社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<sys/wait.h>
#include<string.h>
#include<netinet/in.h>
#include<unistd.h>
#define PROCESS_NUM 10
int main()
{
int fd = socket(PF_INET, SOCK_STREAM, 0);
int connfd;
int pid;
char sendbuff[1024];
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(1234);
bind(fd, (struct sockaddr *)&serveraddr, sizeof(serveraddr));
listen(fd, 1024);
int i;
for(i = 0; i < PROCESS_NUM; ++i){
pid = fork();
if(pid == 0){
while(1){
connfd = accept(fd, (struct sockaddr *)NULL, NULL);
snprintf(sendbuff, sizeof(sendbuff), "接收到accept事件的进程PID = %dn", getpid());
send(connfd, sendbuff, strlen(sendbuff)+1, 0);
printf("process %d accept successn", getpid());
close(connfd);
}
}
}
//int status;
wait(0);
return 0;
}

很明显当telnet连接的时候只有一个进程accept成功,你会不会和我有同样的疑问,就是会不会内核中唤醒了所有的进程只是没有获取到资源失败了,就好像惊群被“隐藏”?
这个问题很好证明,我们修改一下代码:
connfd = accept(fd, (struct sockaddr *)NULL, NULL);
if(connfd == 0){
snprintf(sendbuff, sizeof(sendbuff), "接收到accept事件的进程PID = %dn", getpid());
send(connfd, sendbuff, strlen(sendbuff)+1, 0);
printf("process %d accept successn", getpid());
close(connfd);
}else{
printf("process %d accept a connection failed: %sn", getpid(), strerror(errno));
close(connfd);
}
没错,就是增加了一个accept失败的返回信息,按照上面的步骤运行,这里我就不截图了,我只告诉你运行结果与上面的运行结果无异,增加的失败信息并没有输出,也就说明了这里并没有发生惊群,所以注意阻塞和惊群的唤醒的区别。
Google了一下:其实在linux2.6版本以后,linux内核已经解决了accept()函数的“惊群”现象,大概的处理方式就是,当内核接收到一个客户连接后,只会唤醒等待队列上的第一个进程(线程),所以如果服务器采用accept阻塞调用方式,在最新的linux系统中已经没有“惊群效应”了
accept函数的惊群解决了,下面来让我们看看存在惊群现象的另一种情况:epoll惊群
我们还是眼见为实,一步步解决上面的疑问:
代码实例:epoll_thunder_herd.c:
#include<stdio.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<unistd.h>
#include<sys/epoll.h>
#include<netdb.h>
#include<stdlib.h>
#include<fcntl.h>
#include<sys/wait.h>
#include<errno.h>
#define PROCESS_NUM 10
#define MAXEVENTS 64
//socket创建和绑定
int sock_creat_bind(char * port){
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_port = htons(atoi(port));
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(sock_fd, (struct sockaddr *)&serveraddr, sizeof(serveraddr));
return sock_fd;
}
//利用fcntl设置文件或者函数调用的状态标志
int make_nonblocking(int fd){
int val = fcntl(fd, F_GETFL);
val |= O_NONBLOCK;
if(fcntl(fd, F_SETFL, val) < 0){
perror("fcntl set");
return -1;
}
return 0;
}
int main(int argc, char *argv[])
{
int sock_fd, epoll_fd;
struct epoll_event event;
struct epoll_event *events;
if(argc < 2){
