社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
市场又火了,小伙伴们又涌入了,估值水平了解一下?
估值水平的代理指标之一:市盈率PE,其实是P/E,也就是 每股价格 ÷ 每股收益,上下一约分,就是 市值÷净利润(忽略特殊因素)。
静态市盈率:当前总市值 ÷ 去年一年的总净利润。
动态市盈率:当前总市值 ÷ 预估今年全年总净利润
滚动市盈率(PE TTM):当前总市值 ÷ 前面四个季度的总净利润。
注:TTM是Trailing Twelve Months,也就是滚动12个月。
Wind,具体接入方法可以参考以下链接。
Jason:在Python中接入Wind数据zhuanlan.zhihu.com
过去10年不同行业(如:选用申万一级行业)的日频 PE TTM数据
import time,datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 120
import locale
locale.setlocale(locale.LC_CTYPE,'chinese')
from WindPy import w
w.start()
DATE = input("请输入交易日(YYYYMMDD)【如查询今日可直接回车】:")
if DATE == "":
DATE = time.strftime('%Y%m%d')
else:
DATE = DATE
time_strct = time.strptime(DATE,'%Y%m%d')
Date_text = time.strftime('%Y年%m月%d日',time_strct) + ','
year, month, day = time_strct[:3]
DATE_datetime = datetime.date(year, month, day)
sector_SW = w.wset("sectorconstituent","date=" + DATE + ";sectorid=a39901011g000000")
df_sector_SW = pd.DataFrame(sector_SW.Data,index = sector_SW.Fields, columns = sector_SW.Codes).T[['wind_code','sec_name']].set_index('wind_code')
PE_TTM = w.wsd(df_sector_SW.index.tolist(), "pe_ttm", "ED-10Y", DATE, "")
df_PE_TTM = pd.DataFrame(PE_TTM.Data,index=PE_TTM.Codes, columns=PE_TTM.Times).T
df_PE_TTM.columns = df_sector_SW.sec_name.apply(lambda x: x.replace('(申万)',''))
df_PE_TTM.plot(figsize = (15,8),cmap = 'tab20c')
plt.legend(bbox_to_anchor=(1, 1))
plt.title('估值水平 PE')
plt.grid()你会得到所有行业过去10年的PE曲线:
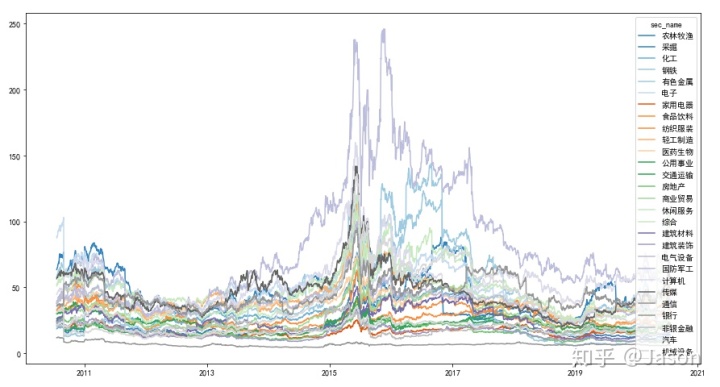
虽然能看到趋势,但是比较乱不易阅读。
所以,我们需要分行业来看。
我们先把所有行业列一下:
df_sector = pd.DataFrame(df_PE_TTM.columns)
df_sector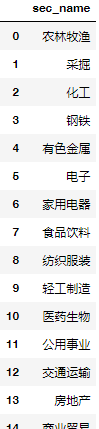
我们通过以下代码选择行业,并单独展示,此处我们选择展示趋势图和频率图:
SECTOR = input("请输入行业对应的序号:【一个以上的行业请用空格分开】")
SECTOR_LIST = [int(x) for x in SECTOR.split(' ')]
