社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
市面上流行的消息队列有rabbitmq,kafka,Activemq等,所有这些都是为了解决消息的分布式消费,完成项目与服务的解耦。采取异步模式完成消息队列提供者和消费者的通信,提高了系统的响应能力和信息吞吐量。
基本概念
常用的转发方式有
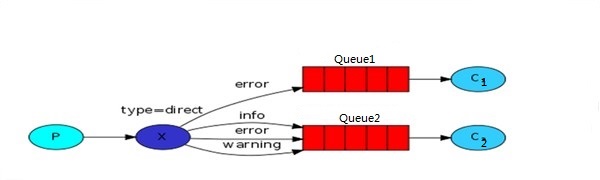
1)DirectExchange
直接交换器类型,根据routingkey采取点对点的信息转发
@Configuration
public class UserRegisterQueueConfiguration {
/**
* 配置路由交换对象实例
* @return
*/
@Bean
public DirectExchange userRegisterDirectExchange()
{
return new DirectExchange(ExchangeEnum.USER_REGISTER.getValue());
}
/**
* 配置用户注册队列对象实例
* 并设置持久化队列
* @return
*/
@Bean
public Queue userRegisterQueue()
{
return new Queue(QueueEnum.USER_REGISTER.getName(),true);
}
/**
* 将 用户注册队列 绑定到 路由交换配置 上并设置指定路由键进行转发
* @return
*/
@Bean
public Binding userRegisterBinding()
{
return BindingBuilder.bind(userRegisterQueue()).to(userRegisterDirectExchange()).with(QueueEnum.USER_REGISTER.getRoutingKey());
}
}2)FanoutExchange
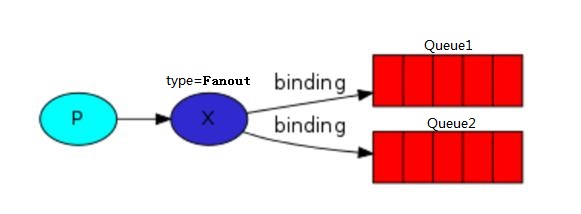
广播交换器类型,将同一个message发送到所有同该Exchange 绑定的queue。不论RoutingKey是什么,这条消息都会被投递到所有与此Exchange绑定的queue中。
@Configuration
public class SenderConf {
@Bean(name="Amessage")
public Queue AMessage() {
return new Queue("fanout.A");
}
@Bean(name="Bmessage")
public Queue BMessage() {
return new Queue("fanout.B");
}
@Bean(name="Cmessage")
public Queue CMessage() {
return new Queue("fanout.C");
}
@Bean
FanoutExchange fanoutExchange() {
return new FanoutExchange("fanoutExchange");//配置广播路由器
}
@Bean
Binding bindingExchangeA(@Qualifier("Amessage") Queue AMessage,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(AMessage).to(fanoutExchange);
}
@Bean
