社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Hi,大家好,这是我第一篇博客。
作为非专业程序小白,博客内容必然有不少错误之处,还望各位大神多多批评指正。
在开始正式内容想先介绍下自己和一些异想天开的想法。
我是一名研究生,研究的方向是蛋白质结构与功能方向。在研究过程中发现生物系统是如此复杂,犹如一张网,信息流动,彼此相连,于是对复杂系统产生了兴趣,越发感觉生命的本质就是信息啊。后来看了一部电影叫做《创战纪》,男主的父亲便是创造了一个数字世界,在这个数字世界里进化出了数字生命(我们漂亮可爱的女主),虽然只是科幻,还是让我感到非常的震撼。正如《异次元骇客》里所讲的在科技发展到一定程度之后是不是也可以创造出一个数字世界呢,而我们的世界会不会也是另一个意义上的数字世界呢,是由更高层的世界的人(GOD)创造的呢?因为我们可以清晰的发现这个世界是有层次的,又是自相似的。从最底层的物理学研究的弦,夸克,原子,力,场等世界基本元素到化学研究的各种分子,化学反应再到生物学研究的由各种生命小分子按特定信息构建的核酸,蛋白质,细胞,组织,器官,个体,最终是由个体构成的群体,以人为例,即社会及其衍生出来的经济体系,文化体系,政治体系等。所有的层次都是在上一个层次的基础上构建的,彼此相似但又都涌现出新的特性,这便是这个世界的复杂性。我心中坚信所有复杂的事物都是由简单的事物构成的,也坚信这个世界必有其最底层的元素与规则(就如同计算机里面的0和1以及布尔逻辑运算),经过无数次的迭代演化(时间真的是个很神奇的物理量),变成了如今这个复杂多变的世界。而现在的科学就是在各个层次上研究这些元素和规则,如果有一天能够找到最底层的元素与规则,也许可以重构另一个数字的世界。这算是我一个遥远的梦吧,估计是很难实现了,但如果有机会我还是会为之奋斗的。
哈哈,脑洞开完了,现在回归现实。为了更靠近一点我的梦想,我打算从现在最火的机器学习学起,于是报名了一些课程,了解了一些基本的机器学习知识。不过奈何数学基础太差,程序语言也没有学过,所以学起来还是有些吃力。后来老师推荐了kaggle 竞赛,里面有很多项目,对熟悉数据处理与学习各种算法帮助很大。便参加了kaggle 上最为经典的泰坦尼克号生存预测项目,期间自己探索了一些,也拜读了一些大神的作品,感觉收获蛮大。为了不至于忘掉,在此做个总结,并希望与大家交流探讨。
1.项目基本信息
项目的背景是大家都熟知的发生在1912年的泰坦尼克号沉船灾难,这次灾难导致2224名船员和乘客中有1502人遇难。而哪些人幸存那些人丧生并非完全随机。比如说你碰巧搭乘了这艘游轮,而你碰巧又是一名人见人爱,花见花开的一等舱小公主,那活下来的概率就很大了,但是如果不巧你只是一名三等舱的抠脚大汉,那只有自求多福了。也就是说在这生死攸关的情况下,生存与否与性别,年龄,阶层等因素是有关系的,如果把这些因素作为特征,生存的结果作为预测目标,就可以建立一个典型的二分类机器学习模型。在这个项目中提供了部分的乘客名单,包括各种维度的特征以及是否幸存的标签,存在train.csv文件中,这是我们训练需要的数据;另一个test.csv文件是我们需要预测的乘客名单,只有相应的特征。我们要做的工作就是通过对训练数据的特征与生存关系进行探索,构建合适的机器学习的模型,再用这个模型预测测试文件中乘客的幸存情况,并将结果保存提交给kaggle。
2.数据集初步探索
#首先导入需要的库
import numpy as np
import pandas as pd
from IPython.display import display
%matplotlib inline
import seaborn as sns
#导入并展示训练数据和测试数据
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
display(train.head(n=1),test.head(n=1))
output1:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.25 | NaN | S |
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
