社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
最近在做项目的时候偶然间发现了一个好玩的东西,那就是tesseract-ocr。首先介绍一下什么是OCR技术。光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。说白了就是可以提取到图片中的文字,这个技术在近两年比较火,可以发现现在的很多软件中(例如QQ、微信等)都已经融入了OCR技术,于是我花了一天时间安装编译了tesseract-ocr,期间遇到很多问题,虽然网上有关tesseract-ocr如何安装编译的资料很多,但是总有一些问题出现,我亲自安装了两次,也总结了一些安装经验,想拿出来与大家分享。
注:以下安装以ubuntu16.04为例,本例中用到的文件是1.71版的leptonica和3.04版的tesseract。不同的操作系统用到的文件不同,请勿乱用。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
Tesseract目前已作为开源项目发布在Google Project,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
二、安装并编译Tesseract
1.下载安装编译要用到的文件。
在安装tesseract时,需要下载很多文件,网上有的博客中给了下载链接,但是好多都需要翻墙才能下载,在这里我把所需要的文件下载到了网盘里供大家下载,https://pan.baidu.com/s/1mj6YTIw
提取码是:95p5
注:一定要先把这些文件下载到本地再进行后面的安装,因为后面会用到这些文件。
2.安装相应lib。
打开linux下的命令行,分别输入以下命令:
sudo apt-get install libpng12-dev
sudo apt-get install libjpeg62-dev
sudo apt-get install libtiff5-dev
sudo apt-get install libtool
sudo apt-get install gcc
sudo apt-get install g++
sudo apt-get install automake注:上面后三条指令所安装的文件一般电脑都自带,但是为了以防万一,还是安装一下,如果遇到已有的文件会跳过。
3.下载安装leptonica。
在linux命令行中输入:
wget http://www.leptonica.org/source/leptonica-1.71.tar.gz执行完毕后就得到了leptonica-1.71.tar.gz压缩文件,解压:
tar -zxvf leptonica-1.71.tar.gz
cd leptonica-1.71./configure
make
make install4.下载安装tesseract。
找到在百度云盘下载的那些文件中的tesseract-3.04.00.tar.gz,将其解压到根目录中(解压的命令就不再写出来了),查看:
我们已经得到了安装编译tesseract所需的tesseract-3.04.00文件。
进入到该文件目录下:
cd tesseract-3.04.00分别执行以下指令:
sudo ./autogen.sh
./configure
make
make install
ldconfigtesseract即安装编译成功。
5.安装中英文语言包。
找到在百度云盘下载的那些文件中的剩余文件,即chi_sim.traineddata、eng.traineddata、eng.traineddata.part三个文件,并把它们放到根目录中。
这个时候我们先来查看一下在/usr/local/share中是否有tessdata文件夹:
cd /usr/local/share
ls发现确实已有tessdata文件夹,接着我们将刚刚的三个文件拷贝到tessdata文件夹下:
cp chi_sim.traineddata /usr/local/share/tessdata
cp eng.traineddata /usr/local/share/tessdata
cp eng.traineddata.part /usr/local/share/tessdata到现在基本的安装编译工作已经完成。接着进行测试。
三、测试。
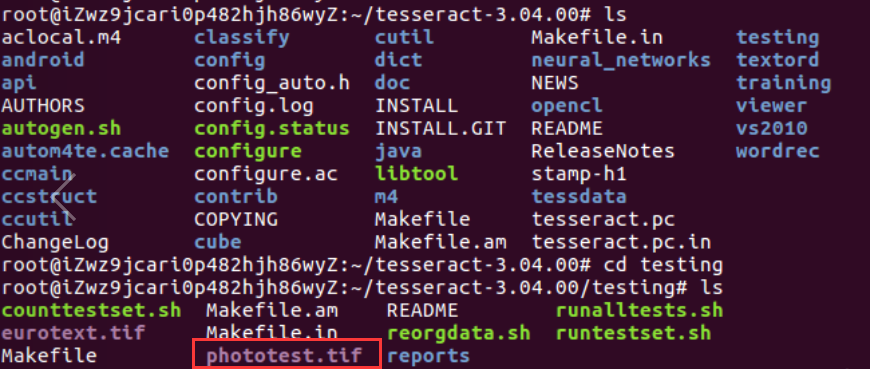
首先我们打开tesseract-3.04.00目录下的testing文件:
cd tesseract-3.04.00
cd testing
ls发现一个名为phototest.tif的文件,这个文件其实就是一张图片:
这个图片中有几句英文语句,我们的测试就是基于这张图片,也就是识别出这张图片中的英文语句。
于是在testing目录下输入下面指令:
tesseract phototest.tif result -l eng
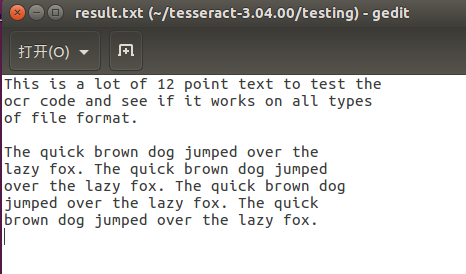
再查看testing目录下的文件,发现多了一个result.txt:
这个result.txt就是我们对刚刚的phototest.tif文件的识别结果,打开看一下:
跟刚刚图片中的内容完全一致,可以说识别率是很高的。到此我们的tesseract-ocr技术就已经可以使用了,由于我们导入了中文语言包chi_sim.traineddata,因此它还可以用来提取图片中的汉字,就这么简单就可以使用OCR技术来为你的程序服务了,很神奇也很简单!!!成就感满满!
PS:欢迎大家指出文中的不足和错误之处,我也是刚刚安装过,这里总结了自己的安装过程希望能帮到大家,此外每个人安装的过程中还可能遇到些小问题,可以百度解决,按照以上过程基本就能安装成功了!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!