Binding bindingExchangeB(@Qualifier("Bmessage") Queue BMessage, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(BMessage).to(fanoutExchange);
}
@Bean
Binding bindingExchangeC(@Qualifier("Cmessage") Queue CMessage, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(CMessage).to(fanoutExchange);
}
}3)TopicExchange
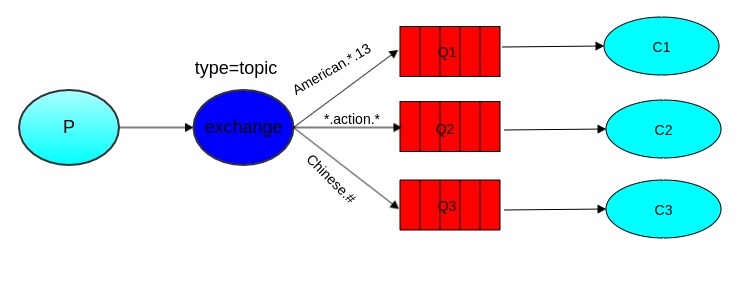
主题交换器,根据Binding指定的RoutingKey,Exchange对key进行模式匹配后投递到相应的Queue。
如图中,假如消息的RoutingKey是American.action.13,这条消息将被投递到Q1和Q2中。假如RoutingKey是American.action.13.test(注意:此处是四个词),这条消息将会被丢弃,因为没有routingkey与之匹配。假如RoutingKey是Chinese.action.13,这条消息将被投递到Q2和Q3中。假如RoutingKey是Chinese.action.13.test,这条消息只会被投递到Q3中,#可以匹配一个或者多个单词,而*只能匹配一个词。
@Configuration
public class UserRegisterQueueConfiguration {
private Logger logger = LoggerFactory.getLogger(UserRegisterQueueConfiguration.class);
/**
* 配置用户注册主题交换
* @return
*/
@Bean
public TopicExchange userTopicExchange()
{
TopicExchange topicExchange = new TopicExchange(ExchangeEnum.USER_REGISTER_TOPIC_EXCHANGE.getName());
logger.info("用户注册交换实例化成功。");
return topicExchange;
}
/**
* 配置用户注册
* 创建账户消息队列
* 并设置持久化队列
* @return
*/
@Bean
public Queue createAccountQueue()
{
Queue queue = new Queue(QueueEnum.USER_REGISTER_CREATE_ACCOUNT.getName(),true,false,true);
logger.info("创建用户注册账号队列成功.");
return queue;
}
/**
* 绑定用户创建账户到用户注册主题交换配置
* @return
*/
@Bean
public Binding createAccountBinding(TopicExchange userTopicExchange,Queue createAccountQueue)
{
Binding binding = BindingBuilder.bind(createAccountQueue).to(userTopicExchange).with(QueueEnum.USER_REGISTER_CREATE_ACCOUNT.getRoutingKey());
logger.info("绑定创建账号到注册交换成功。");
return binding;
}
}
