社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在之前的两次实验里,我们已经初步使用了Wireshark包嗅探器。在后续的一系列实验里,我们得训练、实践并掌握用Wireshark来查看网络协议的实践能力。在本次实验中,我们会探索HTTP协议的几个方面:基本的HTTP GET/response交互,HTTP消息格式,带条件判断的HTTP GET/response交互,基本的非常原始的HTTP认证。
探索HTTP的第一个方法是下载一个非常简单的HTML文件,这个HTML文件非常短,并且不包含嵌入的对象。执行以下操作:
通过查看HTTP GET和响应消息中的信息,回答以下实验要求的1-8题。 在回答这部分问题时,为每个题目使用一个单独的Jupyter Notebook单元格(下同)输出要求的信息。
大多数Web浏览器会使用对象(资源)缓存,从而在检索HTTP对象时执行条件GET。执行以下步骤之前,请确保浏览器的缓存为空(Firefox里按下F12然后在开发者工具窗口里禁用缓存)。
现在按下列步骤操作:
• 启动浏览器,禁用缓存。
• 启动Wireshark数据包嗅探器。
• 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html浏览器显示一个非常简单的五行HTML文件。
• 取消禁用缓存。
• 快速地将相同的URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html 输入到浏览器地址栏中并回车(或者只需在浏览器中点击刷新按钮)。
• 停止Wireshark数据包捕获,并在过滤器栏中输入“http”,以便只捕获HTTP消息,并在数据包列表窗口中显示。
回答实验要求的9-12题。
最后,我们尝试访问受密码保护的网站,并检查网站的HTTP消息交换的序列。URL http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html 是受密码保护的。用户名是“wireshark-students”(不包含引号),密码是“network”(不包含引号)。所以让我们访问这个“安全的”受密码保护的网站。执行以下操作:
• 请确保浏览器的缓存被禁用,然后关闭你的浏览器,再然后启动浏览器,再次确认浏览器的缓存被禁用。
• 启动Wireshark数据包嗅探器。
• 在浏览器中输入以下URLhttp://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html 在弹出框中键入上述的用户名和密码。成功看到如下文字:
This page is password protected! If you’re seeing this, you’ve downloaded the page correctly
Congratulations!
• 停止Wireshark数据包捕获,并在过滤器栏中输入“http”,以便只显示捕获的HTTP消息。
