决策树分类很符合人类分类时的思想,决策树分类时会提出很多不同的问题,判断样本的某个特征,然后综合所有的判断结果给出样本的类别。例如下图的流程即为一个典型的决策树分类的流程图,这个流程图用来简略的判断一个小学生是否学习很好,当然这里只是举个例子,现在的小学生可是厉害的不行了,这点评判标准完全不够看啊。。。
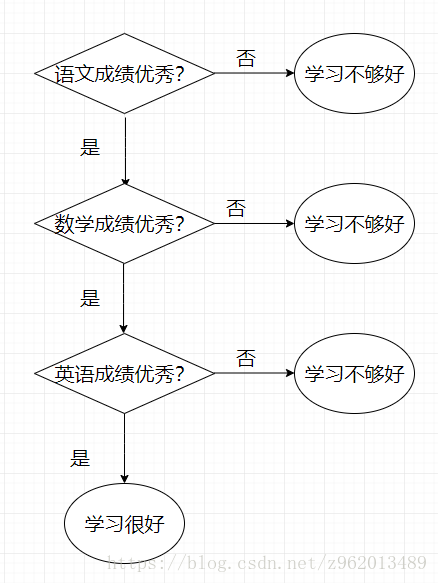
说白了决策树就是if else的堆砌,是一个树形结构,我们在构建决策树分类器的时候主要关心的是用什么特征分类和分多少个枝叶。
特征选择
首先我们来说说特征选择,我们给出如下表所示的一系列样本
| 样本 |
花瓣颜色 |
花蕊长度 |
树叶类型 |
种类 |
|---|
| 1 |
绿色 |
高 |
三角 |
A |
| 2 |
红色 |
高 |
方形 |
B |
| 3 |
绿色 |
低 |
三角 |
B |
| 4 |
绿色 |
高 |
方形 |
A |
| 5 |
红色 |
低 |
三角 |
B |
| 6 |
绿色 |
低 |
方形 |
B |
我们要根据花瓣颜色、花蕊长度和树叶类型这三个特征对样本植物辨别出其种类A或B,那么应该以什么样的标准选择特征呢?
信息增益
“信息熵”(information entropy)是度量样本集合纯度的一种常用指标,若集合D中存在d个类别的N个样本,令pk=NNk为从集合D中随机选取一个样本属于第k类样本的概率,则有下述信息熵定义:
Ent(D)=−k=1∑dpklog2pk
我们可以计算一下上表样本集的信息熵:
Ent(D)=−62∗log262−−64∗log264=0.9183
假如某离散属性a有V个可能的取值,如属性花瓣颜色方面有2个可能的取值:绿色、红色。若选取属性a对样本集D划分,则会产生V个分支,第v个分支上的样本数量为Nv,我们可以计算出各分支的信息熵,根据各分支拥有的样本与总样本数的比值作为各分支节点的权重,于是有下述信息增益(information gain)定义:
Gain(D,a)=Ent(D)−v=1∑VNNvEnt(Dv)
上面的话不好理解,我们带入一个例子就轻松多了:选取属性为a=花瓣颜色,那么V=2(绿色、红色),样本集D含有N=6个样本,经过花瓣颜色的分类后出现了D1、D2两个样本集,其中D1中含有的样本数N1=4,D2中含有的样本数N2=2,那么:
Ent(D1)=−42∗log242−42∗log242=1
Ent(D2)=−22∗log222=0
Gain(D,petalcolor)=Ent(D)−64Ent(D1)−62Ent(D2)=0.2516
通常信息增益越大,则意味着使用属性a划分所获得的样本集合的综合纯度越大,著名的ID3决策树学习算法就是以信息增益为准则选取属性划分决策树的。
我们这里继续计算另外两个属性的Gain:
Gain(D,PistilLength)=0.4592
Gain(D,LeafType)=0
经过比较后我们发现属性花蕊长度是最优的属性,那么我们选择花蕊长度划分作为我们决策树的根节点

经过划分后我们发现凡是花蕊长度低的花都是B类,那么我们就将右边的节点设为叶子节点,然后我们继续分析左边的节点应该选择什么属性继续划分,这里我们直接不考虑属性花蕊长度,我们将样本1,2,4构成的样本集称为DD,则:
Ent(DD)=−32∗log232−−31∗log231=0.9183
Gain(DD,PetalColor)=0.9183
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/z962013489/article/details/80024574
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