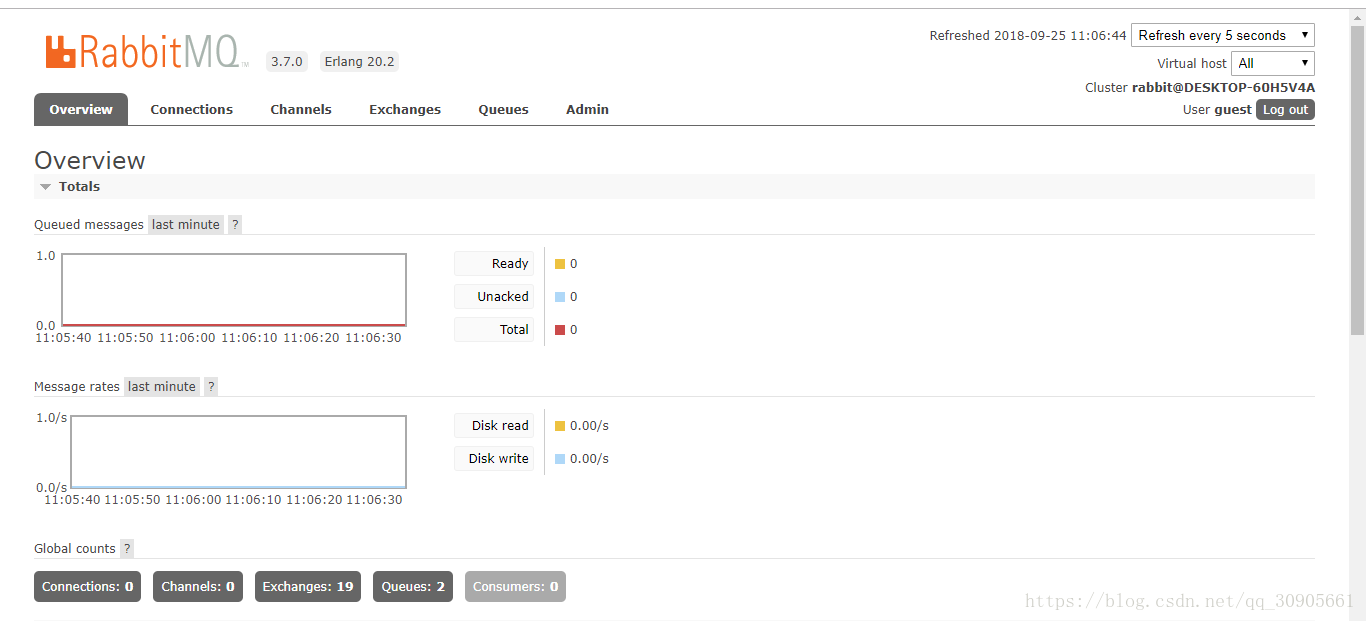
监控页面
在rabbitmq sbin目录下执行以下语句开启指定插件。
rabbitmq-plugins.bat enable rabbitmq_management访问http://127.0.0.1:15672,可访问rabbitmq监控管理页面
优缺点
优点:
(1)由Erlang语言开发,支持大量协议:AMQP、XMPP、SMTP、STOMP。
(2)支持消息的持久化、负载均衡和集群,且集群易扩展。
(3)具有一个Web监控界面,易于管理。
(4)安装部署简单,上手容易,功能丰富,强大的社区支持。
(5)支持消息确认机制、灵活的消息分发机制。
缺点:
(1)由于牺牲了部分性能来换取稳定性,比如消息的持久化功能,使得RabbitMQ在大吞吐量性能方面不及Kafka和ZeroMQ。
(2)由于支持多种协议,使RabbitMQ非常重量级,比较适合企业级开发。
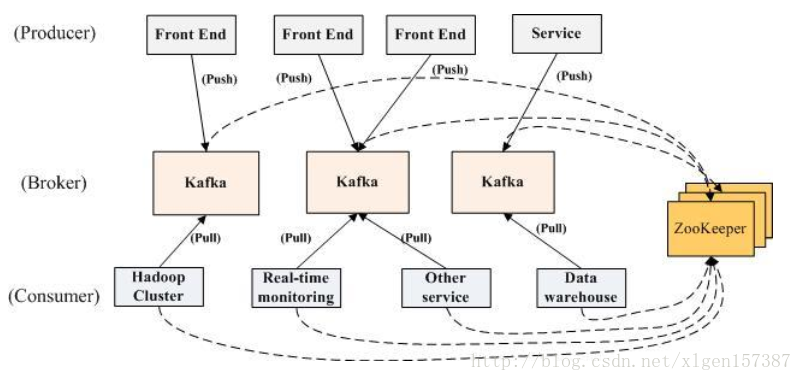
kafka是Apache公司的,用java编写,类AMQP协议。必须和zookeeper配合才能使用。
基本概念
1、消费者:(Consumer):主动从Broker拉数据,从而消费这些已发布的消息
2、生产者:(Producer) :向broker发布消息的应用程序
3、AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于kafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
4、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名;
5、分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
zookeeper
(1)无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
(2)Kafka使用zookeeper作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。
(3)同时借助zookeeper,kafka能够生产者、消费者和broker在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
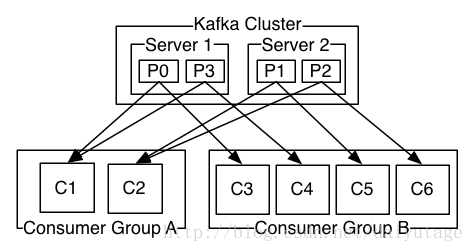
group partition
group和partition有千丝万缕的关系,网上关于两者的介绍很多,但基本上都是提问,回复也是五花八门,本着严谨治学的态度,以下全是实践之后得出的结论。
一个topic可以分为多个partition,这么做的好处是,每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中,一个group中的多个consumer加入时,server会进行partition负载均衡,一个group中的consumer可以分配多个partition,也可能一个都分不到。
1)创建topic aaa,只对应一个partition aaa-0
2)创建topic bbb,对应6个partition bbb-0 bbb-1 bbb-2 bbb-3 bbb-4 bbb-5
3)先启动一个服务consumer1,监听topics={"aaa","bbb"},group-id="test-consumer-group"
默认系统给分配的partition如下,这个consumer1一个人占了7个partition!!!