现在来分析Wireshark输出。
回答实验要求的13-14题。
以下解答通过故事剧情来描述
小吴的公司经常加班,偶尔回家。有一天公司项目经理要求小吴用Python分析http,给他出了14个题目,第二天给出分析结果。下班后,小吴急匆匆的回到家,啥都没管就打开电脑按照经理的要求一个劲的用wireshark抓着包。抓完包之后,小吴傻呆呆的看着自己抓的包,翻看着报文中的属性,敲着代码,看了半天也没有写出代码来,心中不禁有点发凉,这可咋整啊!这时,他隐隐约约听见从隔壁老王家传来媳妇的叫声。小吴这才发现媳妇和儿子不在家,想着代码没敲出来,也就没在意。过了一会儿,媳妇衣衫褴褛,回到了家。媳妇对小吴说给他做饭去。没过多久隔壁老王领着儿子回来了。小吴想老王说了公司经理交给他的任务,老王看着埋头苦干的一句Python代码也没写出来,老王说:“我给你点提示,你按着下面的步骤做”
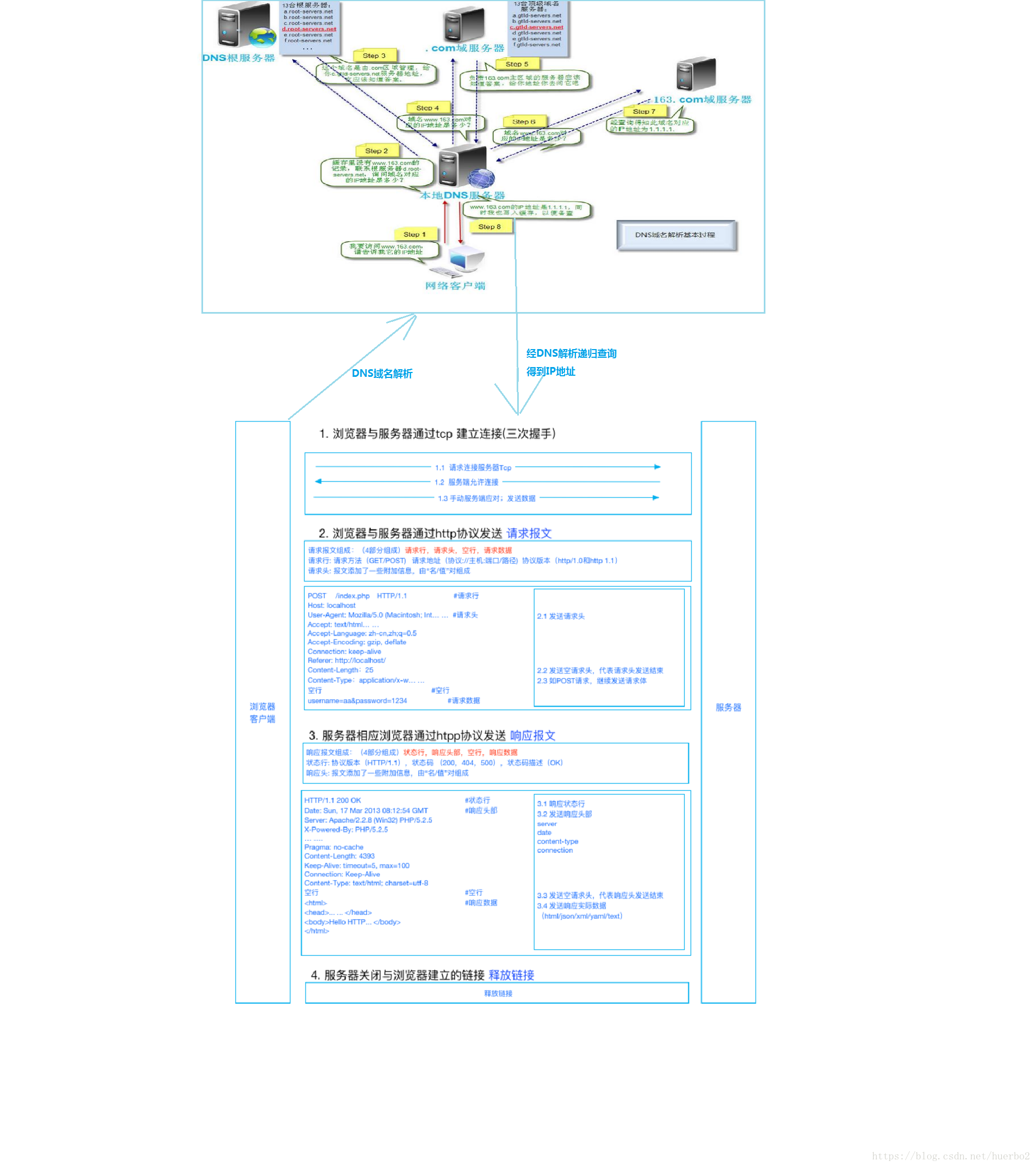
首先我们先对题目进行分析,在题目中出现最多的词语就是游览器、服务器、请求和响应,在实验一中我们就探讨了访问某个网站所经历的过程,其中就有提到游览器和服务器的关系,如下图所示。从图中我们可以看出游览器向服务器发送请求,服务器然后对游览器做出回应。因此解答本实验问题的关键之一就是游览器对应请求,服务器对应响应。
解题关键二:通过pyshark.FileCapture方法获取数据包对象cap,cap[0],cap[1]……顺序对应的就是wireshark中的一行。我们可以通过点击某一项查看来查看数据包中的内容,方便查找题目所需的属性,再通过Python代码进行输出。
小吴顺着老王的思路看了看,想了想,还真是哎!于是欣喜而疯狂的敲着代码,一口气全做完了。(老王和儿子在一旁玩的不亦乐乎。)
小吴是这么做的
小吴看着自己写的代码,看着没啥bug,暗自窃喜,非常感谢老王的指点。老王看了小吴的代码摇了摇头,说“你这样搞,明天经理会把你开除的”。小吴一脸懵逼的看着老王。老王又接着说:“你把那些cap[0],cap[1],…写死了,经理拿去测试,换个包,代码就全废了,你可以试着把请求和响应分离开”。小吴想了想,妈耶!还真是哎!心想老王真牛逼啊!改天一定要请他吃饭。于是准备开始写第二个版本。这时媳妇端了一碗热乎乎的热汤面走了过来,把面放在了桌上,和老王嘀咕了几句,然后带着儿子跟随老王出去了。小吴吃着媳妇做的热汤面,吃完就一个劲的敲着代码,完全没察觉媳妇已经不在了,以为媳妇回房间睡觉了。搞到快凌晨的时候,第二个版本出来了,怕影响媳妇睡觉就早早的上班去了。回到了公司,小吴受到了经理的嘉奖,经理还给他发了奖金。想着,这都多亏了老王啊!于是下班后拿着钱请老王吃火锅去了……………
小吴的第二个版本是这样的
- 获取数据包对象:getCapObj
- 获取所有请求和响应:getReqAndResp和getAll
- 根据索引获取单个请求和响应getSingleRequest和getSingleResponses