从运行结果看,导入已经成功,我们可以大体瞄一眼数据的特征,与训练集相比测试集很相似,只是多了Survived 标签。
接下来我们进一步了解数据的整体特征
#查看数据信息:
train.info()
test.info()output2:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB从结果可以看到,训练数据集有891个样本(样本量不大,要在模型训练过程中小心过拟合),11个特征和1个标签,其中特征‘Age','Cabin','Embarked'都有不同程度的缺损;测试集有418个样本,只有11个特征,其中特征'Age','Fare','Cabin'有不同程度的缺损。
对这些缺损的数据可以选择的处理方式由简到难包括:
1.直接删除此特征(缺损数据太多的情况,防止引入噪声)
2.直接删除缺损数据的样本(~土豪操作~只用于训练数据集,且样本量较大,缺损数据样本较少的情况)
3.直接将有无数值作为新的特征(数据缺失较多,且数据有无本身是对预测是一个有用的特征)
4.中值或均值回补(缺失数据较多,不想损失此较多训练数据,特征又比较重要的情况,是比较常用的方法)
5.参考其他特征,利用与此特征的相关性编写算法回补数据(~大神级操作~回补的准确性可能会比较高一些,但实现过程复杂)
这几种方法具体使用哪一个需要根据实际情况决定,选用复杂的方法得到的结果不一定就好。
再来观察这11个特征的类型,其中有4个特征,包括:'PassengerId','Pclass’,'Sibsp','Parch'属于整数型数据,5个特征,包括:'Name','Sex','Ticket','Cabin','Embarked'属于字符串类型数据,2个特征,包括:'Age','Fare'属于浮点数。然而这些数据格式并不都是机器学习模型的菜,你直接喂给模型字符串数据,它会吐的!所以为统一数据格式,方便模型训练,我们下面还需要对这些特征数据进行缩放和转化。
至此我们对数据已经有了大体的了解,接下来我们探讨特征与标签的关系
3.特征分析与处理
特征分析与处理是得到好模型的关键一步。而做好这一步需要深刻洞悉数据的模式,挖掘出数据的本质特征,所以据说很多在kaggle上取得高分的大神都是在具体项目上有些Domain knowledge的人,所以能找到更本质更精华的特征,喂给训练模型,自然成绩很好(吃的好自然壮嘛),而那些喂了很多粗粮(相关性不大的特征)的模型,即便算法再努力锻炼,也只是rubbish in,rubbish out,练不出八块腹肌的 (%>_<%)
好了,言归正传,现在开始特征的分析。
首先这个数据集有11个特征,我们一个个来看:
1.'PassengerId' 乘客的Id,什么鬼,肯定是rubbish啦。。。果断删掉
2.'Pclass’社会阶层,感觉应该很重要,贵族阶层活下来的可能性肯定更大啊。我们代码看下
#采用seaborn绘图函数库作可视化分析
sns.countplot(x="Pclass", hue="Survived", data=train)output3:
从上图可以看出Pclass属性为1的人生存的机会要高于或远高于属性为2或3的人,果然。。。
3.'Name' 姓名,中国农村以前有句老话,说取得名越贱,越容易活,所以很多人家的娃,叫二狗子。。。(生活不易啊),但名字真的和生存率有关系吗?我自己探索的时候是直接把这一项作为rubbish 删掉了,后来拜读一些大神作品时发现名字里面的title还是大有学问的,可以挖掘出性别,年龄,婚否以及社会地位等信息,大神就是大神,再次膜拜一下。
4.‘Sex' 性别 , ‘Lady First’是一条世界范围都要遵循的优良道德品质,所以猜测女性在这种情况下活下来的概率更大是合理的,让我们来看看在这性命攸关的时刻,泰坦尼克号上gentlemen 的表现:
sns.countplot(x="Sex", hue="Survived", data=train)output4:
从结果看大部分的lady都活下来了,大部分的gentleman都挂了。。。
5.’Age' 年龄,除了妇女,孩子和老人在出现危险的时候也是优先被救助的对象,尊老爱幼应该不只是中华民族的传统美德吧(虽然经常听说外国人很独立,不靠父母不靠娃),所以猜测不同年龄段的人被救助的概率应该不同。So, Let's See...