4)很明显,如果让consumer1一个人占7个partition,就失去了负载均衡的意义。此时我们再起一个服务consumer2,topics={"aaa","bbb"},group-id="test-consumer-group"
启动后consumer2重新分配后的partition如下,发现[bbb-3,bbb-4,bbb-5]都归consumer2所有
同时consumer1那边重新分配后的partition如下,值得注意的是aaa-0是碰巧还属于consumer1,即consumer的启动顺序和分配partition是无关的!!!且topic中的partition数量少于同一个group中consumer的数量时,肯定会有consumer没有分配到partition,即无法接收消息!!!
启动了两个consumer,只有consumer1拥有aaa-0,所以只有consumer1能接收到topic aaa的消息。
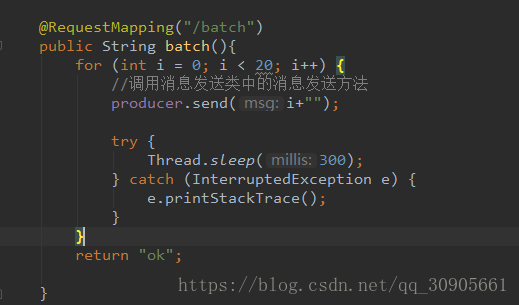
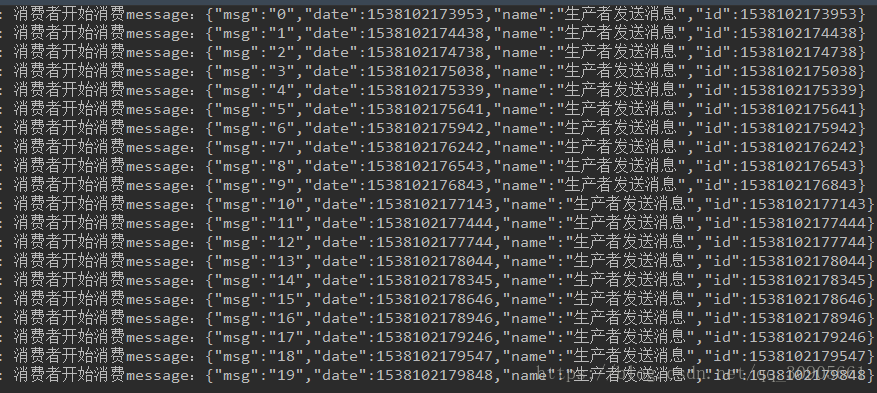
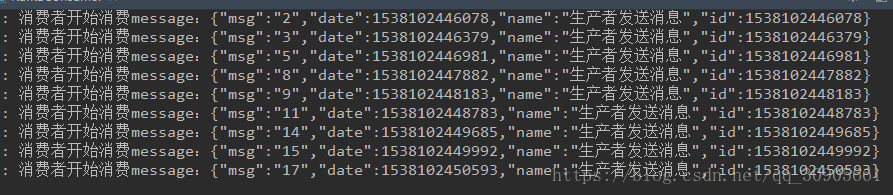
5)启动producer向topic aaa发送请求,数字0~19,可以预想到只有consumer1能接收到所有消息
consumer1接收所有消息,consumer2没有接收到信息
6)如果producer向bbb发送消息呢?bbb有6个partitions,consumer1和consumer2能接收到什么消息呢?