import pyshark
REQUEST=0
RESPONSE=1
diyFilter="http"
tsharkPath="D:/Program Files/Wireshark/tshark.exe"
def getCapObj(filePath,diyFilter,tsharkPath):
"""
#获取数据包对象
:filePath 文件路径
:diyFilter 过滤条件
:tsharkPath tshark路径
:return 返回数据包对象
"""
return pyshark.FileCapture(filePath,display_filter=diyFilter,tshark_path=tsharkPath)
def getReqAndResp(cap):
"""
#获取、分离请求和响应
:return 返回请求和响应元组
"""
requestsDict={}
responsesDict={}
for pkt in cap:
try:
responsesDict[pkt.http.request_in]=pkt
except:
requestsDict[pkt.frame_info.number]=pkt
return requestsDict,responsesDict
def getAll(filePath,diyFilter,tsharkPath,arg):
"""
:filePath 文件路径
:diyFilter 过滤条件
:tsharkPath tshark路径
:arg 标识请求和响应的参数,参数值为常量REQUEST或者RESPONSE
:return 当arg为REQUEST时返回所有请求包,为RESPONSE时返回所有响应包
"""
return getReqAndResp(getCapObj(filePath,diyFilter,tsharkPath))[arg]
def getSingleRequest(requests,index):
"""
#查找所有请求中索引为index的单个请求
:requests 所有请求
:index 索引,对应所有请求中某个请求的位置
:return 返回索引为index的单个请求
"""
return requests[list(requests.keys())[index]]
def getSingleResponses(responses,index):
"""
#查找所有响应中索引为index的单个请求
:responses 所有响应
:index 索引,对应所有响应中某个响应的位置
:return 返回索引为index的单个响应
"""
return responses[list(responses.keys())[index]]
"==================1-8题公用(全局)变量===================="
cap_file_path="./lab3_1.pcapng"
cap1_requests=getAll(cap_file_path,diyFilter,tsharkPath,REQUEST)
