社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群

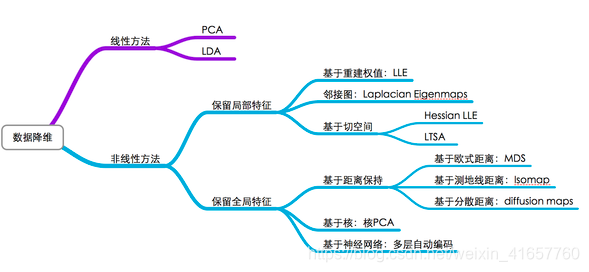
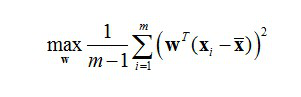
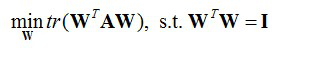
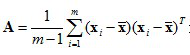
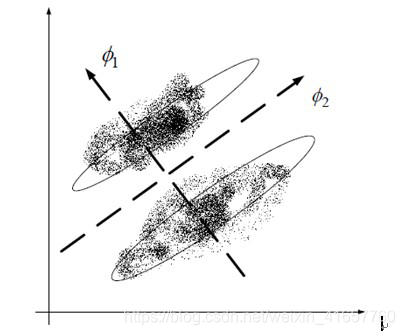
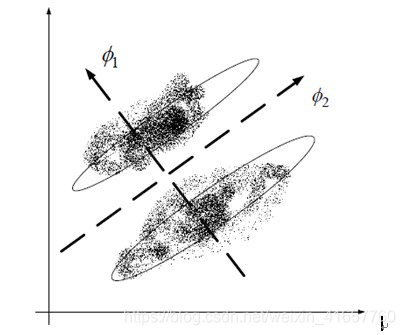
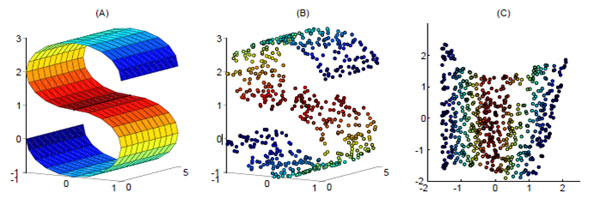
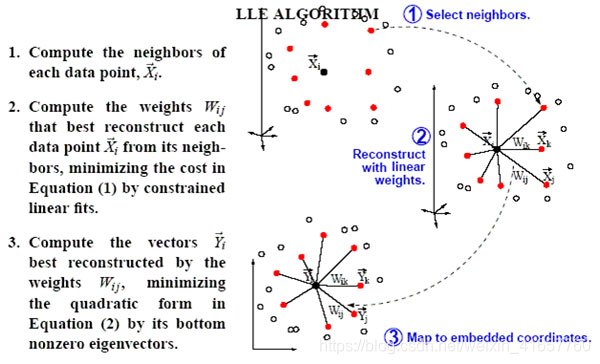
学习器的学习能力和泛化能力是由学习器的算法和数据的内在结构共同决定的。对于学习器的算法,不同的参数设置能导致算法生成不同的模型,如何评估一个模型的好坏,我们通常从其泛化误差来进行评估。
泛化误差的定义是学习器在新样本上的误差,而新样本我们通常是不知道其真实输出的,那么如何评估呢?为此,通常在训练集中分出一部分数据,这些并不参与学习器的学习,而是使用其他的剩余样本来训练样本,用这些选出来的样本进行泛化误差的计算。这些被选出来的样本我们称之为验证集(testing set)因为我们假设验证样本的是从真实样本中独立同分布的采样而来,从而可以将测试误差当作泛化误差的近似。
给定一个数据集D={(x1,y1),(x2,y2),⋅⋅⋅,(xm,ym)},如何从中选出我们所需的训练集S和验证集T呢?常用的方法有以下几种。
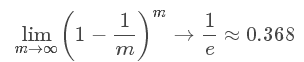
L2范数是指向量各元素的平方和然后求平方根。可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。L2正则项起到使得参数w变小加剧的效果,但是为什么可以防止过拟合呢?一个通俗的理解便是:更小的参数值w意味着模型的复杂度更低,对训练数据的拟合刚刚好(奥卡姆剃刀),不会过分拟合训练数据,从而使得不会过拟合,以提高模型的泛化能力。还有就是看到有人说L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。
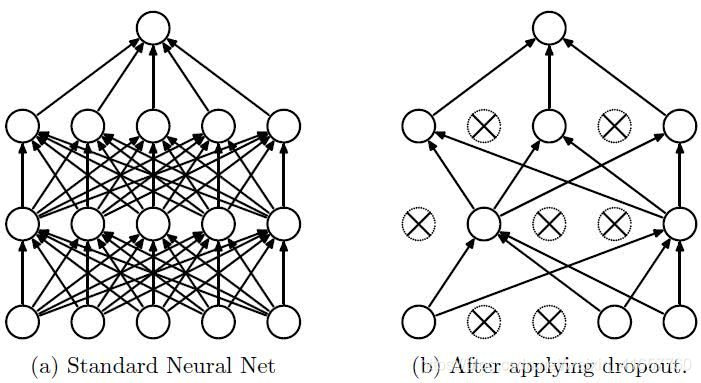
(5)采用dropout方法。这个方法在神经网络里面很常用。dropout方法是ImageNet中提出的一种方法,通俗一点讲就是dropout方法在训练的时候让神经元以一定的概率不工作。具体看下图:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