答案是20条消息被随机分配到了两个consumer中,
consumer1接收的消息
consumer2接收的消息
7)现在我们启动consumer3,topics={"aaa","bbb"},group-id="test-consumer-group2",这里group-id与其两者不同。在保证consumer1和consumer2运行的情况下启动consumer3,分配的partitions如下。可见consumer3拥有7个partition,并没和consumer1或者consumer2有什么交集,更谈不上负载均衡,自然consumer3能收到所有信息。
总结:
producer向topic发送消息,topic分配给所属的partitions。
consumer声明group-id,并监听topic,启动后会接收系统分配partitions。一个partition只能绑定同一个group中的一个consumer,但能绑定多个不同group中的consumer,基于这个原理就会发生有趣的事情。
启动多个不同group-id的consumer监听topic,所有的consumer都能接收到信息,这是广播
启动多个相同group-id的consumer监听topic,且topic中的partition数量>=consumer的数量,这是负载均衡,一条消息永远只有一个consumer能消费,下一条消息可能是另一个consumer消费。所有的consumer都会消费到消息。
启动多个相同group-id的consumer监听topic,且topic中partition数量<consumer的数量,那么总会有consumer没分配到partition,即它永远接收不到消息。
优缺点
优点:
1)可扩展。Kafka集群可以透明的扩展,增加新的服务器进集群。
2)高性能。Kafka性能远超过传统的ActiveMQ、RabbitMQ等,Kafka支持Batch操作。
3)容错性。Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将通知生产者和消费者从而使用其他的Broker。
缺点:
1)重复消息。Kafka保证每条消息至少送达一次,虽然几率很小,但一条消息可能被送达多次。
2)消息乱序。Kafka某一个固定的Partition内部的消息是保证有序的,如果一个Topic有多个Partition,partition之间的消息送达不保证有序。
3)复杂性。Kafka需要Zookeeper的支持,Topic一般需要人工创建,部署和维护比一般MQ成本更高。
4)不能像Rabbitmq那样用topic(#,*)匹配方式传递信息,只能死板地订阅topic,且当同一个group内consumer数量>topic中partition数量时,会有consumer接收不到消息,而rabbitmq可以通过fanout模式实现广播。
搭建流程
kafka的搭建相对较为复杂,因为boker、producer、consumer都是通过zookeeper交流的,所以要先搭建zookeeper,再搭建kafka。
1.搭建zookeeper
在新版的kafka中,都会自带zookeeper,但总归是配置不够方便明了。一般还是单独下载zookeeper进行搭建。
zookeeper下载地址:http://mirrors.hust.edu.cn/apache/zookeeper/
1.1 配置zoo.cfg
解压后,里面有conf/zoo_sample.cfg,把它复制粘贴后改名zoo.cfg,作为核心配置类,zookeeper启动时会读取zoo.cfg中的配置信息。其中dataDir,dataLogDir,server.x这几个属性得重新配置。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir和dataLogDir可以自行设置,必须是全路径
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/datalog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
requireClientAuthScheme=sasl
jaasLoginRenew=3600000
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#配置集群地址,第一个端口是master和slave之间的通信端口,默认是2888,
#第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
server.1=192.168.3.163:2888:3888
server.2=192.168.3.164:2888:3888
server.3=192.168.3.165:2888:3888
zookeeper集群配置服务器地址,可以像上图那样配置,也可以在/etc/hosts中将这些ip配置成具体名称(zk1,zk2,zk3),这样配置的好处是如果某个IP地址发生了变化,我们不需要重启zookeeper,直接修改主机对应的IP地址即可。
[root@localhost zookeeper]# vi /etc/hosts
然后在文件末尾追加以下内容,这样就可以在zoo.cfg中用server.1=zk1:2888:3888来代替了。
192.168.3.163 zk1 192.168.3.164 zk2 192.168.3.165 zk3
按照上面配置,将zookeeper文件夹scp -r到另外两个服务器上。
1.2 创建myid
myid文件和zookeeper_server.pid 在快照目录下(./data)存放的标识本台服务器的文件,他是整个zk集群用来发现彼此的一个重要标识。快照目录需和zoo.cfg中 dataDir=/usr/local/zookeeper/data 一致。
myid文件里面只有一个数字,用于区分集群中不同节点的zookeeper。分别给几个zookeeper创建myid。
#server1 echo "1" > /usr/local/zookeeper/data/myid #server2 echo "2" > /usr/local/zookeeper/data/myid #server3 echo "3" > /usr/local/zookeeper/data/myid