cap1_responses=getAll(cap_file_path,diyFilter,tsharkPath,RESPONSE)
client=cap1_requests[list(cap1_requests.keys())[0]]#在这里将游览器、本机等统一定义为客户端
server=cap1_responses[list(cap1_requests.keys())[0]]
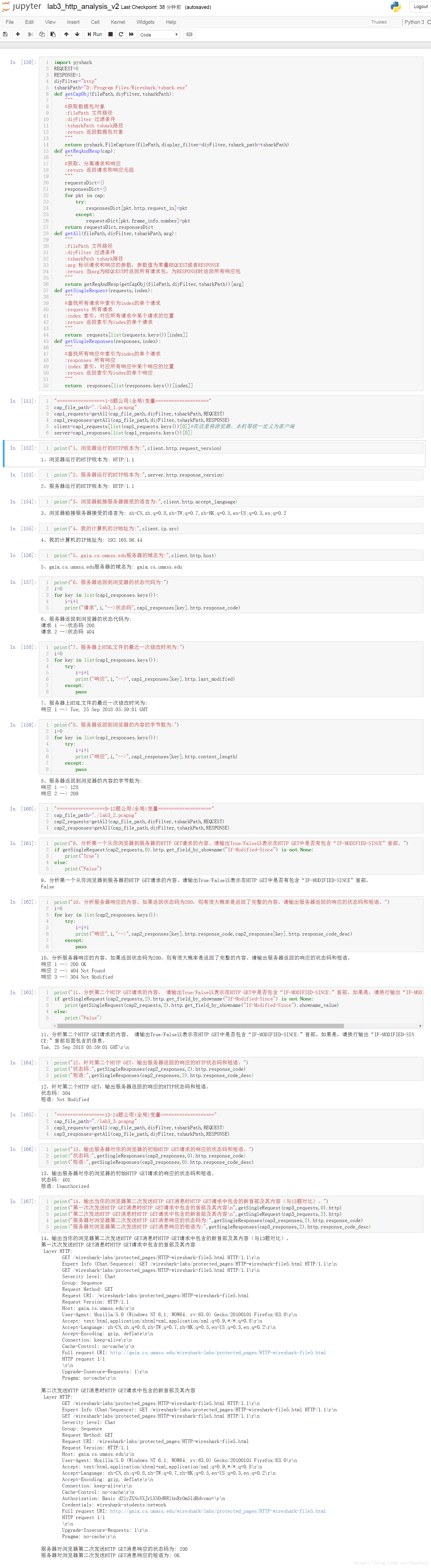
print("1、浏览器运行的HTTP版本为:",client.http.request_version)
print("2、服务器运行的HTTP版本为:",server.http.response_version)
print("3、浏览器能接服务器接受的语言为:",client.http.accept_language)
print("4、我的计算机的IP地址为:",client.ip.src)
print("5、gaia.cs.umass.edu服务器的域名为:",client.http.host)
print("6、服务器返回到浏览器的状态代码为:")
i=0
for key in list(cap1_responses.keys()):
i=i+1
print("请求",i,"-->状态码",cap1_responses[key].http.response_code)
print("7、服务器上HTML文件的最近一次修改时间为:")
i=0
for key in list(cap1_responses.keys()):
try:
i=i+1
print("响应",i,"-->",cap1_responses[key].http.last_modified)
except:
pass
print("8、服务器返回到浏览器的内容的字节数为:")
i=0
for key in list(cap1_responses.keys()):
try:
i=i+1
print("响应",i,"-->",cap1_responses[key].http.content_length)
except:
pass
"==================9-12题公用(全局)变量===================="
cap_file_path="./lab3_2.pcapng"
cap2_requests=getAll(cap_file_path,diyFilter,tsharkPath,REQUEST)
cap2_responses=getAll(cap_file_path,diyFilter,tsharkPath,RESPONSE)
print("9、分析第一个从你浏览器到服务器的HTTP GET请求的内容。请输出True/False以表示在HTTP GET中是否有包含“IF-MODIFIED-SINCE”首部。")