Wait...这个特征好像有些麻烦,俩问题:1.数值有缺损,2.年龄是个连续变量,这要如何解决呢
问题1就要用到我们上面的缺损数据处理方法了,用哪个方法呢,考虑到我不是大神,方法5首先排除,年龄特征很重要肯定不能直接删,缺损的数据样本也比较多(177个),不可能土豪到直接删掉缺损样本(训练集本来就小,穷啊。。),所以方法1,2都不靠谱。那现在就只剩下方法3,4两种了,选哪个呢,纠结啊。。。扔硬币吧。。。正面。。。选3.。。。嗯,是不是太草率了,算了,还是作图看一眼吧
#将有年龄数值的转化为yes,缺损的转化为no
train['Age']=train['Age'].map(lambda x:'yes' if 0<x<100 else 'no')
#作图比较
sns.countplot(x="Age", hue="Survived", data=train)
output5:
貌似有年龄数值的存活的几率要高一些,可以用操作3的方法处理(扔到反面的小伙伴也可以选择操作4,哈哈),那么我们暂且把没有年龄数值的作为一类新特征。
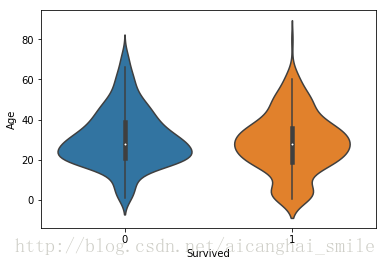
那么第二个问题,由于年龄是一个连续变量,我们需要对年龄分段进行考察,那如何分段呢,我们可以用Seaborn 函数库作一个小提琴图先瞅一眼:
#再次导入原训练集
train=pd.read_csv('train.csv')
#作小提琴图
sns.violinplot(x='Survived',y='Age',data=train)output6:
PS:
从叠加图(有哪位大神可以告诉我怎么做这种叠加的图,我居然是用PS搞定的。。)中我们可以发现大概年龄在12岁以下的孩子生存率要高一些,而年龄12-30岁左右的人死亡率是很高的,30-60岁感觉生存与死亡大体相等,60-75岁死亡率又稍稍上升,75岁以上基本存活。加上之前没有年龄数值的也可以分为一类,总共分了6类。
#年龄特征分类
train['Age']=train['Age'].map(lambda x: 'child' if x<12 else 'youth' if x<30 else 'adlut' if x<60 else 'old' if x<75 else 'tooold' if x>=75 else 'null')6.'Sibsp' 兄弟姐妹和配偶的数量,这个特征嘛感觉多少会有些影响,作图看看:
sns.countplot(x="SibSp", hue="Survived", data=train)output7:
从图中结果可以看到大部分人这一属性都为0,而为1,2的情况下貌似幸存大概率会增加,再大又会下降,所以这个特征可以分成三部分,代码如下:
train['SibSp']=train['SibSp'].map(lambda x: 'small' if x<1 else 'middle' if x<3 else 'large')
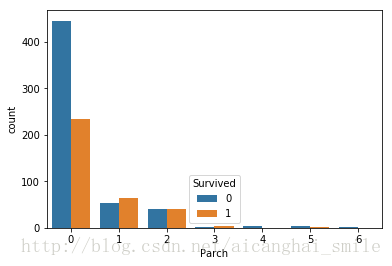
7.'Parch' 父母以及小孩的数量,这个特征和上一个很类似,估计分布也会很类似,我们看一下:
sns.countplot(x="Parch", hue="Survived", data=train)
output8:
果然,有父母孩子的比单独旅行的幸存率的确要高,我们同样把这个特征分成三部分
train['Parch']=train['Parch'].map(lambda x: 'small' if x<1 else 'middle' if x<4 else 'large')
8.‘Ticket’ 船票编号,感觉又像是一个rubbish 的特征,不过据说有大神也可以从中挖出不少东西,可能不同的船票也反映了一些社会阶层的信息?感觉蛮复杂的,这里就先舍弃这个特征了。
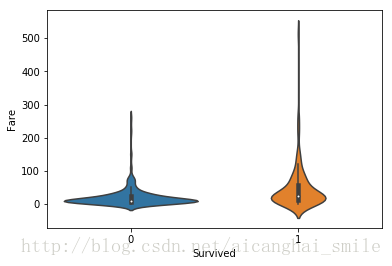
9. 'Fare' 船票的花费,这个特征还是有用的,因为花费多少往往与乘客的社会地位有关系,我们作小提琴图看一下:
sns.violinplot(x='Survived',y='Fare',data=train)
output9:
丑啊。。。从图中我们看到这个特征的分布很不均匀,需要先做一下对数转化
#用numpy库里的对数函数对Fare的数值进行对数转换
train['Fare']=train['Fare'].map(lambda x:np.log(x+1))
#作小提琴图:
sns.violinplot(x='Survived',y='Fare',data=train)
output10:
嗯,现在正常多了,PS叠加
可以很明显的发现当log(Fare)小于2.5时,死亡率是高于生存率的,而大于2.5的生存率是高于死亡率的,因此可以做如下分类:
train['Fare']=train['Fare'].map(lambda x: 'poor' if x<2.5 else 'rich')
10. 'Cabin' 船舱的编号,这个特征的数值缺损太严重,可以直接删除这个特征,也可以采用操作3的方法,我们先来看看缺损的数值能否反映出生存率:
#有编号的的为yes,没有的为no
train['Cabin']=train['Cabin'].map(lambda x:'yes' if type(x)==str else 'no')
#作图
sns.countplot(x="Cabin", hue="Survived", data=train)
output11:
从图中我们发现相对这个数据缺损的样本,有数据样本的存活率要高出很多,所以暂且可以将Cabin 特征分成这两类
11. 'Embarked' 乘客上船的港口,这个特征感觉跟生存率没啥关系,不过谁知道呢,保险起见还是看一下:
sns.countplot(x="Embarked", hue="Survived", data=train)
output12:
恩,这个特征还是有些用处的,可以看见在C港口上船的人貌似生存率高一些,难道在那个港口上船的有钱人多一些??这个特征先保留。同时我们注意到这个特征有两个数据的缺损,由于缺损样本数较少,这里土豪一把,就直接删除这两个样本。。爽!
#删掉含有缺损值的样本
train.dropna(axis=0,inplace=True)
#查看训练集的信息
train.info()
output13:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 889 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 889 non-null int64
Survived 889 non-null int64
Pclass 889 non-null int64
Name 889 non-null object
Sex 889 non-null object
Age 889 non-null object
SibSp 889 non-null object
Parch 889 non-null object
Ticket 889 non-null object
Fare 889 non-null object
Cabin 889 non-null object
Embarked 889 non-null object
dtypes: int64(3), object(9)
memory usage: 90.3+ KB
所有的特征以及分析完成了,需要删除的特征包括:'PassengerId','Name'和'Ticket',然后对剩余的特征进行独热编码。
#将训练数据分成标记和特征两部分
labels= train['Survived']
features= train.drop(['Survived','PassengerId','Name','Ticket'],axis=1)
#对所有特征实现独热编码
features = pd.get_dummies(features)
encoded = list(features.columns)
print ("{} total features after one-hot encoding.".format(len(encoded)))output14:
22 total features after one-hot encoding.
