社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
双线性插值算法【文章主体内容为转载,代码为自己所写】,在这里也感谢一些大牛的博文。
http://www.cnblogs.com/linkr/p/3630902.html
http://www.cnblogs.com/funny-world/p/3162003.html
双线性插值
假设源图像大小为mxn,目标图像为axb。那么两幅图像的边长比分别为:m/a和n/b。注意,通常这个比例不是整数,编程存储的时候要用浮点型。目标图像的第(i,j)个像素点(i行j列)可以通过边长比对应回源图像。其对应坐标为(i*m/a,j*n/b)。显然,这个对应坐标一般来说不是整数,而非整数的坐标是无法在图像这种离散数据上使用的。双线性插值通过寻找距离这个对应坐标最近的四个像素点,来计算该点的值(灰度值或者RGB值)。
若图像为灰度图像,那么(i,j)点的灰度值的数学计算模型是:
f(x,y)=b1+b2x+b3y+b4xy
其中b1,b2,b3,b4是相关的系数。关于其的计算过程如下如下:
如图,已知Q12,Q22,Q11,Q21,但是要插值的点为P点,这就要用双线性插值了,首先在x轴方向上,对R1和R2两个点进行插值,这个很简单,然后根据R1和R2对P点进行插值,这就是所谓的双线性插值。

附:维基百科–双线性插值:
双线性插值,又称为双线性内插。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。
假如我们想得到未知函数  在点
在点 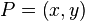 的值,假设我们已知函数 在
的值,假设我们已知函数 在  ,
,  ,
,  ,
及
,
及  四个点的值。
四个点的值。
首先在 x 方向进行线性插值,得到

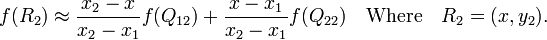
然后在 y 方向进行线性插值,得到
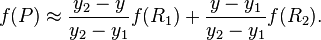
这样就得到所要的结果  ,
,
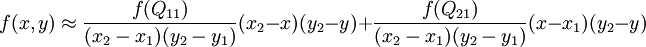

如果选择一个坐标系统使得 的四个已知点坐标分别为 (0, 0)、(0, 1)、(1, 0) 和 (1, 1),那么插值公式就可以化简为
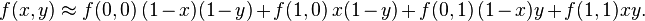
或者用矩阵运算表示为

这种插值方法的结果通常不是线性的,线性插值的结果与插值的顺序无关。首先进行 y 方向的插值,然后进行 x 方向的插值,所得到的结果是一样的。
opencv和Matlab中的双线性插值
这部分的前提是,你已经明白什么是双线性插值并且在给定源图像和目标图像尺寸的情况下,可以用笔计算出目标图像某个像素点的值。当然,最好的情况是你已经用某种语言实现了网上一大堆博客上原创或转载的双线性插值算法,然后发现计算出来的结果和matlab、openCV对应的resize()函数得到的结果完全不一样。
那这个究竟是怎么回事呢?
其实答案很简单,就是坐标系的选择问题,或者说源图像和目标图像之间的对应问题。
按照网上一些博客上写的,源图像和目标图像的原点(0,0)均选择左上角,然后根据插值公式计算目标图像每点像素,假设你需要将一幅5x5的图像缩小成3x3,那么源图像和目标图像各个像素之间的对应关系如下:

只画了一行,用做示意,从图中可以很明显的看到,如果选择右上角为原点(0,0),那么最右边和最下边的像素实际上并没有参与计算,而且目标图像的每个像素点计算出的灰度值也相对于源图像偏左偏上。
那么,让坐标加1或者选择右下角为原点怎么样呢?很不幸,还是一样的效果,不过这次得到的图像将偏右偏下。
最好的方法就是,两个图像的几何中心重合,并且目标图像的每个像素之间都是等间隔的,并且都和两边有一定的边距,这也是matlab和openCV的做法。如下图:

如果你不懂我上面说的什么,没关系,只要在计算对应坐标的时候改为以下公式即可,
int x=(i+0.5)*m/a-0.5
int y=(j+0.5)*n/b-0.5
代替
int x=i*m/a
int y=j*n/b
利用上述公式,将得到正确的双线性插值结果
实现代码
# --*-- encoding: utf-8 --*--
'''
Date: 2018.09.13
Content: python3 实现双线性插值图像缩放算法
'''
import numpy as np
import cv2
import math
def bi_linear(src, dst, target_size):
pic = cv2.imread(src) # 读取输入图像
th, tw = target_size[0], target_size[1]
emptyImage = np.zeros(target_size, np.uint8)
for k in range(3):
for i in range(th):
for j in range(tw):
# 首先找到在原图中对应的点的(X, Y)坐标
corr_x = (i+0.5)/th*pic.shape[0]-0.5
corr_y = (j+0.5)/tw*pic.shape[1]-0.5
# if i*pic.shape[0]%th==0 and j*pic.shape[1]%tw==0: # 对应的点正好是一个像素点,直接拷贝
# emptyImage[i, j, k] = pic[int(corr_x), int(corr_y), k]
point1 = (math.floor(corr_x), math.floor(corr_y)) # 左上角的点
point2 = (point1[0], point1[1]+1)
point3 = (point1[0]+1, point1[1])
point4 = (point1[0]+1, point1[1]+1)
fr1 = (point2[1]-corr_y)*pic[point1[0], point1[1], k] + (corr_y-point1[1])*pic[point2[0], point2[1], k]
fr2 = (point2[1]-corr_y)*pic[point3[0], point3[1], k] + (corr_y-point1[1])*pic[point4[0], point4[1], k]
emptyImage[i, j, k] = (point3[0]-corr_x)*fr1 + (corr_x-point1[0])*fr2
cv2.imwrite(dst, emptyImage)
# 用 CV2 resize函数得到的缩放图像
new_img = cv2.resize(pic, (200, 300))
cv2.imwrite('pic/1_cv_img.png', new_img)
def main():
src = 'pic/raw_1.jpg'
dst = 'pic/new_1.png'
target_size = (300, 200, 3) # 变换后的图像大小
bi_linear(src, dst, target_size)
if __name__ == '__main__':
main()如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