if getSingleRequest(cap2_requests,0).http.get_field_by_showname("If-Modified-Since") is not None:
print("True")
else:
print("False")
print("10、分析服务器响应的内容。如果返回状态码为200,则有很大概率是返回了完整的内容。请输出服务器返回的响应的状态码和短语。")
i=0
for key in list(cap2_responses.keys()):
try:
i=i+1
print("响应",i,"-->",cap2_responses[key].http.response_code,cap2_responses[key].http.response_code_desc)
except:
pass
print("11、分析第二个HTTP GET请求的内容。 请输出True/False以表示在HTTP GET中是否包含“IF-MODIFIED-SINCE:”首部。如果是,请换行输出“IF-MODIFIED-SINCE:”首部后面包含的信息。")
if getSingleRequest(cap2_requests,2).http.get_field_by_showname("If-Modified-Since") is not None:
print(getSingleRequest(cap2_requests,2).http.get_field_by_showname("If-Modified-Since").showname_value)
else:
print("False")
print("12、针对第二个HTTP GET,输出服务器返回的响应的HTTP状态码和短语。")
print("状态码:",getSingleResponses(cap2_responses,2).http.response_code)
print("短语:",getSingleResponses(cap2_responses,2).http.response_code_desc)
"==================13-14题公用(全局)变量===================="
cap_file_path="./lab3_3.pcapng"
cap3_requests=getAll(cap_file_path,diyFilter,tsharkPath,REQUEST)
cap3_responses=getAll(cap_file_path,diyFilter,tsharkPath,RESPONSE)
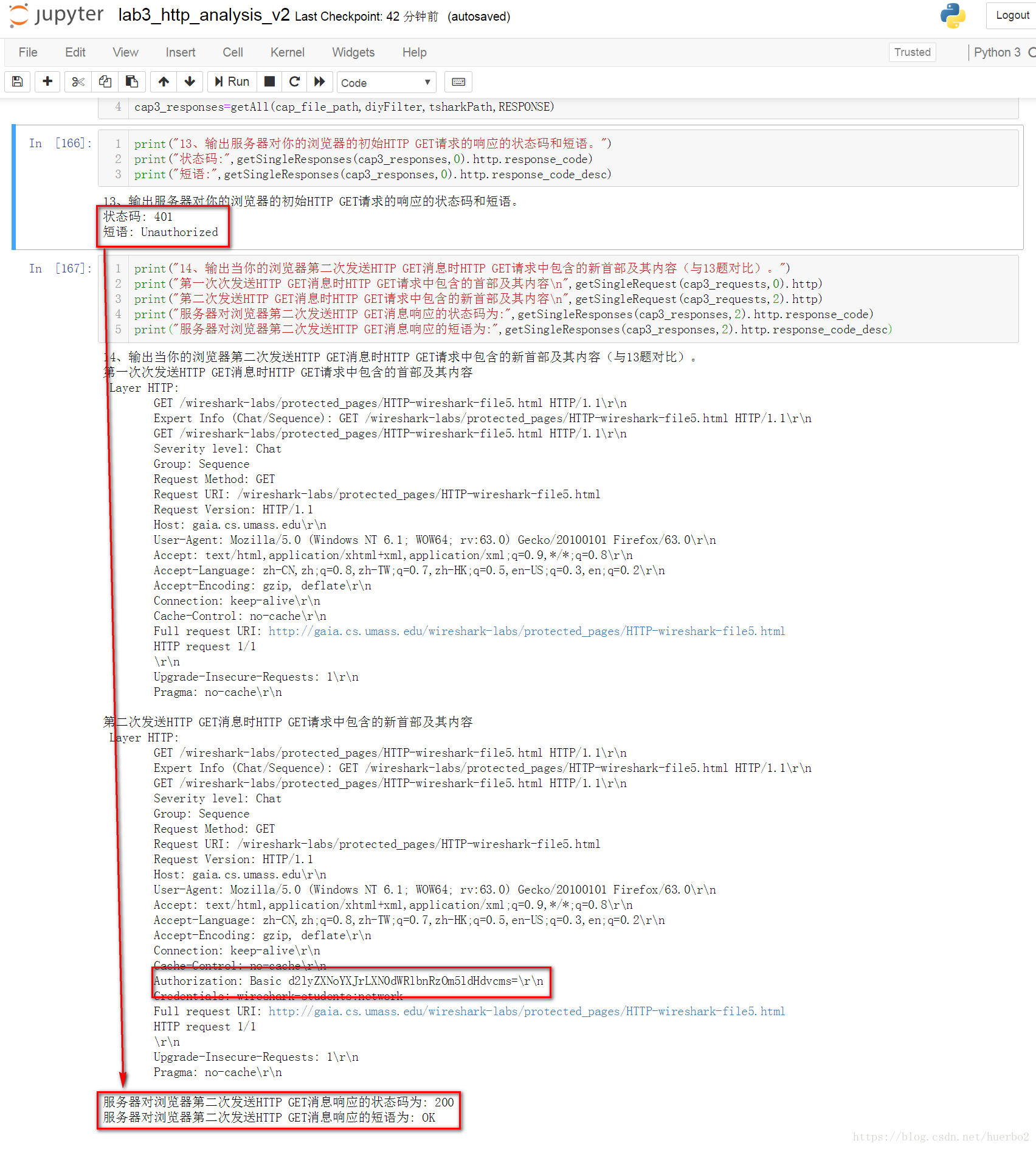
print("13、输出服务器对你的浏览器的初始HTTP GET请求的响应的状态码和短语。")
print("状态码:",getSingleResponses(cap3_responses,0).http.response_code)