好了,现在训练集的数据已经整理好了,我们现在同法处理测试集的数据:
#对'Age','SibSp','Parch'特征进行分段分类
test['Age']=test['Age'].map(lambda x: 'child' if x<12 else 'youth' if x<30 else 'adlut' if x<60 else 'old' if x<75 else 'tooold' if x>=75 else 'null')
test['SibSp']=test['SibSp'].map(lambda x: 'small' if x<1 else 'middle' if x<3 else 'large')
test['Parch']=test['Parch'].map(lambda x: 'small' if x<1 else 'middle' if x<4 else 'large')
#均值补齐'Fare'特征值并作对数转换和分类
test.Fare.fillna(test['Fare'].mean(), inplace=True)
test['Fare']=test['Fare'].map(lambda x:np.log(x+1))
test['Fare']=test['Fare'].map(lambda x: 'poor' if x<2.5 else 'rich')
#按'Cabin'是否缺损分类
test['Cabin']=test['Cabin'].map(lambda x:'yes' if type(x)==str else 'no')
#删除不需要的特征并进行独热编码
Id=test['PassengerId']
test=test.drop(['PassengerId','Name','Ticket'],axis=1)
test=pd.get_dummies(test)
encoded = list(test.columns)
print ("{} total features after one-hot encoding.".format(len(encoded)))
output15:
22 total features after one-hot encoding.
完成测试集数据整理。
4.模型构建与参数优化
在完成了数据的清洗与整理之后,我们终于可以开始模型的训练了,虽然说数据是很关键的,但有好的数据必须要有好的模型配合才能发挥作用。就像吃得再好,锻炼的方法不科学也很难搞出完美的身材。
所以,让我们在这繁杂的算法海洋中找到最合适的那个吧!!!
考虑要用到的算法包括:决策树,SVM,随机森林,Adaboost,KNN以及传说中的大杀器Xgboost
首先我们先建立一个统一的训练框架,方便我们之后采用网格搜索调参
#首先引入需要的库和函数
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import accuracy_score,roc_auc_score
from time import time
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from xgboost.sklearn import XGBClassifier#定义通用函数框架
def fit_model(alg,parameters):
X=features
y=labels #由于数据较少,使用全部数据进行网格搜索
scorer=make_scorer(roc_auc_score) #使用roc_auc_score作为评分标准
grid = GridSearchCV(alg,parameters,scoring=scorer,cv=5) #使用网格搜索,出入参数
start=time() #计时
grid=grid.fit(X,y) #模型训练
end=time()
t=round(end-start,3)
print (grid.best_params_) #输出最佳参数
print ('searching time for {} is {} s'.format(alg.__class__.__name__,t)) #输出搜索时间
return grid #返回训练好的模型然后定义初始函数
#列出需要使用的算法
alg1=DecisionTreeClassifier(random_state=29)
alg2=SVC(probability=True,random_state=29) #由于使用roc_auc_score作为评分标准,需将SVC中的probability参数设置为True
alg3=RandomForestClassifier(random_state=29)
alg4=AdaBoostClassifier(random_state=29)
alg5=KNeighborsClassifier(n_jobs=-1)
alg6=XGBClassifier(random_state=29,n_jobs=-1)然后列出我们需要调整的参数及取值范围,这是一个很繁琐的工作,需要大量的尝试和优化。(以下参数范围并非最优,大家可以继续探索)
#列出需要调整的参数范围
parameters1={'max_depth':range(1,10),'min_samples_split':range(2,10)}
parameters2 = {"C":range(1,20), "gamma": [0.05,0.1,0.15,0.2,0.25]}
parameters3_1 = {'n_estimators':range(10,200,10)}
parameters3_2 = {'max_depth':range(1,10),'min_samples_split':range(2,10)} #搜索空间太大,分两次调整参数