printf("usage: [port] %s", argv[1]);
exit(1);
}
if((sock_fd = sock_creat_bind(argv[1])) < 0){
perror("socket and bind");
exit(1);
}
if(make_nonblocking(sock_fd) < 0){
perror("make non blocking");
exit(1);
}
if(listen(sock_fd, SOMAXCONN) < 0){
perror("listen");
exit(1);
}
if((epoll_fd = epoll_create(MAXEVENTS))< 0){
perror("epoll_create");
exit(1);
}
event.data.fd = sock_fd;
event.events = EPOLLIN;
if(epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &event) < 0){
perror("epoll_ctl");
exit(1);
}
/*buffer where events are returned*/
events = calloc(MAXEVENTS, sizeof(event));
int i;
for(i = 0; i < PROCESS_NUM; ++i){
int pid = fork();
if(pid == 0){
while(1){
int num, j;
num = epoll_wait(epoll_fd, events, MAXEVENTS, -1);
printf("process %d returnt from epoll_waitn", getpid());
sleep(2);
for(i = 0; i < num; ++i){
if((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events & EPOLLIN))){
fprintf(stderr, "epoll errorn");
close(events[i].data.fd);
continue;
}else if(sock_fd == events[i].data.fd){
//收到关于监听套接字的通知,意味着一盒或者多个传入连接
struct sockaddr in_addr;
socklen_t in_len = sizeof(in_addr);
if(accept(sock_fd, &in_addr, &in_len) < 0){
printf("process %d accept failed!n", getpid());
}else{
printf("process %d accept successful!n", getpid());
}
}
}
}
}
}
wait(0);
free(events);
close(sock_fd);
return 0;
}
上面的代码编译gcc epoll_thunder_herd.c -o server
一个终端运行代码 ./server 1234 另一个终端telnet 127.0.0.1 1234
运行结果:
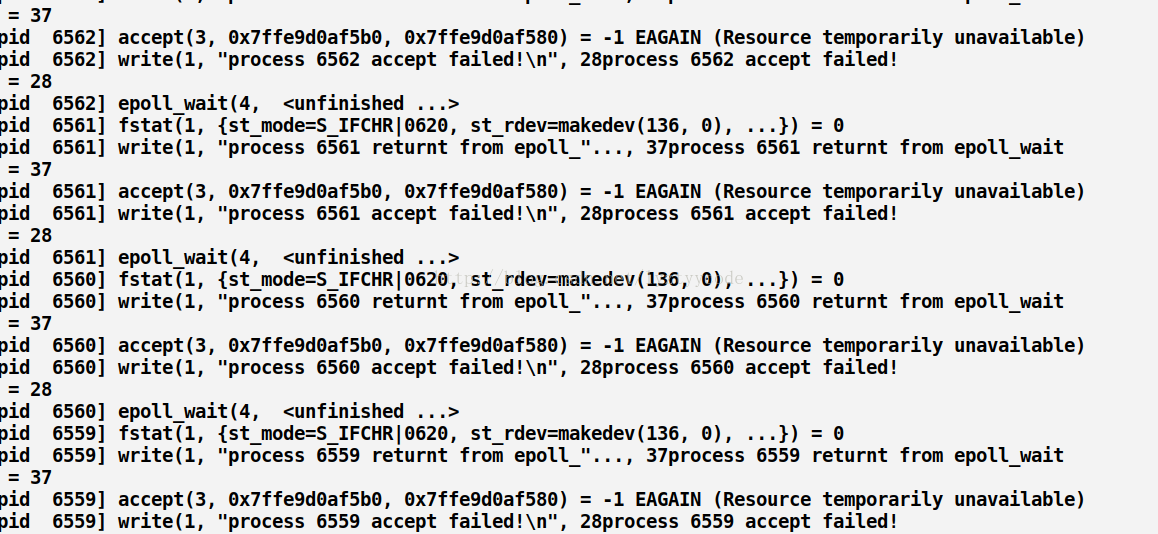
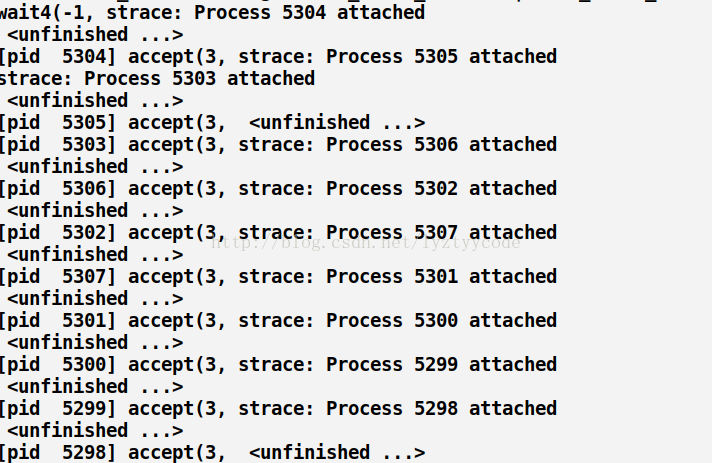
这里我们看到只有一个进程返回了,似乎并没有惊群效应,让我们用strace -f ./server 8888追踪执行过程(这里只给出telnet之后的截图,之前的截图参考accept,不同的就是进程阻塞在epoll_wait)
截图(部分):
运行结果显示了部分个进程被唤醒了,返回了“process accept failed”只是后面因为某些原因失败了。所以这里貌似存在部分“惊群”。
怎么判断发生了惊群呢?
我们根据strace的返回信息可以确定:
1)系统只会让一个进程真正的接受这个连接,而剩余的进程会获得一个EAGAIN信号。图中有体现。
2)通过返回结果和进程执行的系统调用判断。
这究竟是什么原因导致的呢?
看我们的代码,看似部分进程被唤醒了,而事实上其余进程没有被唤醒的原因是因为某个进程已经处理完这个事件,无需唤醒其他进程,你可以在epoll获知这个事件的时候sleep(2);这样所有的进程都会被唤起。看下面改正后的代码结果更加清晰:
代码修改:
num = epoll_wait(epoll_fd, events, MAXEVENTS, -1);
printf("process %d returnt from epoll_waitn", getpid());
sleep(2);
运行结果:
如图所示:所有的进程都被唤醒了。所以epoll_wait的惊群确实存在。
为什么内核处理了accept的惊群,却不处理epoll_wait的惊群呢?
printf("初始的红包情况:<个数:%d 金额:%d.%02d>n",item.number, item.total/100, item.total%100);
pthread_cond_broadcast(&temp.cond);//红包包好后唤醒所有线程抢红包
pthread_mutex_unlock(&temp.mutex);//解锁
sleep(1);
void ngx_process_events_and_timers(ngx_cycle_t *cycle)
{
... ...