print("短语:",getSingleResponses(cap3_responses,0).http.response_code_desc)
print("14、输出当你的浏览器第二次发送HTTP GET消息时HTTP GET请求中包含的新首部及其内容(与13题对比)。")
print("第一次次发送HTTP GET消息时HTTP GET请求中包含的首部及其内容n",getSingleRequest(cap3_requests,0).http)
print("第二次发送HTTP GET消息时HTTP GET请求中包含的新首部及其内容n",getSingleRequest(cap3_requests,2).http)
print("服务器对浏览器第二次发送HTTP GET消息响应的状态码为:",getSingleResponses(cap3_responses,2).http.response_code)
print("服务器对浏览器第二次发送HTTP GET消息响应的短语为:",getSingleResponses(cap3_responses,2).http.response_code_desc)
13题中服务器返回的状态码为401,短语为Unauthorized,表示未授权,是服务器对浏览器的初始HTTP GET未输入账号密码时请求的响应,14题中服务器返回的状态码为200,短语为OK,表示成功,是服务器对浏览器的第二次HTTP GET输入账号密码授权登录后请求的响应。
从上图可以看出,HTTP GET请求中包含的首部及其内容,授权登录后较登陆前多了一个Authorization,他的作用是客户端发送http请求服务器发现配置了http auth,会检查request里面有没有"Authorization"的http header,如果有,则判断Authorization里面的内容是否在用户列表里面,Authorization header的典型数据为"Authorization: Basic jdhaHY0=",其中Basic表示基础认证, jdhaHY0=是base64编码的"user:passwd"字符串。如果没有,或者用户密码不对,则返回http code 401页面给客户端。标准的http浏览器在收到401页面之后,应该弹出一个对话框让用户输入帐号密码;并在用户点确认的时候再次发出请求,这次请求里面将带上Authorization header。
本实验通过简单的Python代码来获取http请求报文和响应报文中的属性值,主要掌握的有常见的服务器响应状态码和短语代表的意义,禁用缓存和不禁用缓存的区别。特别需要的是我们在编写程序的时候应考虑代码的通用性和健壮性,不写重复代码、保证效率是对一个程序员的基本要求。
我还是个未入门的菜鸟,如果有错误的地方,欢迎指正。如果你有任何不解的地方或者有更好的实现,欢迎在下方留言评论哦。如果你觉得本篇文章对你有帮助,欢迎关注!!!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!