社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术.
TF-IDF是一种统计方法,用以评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF主要思想:如果一个单词在该文章中出现的频率(TF)高,并且在其它文章中出现频率很低,则认为该单词具有很好的区分能力,适合用来进行分类。
1)词频(Term Frequency)表示单词在该文章中出现的频率。通常归一化处理,以防止它偏向长的文件。
词频(TF) = 单词在该文章出现次数/当前文章总单词数 2)反问档频率(Inverse Document Frequency)表示某一个特定单词IDF可以由总文章数除以包含该单词的文章数,再将得到的商取对数得到。如果包含该单词的文章越少,则IDF越大,则表明该单词具有很好的文章区分能力。
2)反问档频率(Inverse Document Frequency)表示某一个特定单词IDF可以由总文章数除以包含该单词的文章数,再将得到的商取对数得到。如果包含该单词的文章越少,则IDF越大,则表明该单词具有很好的文章区分能力。
反问档频率(IDF) = log(语料库中文章总数/(包含该单词的文章数+1))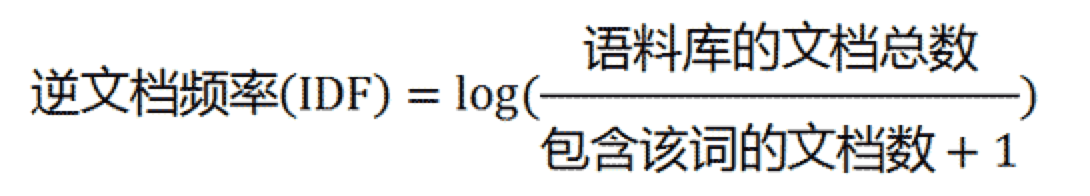
question:为什么分母+1?
answer:分母之所以+1是为了避免分母为0.
其实最简单的IDF公式应该是log(语料库中文章总数/(包含该单词的文章数)),但是在一些特殊的时候会出现问题,比如一些生僻词在语料库中没有,这样分母会为0,IDF就没有意义了,为了避免这种情况发生,我们需要对IDF进行一些平滑操作,使得语料库中没有出现的生僻词也可以得到一个合适的IDF值。平滑的方式有很多种,上面的将分母+1是最简单的一种方式,还有一种比较常见的IDF平滑公式是IDF=log(语料库中文章总数+1/(包含该单词的文章数+1)+1)
TF-IDF与一个词在文档中的出现次数成正比, 与包含该词的文档数成反比。
有了IDF的定义,我们就可以计算某一个词语的TF-IDF值:
TF-IDF(x)=TF(x)*IDF(x),其中TF(x)指单词x在当前文章中的词频。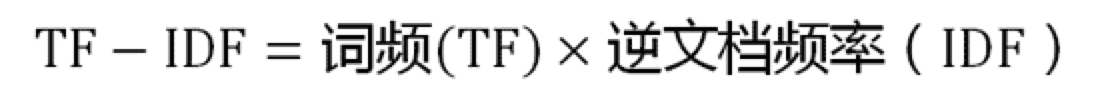
TF-IDF算法的优点:简单快速,结果比较符合实际情况。
TF-IDF算法的缺点:单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
TF-IDF的应用场景:TF-IDF算法可用来提取文档的关键词,关键词在文本聚类、文本分类、文献检索、自动文摘等方面有着重要应用。
以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,“中国”、“蜜蜂”、“养殖"各出现20次,则这三个词的"词频”(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下: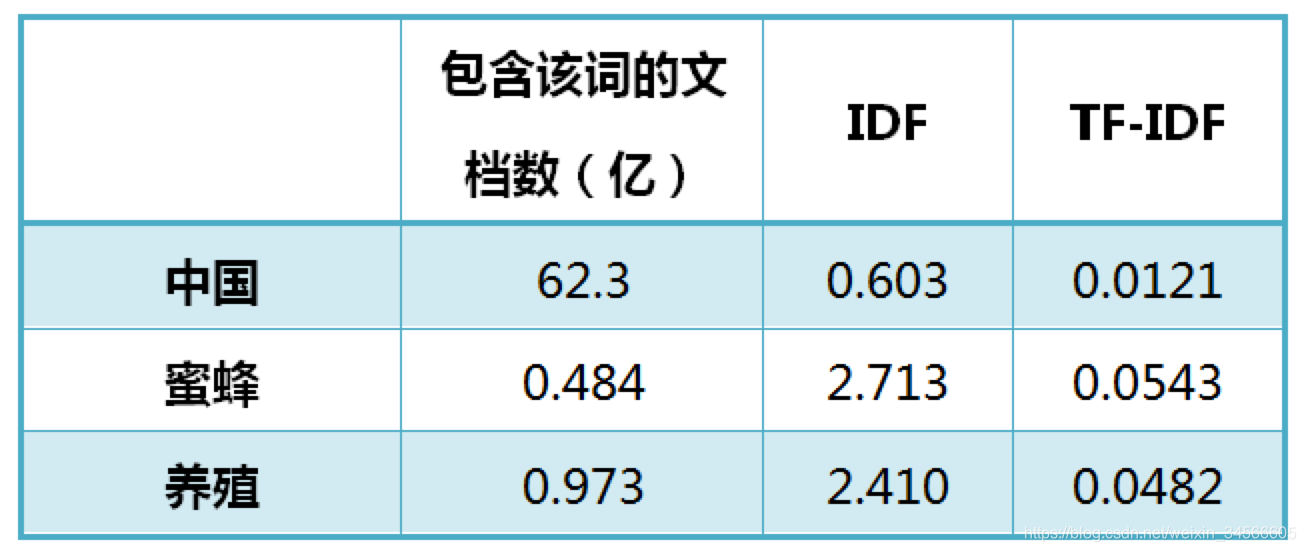 从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
开发步骤如下:
1)将所有数据文件内容汇总到一个数据文件中
# -*- coding: UTF-8 -*-
# Step1 原始数据预处理
import os
import sys
import math
file_path_dir = '../DataSet/it.seg.cln'
raw_path = './raw.data'
idf_path = './idf.data'
##读文件操作
def read_file(f):
fd = open(f, 'r', encoding='utf-8')
return fd
file_raw_out = open(raw_path, 'w', encoding='utf-8')
# 遍历整个原始数据目录,将零散的文章整合到一个文件中,便于后续数据处理
file_name = 0
for fd in os.listdir(file_path_dir):
file_path = file_path_dir + '/' + fd #文件路径
content_list = []
file_fd = read_file(file_path)
for line in file_fd:
content_list.append(line.strip())
#' '.join(content_list)
content = 't'.join([str(file_name),''.join (content_list)]) + 'n'
#print (content)
#print(type('t'.join(content_list)))
file_raw_out.writelines(content)
file_name += 1
print("文件个数:",file_name)
raw.data(汇总数据文件,键值对格式)的内容为:
2) 对所有文章按照一定规律进行切分(map过程)
对文章进行统计,求出IDF(reduce过程)
#step2 产生产生IDF词表
docs_count = file_name
wc_tulist = []
with open(raw_path, 'r', encoding='utf-8') as fd:
for line in fd:
#遍历每一篇文章,文章=line
ss = line.strip().split('t')
#如果分割每篇文章后的长度不是2,则表示这篇文章格式不是我们需要的,我们要的是 【序号t内容】格式
if len(ss)!=2:
continue
#对文章解析,区分文章序号和文章内容
file_number,file_content = ss
#对文章的内容进行切词,内容已经按照空格切好词了,所以按空格做split切割
word_list = file_content.strip().split(' ')
#print("word_list:",word_list)
#去重操作,对于IDF,只需要关注词在文章中是否出现,不关心出现次数
word_set = set(word_list)
#print("word_set:",word_set)
# 对于每个关键词,打一个标记“1”,来标识该次出现过
for word in word_set:
wc_tulist.append((word,'1'))
#print("wc_tulist:",wc_tulist)
#将内容输出到指定文件中./idf.data
file_idf_out = open(idf_path,'w',encoding='utf-8')
#按照词的字典序进行排序
wc_sort_tulist = sorted(wc_tulist,key=lambda x: x[0])
#print(wc_sort_tulist)
current_word = None
sum = 0
for tu in wc_sort_tulist:
word, val = tu
if current_word == None:
current_word = word
if current_word != word:
# 通过idf计算公式,得到每个关键词的idf score
idf = math.log(float(docs_count) / (float(sum) + 1.0))
content = 't'.join([current_word, str(idf)]) + 'n'
file_idf_out.write(content)
current_word = word
sum = 0
sum += int(val)
#反问档频率(IDF) = log(语料库中文章总数/(包含该单词的文章数+1))
idf = math.log(float(docs_count) / (float(sum) + 1.0))
# content格式是【wordst0.1212n】
content = 't'.join([current_word, str(idf)]) + 'n'
file_idf_out.write(content)
#print(content)
file_idf_out.close()
idf.data内容:
3) 求出最终的TF-IDF
# Step3 计算TF-IDF来提取文章中的关键词(文章单词的权重)
input_str = '我们 科技 带来 的 科技 希望 我们 差'
token_idf_dict = {}
# 将idf字典加载到内存
with open(idf_path, 'r', encoding='utf-8') as fd:
for line in fd:
ss = line.strip().split('t')
if len(ss) != 2:
continue
token, idf_score = ss
token_idf_dict[token] = idf_score
def get_tfidf(input_str):
token_dict = {}
# 对输入字符串的每一个词,计算tf
##计算单词在该文章出现次数
for t in input_str.strip().split(' '):
if t not in token_dict:
token_dict[t] = 1
else:
token_dict[t] += 1
print(token_dict)
# res_tu_list = [] TF-IDF=TF*IDF
for k, v in token_dict.items():
tf_score = token_dict[k]
if k not in token_idf_dict:
continue
idf_score = token_idf_dict[k]
tf_idf = tf_score * float(idf_score)
yield (k, tf_idf)
for k, v in get_tfidf(input_str):
print(k, v)
执行结果
{'我们': 2, '科技': 2, '带来': 1, '的': 1, '希望': 1, '差': 1}
我们 2.240920456387959
科技 4.378793497431945
带来 1.4617633920848578
的 0.0059113472630571645
希望 1.9419885754021315
差 3.013572191682322
分析:“科技”的TF-IDF值最高,代表该文章的关键词;“的”的TF-IDF值最低,表示该词是最常用的词,也叫"停用词"(stop words)。
未完待续。。。
参考文档:
TF-IDF原理及使用
TF-IDF与余弦相似性的应用(一):自动提取关键词
TF-IDF与余弦相似性的应用(二):找出相似文章
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
