社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本文为拉勾网《32个Java面试必考点》学习笔记.只是对视频内容进行简单整理,详细内容还请自行观看视频《32个Java面试必考点》.若本文侵犯了相关所有者的权益,请联系:txzw@live.cn.将会删除相关内容
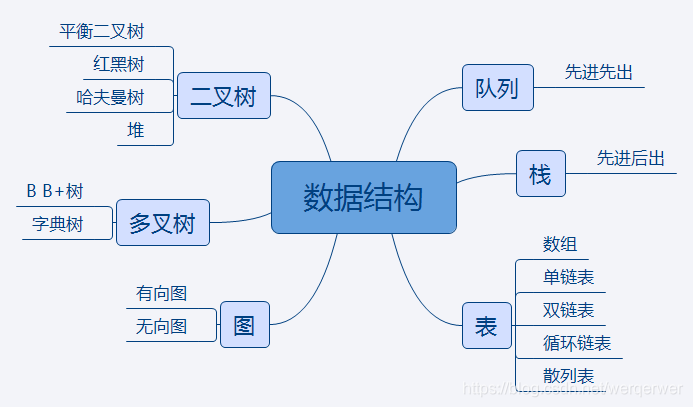
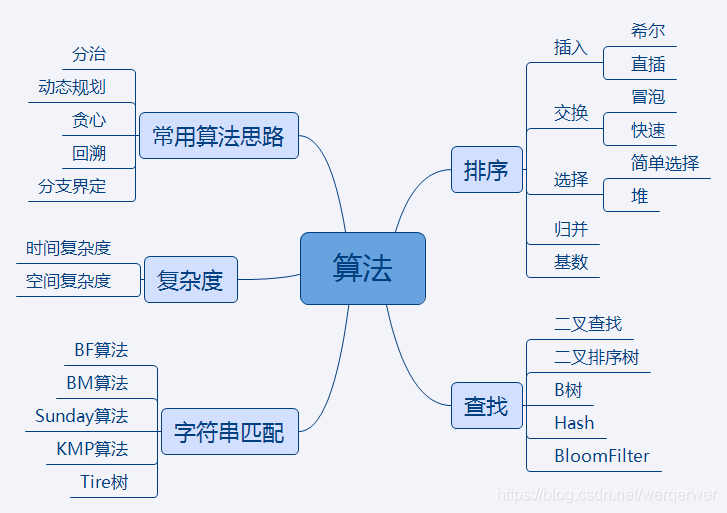
每个节点都包含一个值,每个节点至多有两棵子树,左孩子小于自己,右孩子大于自己,时间复杂度是O(log(n)),随着不断插入节点,二叉树树高变大,当只有左(右)孩子时,时间复杂度变为O(n).
保证每个节点左右子树高度差绝对值不超过1.
比如,AVL树在插入和删除数据是经常需要旋转以保持平衡.适合插入删除少场景.
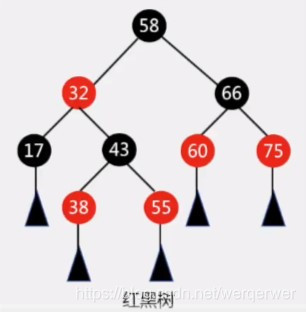
非严格平衡二叉树,更关注局部平衡,而非总体平衡,没有一条路径比其他路径长出两倍,接近平衡,减少了许多不必要的旋转操作,更加实用.
特点:
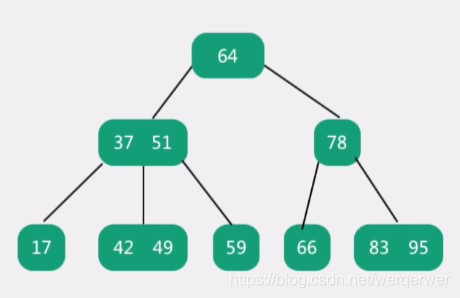
适用于文件索引,优先减少磁盘IO次数,最大子节点称为B树的阶
m阶b树特点:
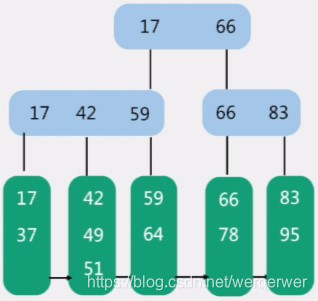
定义与b树基本相同,
区别:
B+树比B树更适合做索引:
B*树
在B+树的非叶节点上增加了指向同一层下一个非叶节点的指针
先于面试官交流,询问是否有其他要求
Example:判断给定字符串中的符号是否匹配
解题思路:
1. 使用栈
2. 遇到左括号入栈
3. 与右括号出栈,判断出栈括号是否成对
private static fianl Map<Character,Character> brackets = new HashMap<>();
static{
brackets.put(')','(');
brackets.put(']','[');
brackets.put('}','{');
}
public static boolean isMatch(String str){
if(str==null){
return false;
}
Stack<Character> stack = new stack<>();
for(char ch : str.toCharArray()){
if(barckets.containsValue(ch)){
stack.put(che);
} else if (brackets.contiansKey(ch)){
if(stack.empty() || stack.pop() != bracjets.get(ch)){
return false;
}
}
}
return stack.empty();
}
解题技巧
认真审题:
解题思路
解法:
时间复杂度:O(N*log(K))
优点:不用在内存中读入所有元素,适用于非常大的数据集
解法:
时间复杂度:O((N+K-1)*log(K))
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