zookeeper_server.pid是启动zookeeper server后,自动创建的文件,里面有数字pid,即启动zookeeper的进程号pid。
1.3 启动zookeeper
进入bin目录下
#启动服务(3台都需要操作)
./zkServer.sh start
#关闭服务
./zkServer.sh stop
#检查服务器状态
./zkServer.sh status
#执行命令jps,查看zk进程QuorumPeerMain
jps
20348 Jps
4233 QuorumPeerMain
#使用客户端进入zk
./zkCli.sh -server 192.168.3.164:2181
[zk: 127.0.0.1:12181(CONNECTED) 0] ls /
#显示结果:[consumers, config, controller, isr_change_notification, admin, brokers, zookeeper, controller_epoch]
'''
上面的显示结果中:只有zookeeper是,zookeeper原生的,其他都是Kafka创建的
'''
#查看partion
[zk: 127.0.0.1:12181(CONNECTED) 7] get /brokers/topics/shuaige/partitions/0
#查看group,其中console-consumer-xxxxx是控制台默认生成consumer./kafka-console-consumer.sh
[zk: localhost:2181(CONNECTED) 1] ls /consumers
[console-consumer-24279, console-consumer-87851, console-consumer-74253, console-consumer-91660, test-consumer-group, console-consumer-20304]
#删除group
[zk: localhost:2181(CONNECTED) 6] rmr /consumers/console-consumer-20304
2 Kafka集群搭建
下载kafka并解压,本人下的是版本是 kafka_2.12-1.1.0.tar ,不同的版本配置文件内容可能不太一致,所以一定要参考相应版本的配置文件。参考 https://blog.csdn.net/l1028386804/article/details/79194929
2.1 配置server.properties
在config目录下有很多配置文件,其中最重要的就是server.properties,里面包含了zookeeper集群的ip地址,监听本机kafka-server的ip:port。
需要修改的就三个属性
broker.id 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
listeners 当前机器的ip地址,如果是搭建集群的话必须写ip,单机可以写localhost:9092
zookeeper.connect zookeeper集群的所有ip地址
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.3.165:9092
...
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.3.163:2181,192.168.3.164:2181,192.168.3.165:2181
2.2 启动集群
进入bin目录,
#后台启动kafka服务
./kafka-server-start.sh -daemon ../config/server.properties
#关闭服务
./kafka-server-stop.sh
#检查服务启动成功没有
jps
20348 Jps
4233 QuorumPeerMain
18991 Kafka
#查看所有创建的topic,连接的是zookeeper
./kafka-topics.sh --list --zookeeper 192.168.3.164:2181
#创建Topic
./kafka-topics.sh --create --zookeeper 192.168.3.164:2181 --replication-factor 2 --partitions 1 --topic bbb
#解释
--replication-factor 2 #复制两份
--partitions 1 #创建1个分区
--topic #主题为bbb
#修改topic partition
./kafka-topics.sh --alter --topic bbb --zookeeper 192.168.3.164:2181 --partitions 6
#查看topic具体信息
./kafka-topics.sh --describe --zookeeper 192.168.3.164:2181 --topic bbb
#创建一个broker,发布者
./kafka-console-producer.sh --broker-list 192.168.3.164:9092 --topic bbb
#在一台服务器上创建一个订阅者,默认创建的consumer group-id=console-consumer-xxxxx
./kafka-console-consumer.sh --zookeeper l92.168.3.164:2181 --topic bbb --from-beginning
#也可以指定consumer.properties,设置group-id
./kafka-console-consumer.sh --consumer.config ../config/consumer.properties --zookeeper 192.168.3.165:2181 --topic bbb
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!