// 是否通过对accept加锁来解决惊群问题,需要工作线程数>1且配置文件打开accetp_mutex
if (ngx_use_accept_mutex) {
// 超过配置文件中最大连接数的7/8时,该值大于0,此时满负荷不会再处理新连接,简单负载均衡
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
// 多个worker仅有一个可以得到这把锁。获取锁不会阻塞过程,而是立刻返回,获取成功的话
// ngx_accept_mutex_held被置为1。拿到锁意味着监听句柄被放到本进程的epoll中了,如果
// 没有拿到锁,则监听句柄会被从epoll中取出。
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
// 此时意味着ngx_process_events()函数中,任何事件都将延后处理,会把accept事件放到
// ngx_posted_accept_events链表中,epollin|epollout事件都放到ngx_posted_events链表中
flags |= NGX_POST_EVENTS;
} else {
// 拿不到锁,也就不会处理监听的句柄,这个timer实际是传给epoll_wait的超时时间,修改
// 为最大ngx_accept_mutex_delay意味着epoll_wait更短的超时返回,以免新连接长时间没有得到处理
if (timer == NGX_TIMER_INFINITE || timer > ngx_accept_mutex_delay) {
timer = ngx_accept_mutex_delay;
}
}
}
}
... ...
(void) ngx_process_events(cycle, timer, flags); // 实际调用ngx_epoll_process_events函数开始处理
... ...
if (ngx_posted_accept_events) { //如果ngx_posted_accept_events链表有数据,就开始accept建立新连接
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
}
if (ngx_accept_mutex_held) { //释放锁后再处理下面的EPOLLIN EPOLLOUT请求
ngx_shmtx_unlock(&ngx_accept_mutex);
}
if (delta) {
ngx_event_expire_timers();
}
ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "posted events %p", ngx_posted_events);
// 然后再处理正常的数据读写请求。因为这些请求耗时久,所以在ngx_process_events里NGX_POST_EVENTS标
// 志将事件都放入ngx_posted_events链表中,延迟到锁释放了再处理。
}}Linux内核的3.9版本带来了SO_REUSEPORT特性,该特性支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,允许多个套接字bind()以及listen()同一个TCP或UDP端口,并且在内核层面实现负载均衡。
在未开启SO_REUSEPORT的时候,由一个监听socket将新接收的连接请求交给各个工作者处理,看图示:

运行在Linux系统上的网络应用程序,为了利用多核的优势,一般使用以下典型的多进程(多线程)服务器模型:
1.单线程listener/accept,多个工作线程接受任务分发,虽然CPU工作负载不再成为问题,但是仍然存在问题:
(1)、单线程listener(图一),在处理高速率海量连接的时候,一样会成为瓶颈
(2)、cpu缓存行丢失套接字结构现象严重。
2.所有工作线程都accept()在同一个服务器套接字上呢?一样存在问题:
(1)、多线程访问server socket锁竞争严重。
(2)、高负载情况下,线程之间的处理不均衡,有时高达3:1。
(3)、导致cpu缓存行跳跃(cache line bouncing)。
(4)、在繁忙cpu上存在较大延迟。
上面两种方法共同点就是很难做到cpu之间的负载均衡,随着核数的提升,性能并没有提升。甚至服务器的吞吐量CPS(Connection Per Second)会随着核数的增加呈下降趋势。
下面我们就来看看SO_REUSEPORT解决了什么问题:
(1)、允许多个套接字bind()/listen()同一个tcp/udp端口。每一个线程拥有自己的服务器套接字,在服务器套接字上没有锁的竞争。
(2)、内核层面实现负载均衡
(3)、安全层面,监听同一个端口的套接字只能位于同一个用户下面。
(4)、处理新建连接时,查找listener的时候,能够支持在监听相同IP和端口的多个sock之间均衡选择。
当一个连接到来的时候,系统到底是怎么决定那个套接字来处理它?
对于不同内核,存在两种模式,这两种模式并不共存,一种叫做热备份模式,另一种叫做负载均衡模式,3.9内核以后,全部改为负载均衡模式。
热备份模式:一般而言,会将所有的reuseport同一个IP地址/端口的套接字挂在一个链表上,取第一个即可,工作的只有一个,其他的作为备份存在,如果该套接字挂了,它会被从链表删除,然后第二个便会成为第一个。
负载均衡模式:和热备份模式一样,所有reuseport同一个IP地址/端口的套接字会挂在一个链表上,你也可以认为是一个数组,这样会更加方便,当有连接到来时,用数据包的源IP/源端口作为一个HASH函数的输入,将结果对reuseport套接字数量取模,得到一个索引,该索引指示的数组位置对应的套接字便是工作套接字。这样就可以达到负载均衡的目的,从而降低某个服务的压力。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!