表中获得即可,但需要注意按需将这部分内存进行清零操作。
对于第二种情况,我们直接向操作系统申请固定大小的内存,然后扣除分配的大小即可。
const(
_FixAllocChunk = 16 << 10 // 16kb, Chunk size for FixAlloc
)
func (f *fixalloc) alloc() unsafe.Pointer {
//使用之前必须先初始化
if f.size == 0 {
print("runtime: use of FixAlloc_Alloc before FixAlloc_Initn")
throw("runtime: internal error")
}
// 如果 f.list 不是 nil, 则说明还存在已经释放、可复用的内存,直接将其分配
if f.list != nil {
v := unsafe.Pointer(f.list)
f.list = f.list.next
// 更新已使用的内存
f.inuse += f.size
if f.zero {
//如果需要对内存清零,则对取出的内存执行初始化
memclrNoHeapPointers(v, f.size)
}
return v
}
//如果此时 nchunk 不足以分配一个 size
if uintptr(f.nchunk) < f.size {
// 则向操作系统申请内存,大小为 16 << 10 pow(2,14)
f.chunk = uintptr(persistentalloc(_FixAllocChunk, 0, f.stat))
f.nchunk = _FixAllocChunk
}
// 指向申请好的内存
v := unsafe.Pointer(f.chunk)
if f.first != nil {
f.first(f.arg, v)
}
// 扣除并保留 size 大小的空间
f.chunk = f.chunk + f.size
f.nchunk -= uint32(f.size)
f.inuse += f.size // 记录已经使用的大小
return v
}
回收就更加简单了,直接将回收的地址指针放回到自由表中即可:
func (f *fixalloc) free(p unsafe.Pointer) {
// 减少使用的字节数
f.inuse -= f.size
// 将要释放的内存地址作为 mlink 指针插入到 f.list 内,完成回收
v := (*mlink)(p)
// 头插入自由列表
v.next = f.list
f.list = v
}
系统级的内存管理调用是平台相关的,这里以 Linux 为例,运行时的 sysAlloc、sysUnused、sysUsed、sysFree、sysReserve、sysMap 和 sysFault 都是系统级的调用。
其中 sysAlloc、sysReserve 和 sysMap 都是向操作系统申请内存的操作,他们均涉及关于内存分配的系统调用就是 mmap,区别在于:
sysAlloc 是从操作系统上申请清零后的内存,调用参数是 _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE;sysReserve 是从操作系统中保留内存的地址空间,并未直接分配内存,调用参数是 _PROT_NONE, _MAP_ANON|_MAP_PRIVATE,;sysMap 则是用于通知操作系统使用先前已经保留好的空间,参数是 _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE。不过 sysAlloc 和 sysReserve 都是操作系统对齐的内存,但堆分配器可能使用更大的对齐方式,因此这部分获得的内存都需要额外进行一些重排的工作。
这里来讲一下 heap 的初始化。除去执行栈外,内存分配器是最先完成初始化的,我们先来看这个初始化的过程。
内存分配器的初始化除去一些例行的检查之外,就是对堆的初始化了:
func mallocinit() {
// 一些涉及内存分配器的常量的检查,包括
// heapArenaBitmapBytes, physPageSize 等等
......
// 初始化堆
mheap_.init()
_g_ := getg()
_g_.m.mcache = allocmcache()
// 创建初始的 arena 增长 hint
if sys.PtrSize == 8 {
for i :=
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u010853261/article/details/102945046
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
-
发表于 2020-06-27 18:06:16
- 阅读 ( 1240 )
- 分类:Go
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