sector = df_sector.iloc[SECTOR_LIST]
sector_list = sector.sec_name.tolist()
print ('您输入的行业是:' + sector)
fig, axes = plt.subplots(nrows=2*len(sector_list),figsize = (15,15*len(sector_list)))
for i,j in enumerate(sector_list):
df_PE_TTM[[j]].plot(ax=axes[2*i],title = 'PE');
axes[2*i].plot(df_PE_TTM[j].index, [df_PE_TTM[j][-1]] * len(df_PE_TTM[j].index))
df_PE_TTM[[j]].plot.hist(ax=axes[2*i+1],alpha=0.5,bins = 100)
axes[2*i+1].plot([df_PE_TTM[j][-1]]*len(range(0,100)),range(0,100))比如我们看一下 非银金融 和 医药生物:(蓝色的线是历史数据,黄色的线是当前水平)
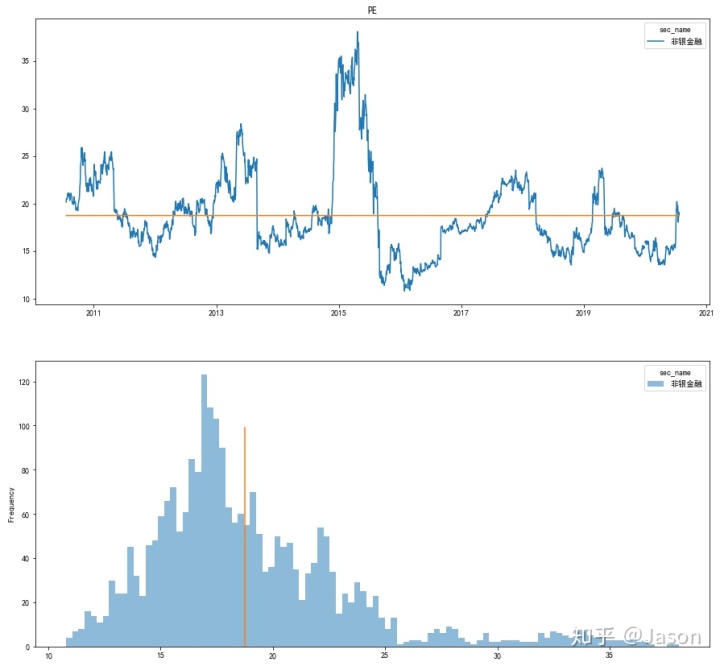
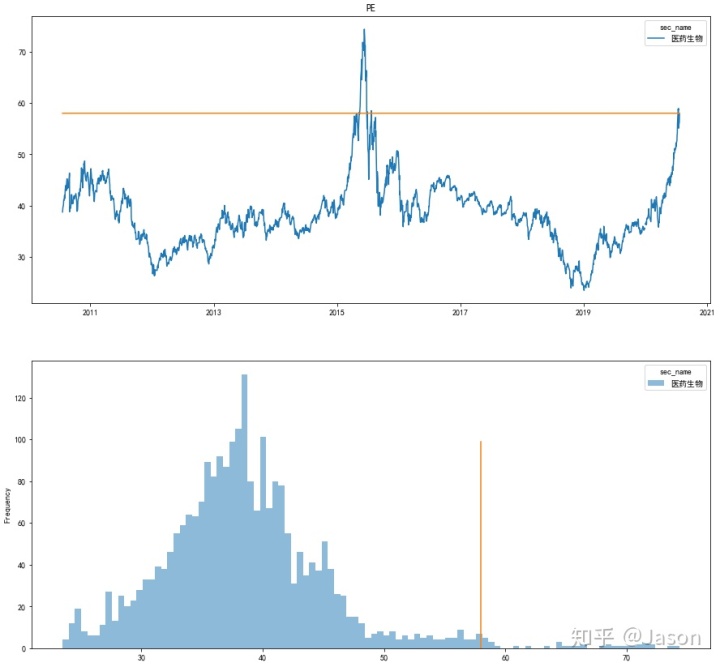
我们可以看到,非银金融的当前估值水平在历史中相对较低,而生物医药的估值水平已经到达了相当高的水平。
我们给各行业的估值分位数排个序:
PE_quantile_sum = pd.DataFrame()
for i in df_PE_TTM.columns:
df_PE_quantile = df_PE_TTM[[i]].sort_values(i)
df_PE_quantile['rank'] = range(0,len(df_PE_quantile))
PE_quantile = df_PE_quantile[df_PE_quantile.index == DATE_datetime]['rank'][0] / len(df_PE_quantile)
PE_last = df_PE_quantile[df_PE_quantile.index == DATE_datetime][i][0]
PE_quantile_sum.loc[i,'分位数'] = PE_quantile
PE_quantile_sum.loc[i,'PE'] = PE_last
PE_quantile_sum.sort_values('分位数',ascending=True,inplace=True)
PE_quantile_sum['分位数'] = PE_quantile_sum['分位数'].apply(lambda x: '{:.2%}'.format (x))
PE_quantile_sum['PE'] = PE_quantile_sum['PE'].apply(lambda x: '{:.2f}'.format (x))
PE_quantile_sum.columns = ['分位数','PE-'+DATE]
PE_quantile_sum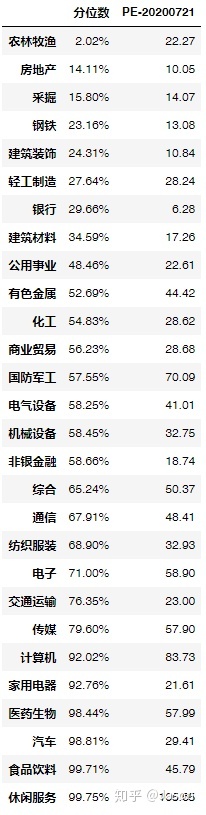
这样我们就可以清楚地看到,哪些行业与历史数据相比处于相对高估值的状态,哪些相对较低。
1、通常地,估值水平有均值回复(Mean-Reverting)特性。因此,投资估值相对较低的行业,通常更安全,或者说胜率更大;
2、警惕高估值股票的下跌风险;
3、均值回复可能需要相当长的时间;
4、如果某行业确实具有高增长特性,则估值水平会突破前高,反之亦然。
以上方法也可以推广到个股。
Enjoy!
Jason
以上不构成投资建议。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