parameters4 = {'n_estimators':range(10,200,10),'learning_rate':[i/10.0 for i in range(5,15)]}
parameters5 = {'n_neighbors':range(2,10),'leaf_size':range(10,80,20) }
parameters6_1 = {'n_estimators':range(10,200,10)}
parameters6_2 = {'max_depth':range(1,10),'min_child_weight':range(1,10)}
parameters6_3 = {'subsample':[i/10.0 for i in range(1,10)], 'colsample_bytree':[i/10.0 for i in range(1,10)]}#搜索空间太大,分三次调整参数OK,下面我们开始调参:
1.DecisionTreeClassifier
clf1=fit_model(alg1,parameters1)output16:
{'max_depth': 4, 'min_samples_split': 2}
searching time for DecisionTreeClassifier is 1.887 s
2.SVM
clf2=fit_model(alg2,parameters2)
output17:
{'C': 11, 'gamma': 0.05}
searching time for SVC is 57.562 s
3.RandomForest
第一次调参
clf3_m1=fit_model(alg3,parameters3_1)
output18:
{'n_estimators': 180}
searching time for RandomForestClassifier is 12.876 s
第二次调参
alg3=RandomForestClassifier(random_state=29,n_estimators=180)
clf3=fit_model(alg3,parameters3_2)output19:
{'max_depth': 7, 'min_samples_split': 2}
searching time for RandomForestClassifier is 70.793 s
4.AdaBoost
clf4=fit_model(alg4,parameters4)output20:
{'learning_rate': 1.2, 'n_estimators': 20}
searching time for AdaBoostClassifier is 152.917 s
5.KNN
clf5=fit_model(alg5,parameters5)
output21:
{'leaf_size': 50, 'n_neighbors': 9}
searching time for KNeighborsClassifier is 7.893 s
6.Xgboost
第一次调参:
clf6_m1=fit_model(alg6,parameters6_1)output22:
{'n_estimators': 140}
searching time for XGBClassifier is 5.302 s
第二次调参:
alg6=XGBClassifier(n_estimators=140,random_state=29,n_jobs=-1)
clf6_m2=fit_model(alg6,parameters6_2)output23:
{'max_depth': 4, 'min_child_weight': 5}
searching time for XGBClassifier is 37.972 s
第三次调参:
alg6=XGBClassifier(n_estimators=140,max_depth=4,min_child_weight=5,random_state=29,n_jobs=-1)
clf6=fit_model(alg6,parameters6_3)output24:
{'colsample_bytree': 0.9, 'subsample': 0.9}
searching time for XGBClassifier is 26.946 s
好了,至此调参和训练过程结束,我们已经训练得到了6个模型,现在是检验成果的时候了。
首先我们先定义一个保存函数,将预测的结果保存为可以提交的格式:
def save(clf,i):
pred=clf.predict(test)
sub=pd.DataFrame({ 'PassengerId': Id, 'Survived': pred })
sub.to_csv("res_tan_{}.csv".format(i), index=False)然后调用这个函数,完成6个模型的预测:
i=1
for clf in [clf1,clf2,clf3,clf4,clf5,clf6]:
save(clf,i)
i=i+1
最后让我们把这6个预测的结果提交给kaggle,得分结果如下图所示:

这6个预测结果都超过了0.77,基本达到了预测的效果,成绩最好的是随机森林模型,得分0.79425,比较出乎意外的是Xgboost的算法成绩竟然只有0.77511,可能是参数没有调好。大家可以尝试其他参数,说不定可以得到更好的成绩。不过考虑到这个项目数据量太小,能到0.8左右的成绩应该已经比较好了,重要的是学习数据处理,特征分析以及模型构建调参的过程,目的已经达到。
好了,再唠叨一句,现在得机器学习其实跟我想的不太一样,感觉完全是我在学习嘛~~~期待强智的出现。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!