社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在数据挖掘中,异常检测(anomaly detection)是通过与大多数数据显着不同而引起怀疑的稀有项目,事件或观察的识别。通常情况下,异常项目会转化为某种问题,例如银行欺诈,结构缺陷,医疗问题或文本错误。异常也被称为异常值,新奇,噪声,偏差和异常。
数据异常可以转化为各种应用领域中的重要(且常常是关键的)可操作信息。 例如,计算机网络中的异常流量模式可能意味着被黑客窃取的计算机在将敏感数据发送到未经授权的目的地;异常的MRI图像可能表明存在恶性肿瘤;信用卡交易数据的异常可能表明信用卡或身份盗用;或来自航天器传感器的异常读数可能意味着航天器某些部件的故障。我们将先介绍异常(值)的概念。
异常值检测常用于异常订单识别、风险客户预警、黄牛识别、贷款风险识别、欺诈检测、技术入侵等针对个体的分析场景。
异常数据根据原始数据集的不同可以分为离群点检测和新奇检测:
在大多数场景下通过非监督式方法实现的异常检测的结果只是用来缩小排查范围,为业务的执行提供更加精准和高效的执行目标而已
from sklearn.svm import OneClassSVM
import numpy as np
import plotly.offline as py
import plotly.graph_objs as go
py.init_notebook_mode(connected=True)
# 导入数据
data = np.loadtxt('https://raw.githubusercontent.com/ffzs/dataset/master/outlier.txt', delimiter=' ')
#分配训练集和测试集
train_set = data[:900, :]
test_set = data[-100:, :]
#### 异常检测 ###
# 创建异常检测模型
one_svm = OneClassSVM(nu=0.1, kernel='rbf', random_state=2018)
# 训练模型
one_svm.fit(train_set)
# 预测异常数据
pre_test_outliers = one_svm.predict(test_set)
### 异常结果统计###
# 合并测试检测结果
total_test_data = np.hstack((test_set, pre_test_outliers.reshape(-1,1)))
# 获取正常数据
normal_test_data = total_test_data[total_test_data[:, -1] == 1]
# 获取异常数据
outlier_test_data = total_test_data[total_test_data[:, -1] == -1]
# 输出异常数据结果
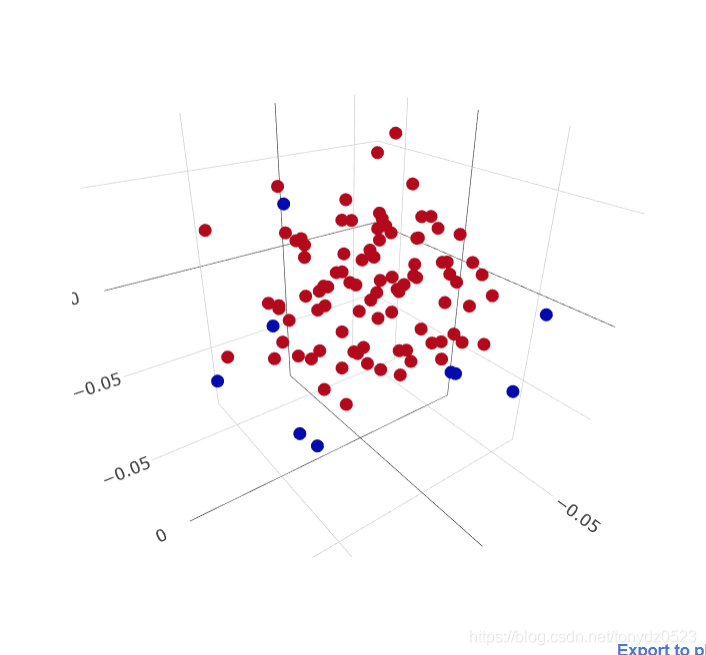
print('异常数据为:{}/{}'.format(len(outlier_test_data), len(total_test_data)))
# 异常数据为:9/100
# 可视化结果
py.iplot([go.Scatter3d(x=total_test_data[:,0], y=total_test_data[:,1], z=total_test_data[:,2],
mode='markers',marker=dict(color=total_test_data[:, -1], size=5))])
参考:
维基百科Anomaly detection
《python数据分析与数据化运营》 宋天龙
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
