社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
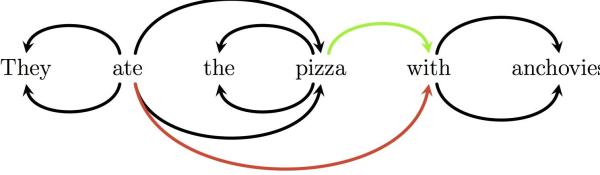
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们对世界的了解可以迅速地发现这些歧义。举一个我很喜欢的例子:
They ate the pizza with anchovies

正确的解析是连接“with”和“pizza”,而错误的解析将“with”和“eat”联系在了一起:
过去的一些年,自然语言处理(NLP)社区在语法分析方面取得了很大的进展。现在,小小的 Python 实现可能比广泛应用的 Stanford 解析器表现得更出色。
解析器 准确度 速度(词/秒) 语言 位置
Stanford 89.6% 19 Java > 50,000[1]
parser.py 89.8% 2,020 Python ~500
Redshift 93.6% 2,580 Cython ~4,000
文章剩下的部分首先设置了问题,接着带你了解为此准备的简洁实现。parser.py 代码中的前 200 行描述了词性的标注者和学习者(这里)。除非你非常熟悉 NLP 方向的研究,否则在研究这篇文章之前至少应该略读。
Cython 系统和 Redshift 是为我目前的研究而写的。和麦考瑞大学的合同到期后,我计划六月份对它进行改进,用于一般用途。目前的版本托管在 GitHub 上。
在你的手机中输入这样一条指令是非常友善的:
Set volume to zero when I’m in a meeting, unless John’s school calls.
接着进行适当的策略配置。在 Android 系统上,你可以应用 Tasker 做这样的事情,而 NL 接口会更好一些。接收可以编辑的语义表示,你就能了解到它认为你表达的意思,并且可以修正他的想法,这样是特别友善的。
这项工作有很多问题需要解决,但一些种类的句法形态绝对是必要的。我们需要知道:
Unless John’s school calls, when I’m in a meeting, set volume to zero
是解析指令的又一种方式,而
Unless John’s school, call when I’m in a meeting
表达了完全不同的意思。
依赖解析器返回一个单词与单词间的关系图,使推理变得更容易。关系图是树形结构,有向边,每个节点(单词)有且仅有一个入弧(头部依赖)。
用法示例:
- >>> parser = parser.Parser()
- >>> tokens = "Set the volume to zero when I 'm in a meeting unless John 's school calls".split()
- >>> tags, heads = parser.parse(tokens)
- >>> heads
- [-1, 2, 0, 0, 3, 0, 7, 5, 7, 10, 8, 0, 13, 15, 15, 11]
- >>> for i, h in enumerate(heads):
- ... head = tokens[heads[h]] if h >= 1 else 'None'
- ... print(tokens[i] + ' <-- ' + head])
- Set <-- None
- the <-- volume
- volume <-- Set
- to <-- Set
- zero <-- to
- when <-- Set
- I <-- 'm
- 'm <-- when
- in <-- 'm
- a <-- meeting
- meeting <-- in
- unless <-- Set
- John <-- 's
- 's <-- calls
- school <-- calls
- calls <-- unless
一种观点是通过语法分析进行推导比字符串应该稍稍容易一些。语义分析映射有望比字面意义映射更简单。
这个问题最让人困惑的是正确性是由惯例,即注释指南决定的。如果你没有阅读指南并且不是一个语言学家,就不能判断解析是否正确,这使整个任务显得奇怪和虚假。
例如,在上面的解析中存在一个错误:根据 Stanford 的注释指南规定,“John’s school calls” 存在结构错误。而句子这部分的结构是指导注释器如何解析一个类似于“John’s school clothes”的例子。
这一点值得深入考虑。理论上讲,我们已经制定了准则,所以“正确”的解析应该相反。如果我们违反约定,有充分的理由相信解析任务会变得更加困难,因为任务和其他语>法的一致性会降低。【2】但是我们可以测试经验,并且我们很高兴通过反转策略获得优势。
我们确实需要惯例中的差异——我们不希望接收相同的结构,否则结果不会很有用。注释指南在哪些区别使下游应用有效和哪些解析器可以轻松预测之间取得平衡。
在决定构建什么样子的关系图时,我们可以进行一项特别有效的简化:对将要处理的关系图结构进行限制。它不仅在易学性方面有优势,在加深算法理解方面也有作用。大部分的>英文解析工作中,我们遵循约束的依赖关系图就是映射树:
在解析非映射树方面有丰富的文献,解析无环有向图方面的文献相对而言少一些。我将要阐述的解析算法用于映射树领域。
我们的语法分析器以字符串符号列表作为输入,输出代表关系图中边的弧头索引列表。如果第 i 个弧头元素是 j, 依赖关系包括一条边 (j, i)。基于转换的语法分析器>是有限状态转换器;它将 N 个单词的数组映射到 N 个弧头索引的输出数组。
start MSNBC reported that Facebook bought WhatsApp for $16bn root
0 2 9 2 4 2 4 4 7 0
弧头数组表示了 MSNBC 的弧头:MSNBC 的单词索引是1,reported 的单词索引是2, head[1] == 2。你应该已经发现为什么树形结构如此方便——如果我们输出一个 DAG 结构,这种结构中的单词可能包含多个弧头,树形结构将不再工作。
虽然 heads 可以表示为一个数组,我们确实喜欢保持一定的替代方式来访问解析,以方便高效的提取特征。Parse 类就是这样:
- class Parse(object):
- def __init__(self, n):
- self.n = n
- self.heads = [None] * (n-1)
- self.lefts = []
- self.rights = []
- for i in range(n+1):
- self.lefts.append(DefaultList(0))
- self.rights.append(DefaultList(0))
- def add_arc(self, head, child):
- self.heads[child] = head
- if child < head:
- self.lefts[head].append(child)
- else:
- self.rights[head].append(child)
和语法解析一样,我们也需要跟踪句子中的位置。我们通过在 words 数组中置入一个索引和引入栈机制实现,栈中可以压入单词,设置单词的弧头时,弹出单词。所以我们的状态数据结构是基础。
解析过程的每一步都应用了三种操作之一:
- SHIFT = 0; RIGHT = 1; LEFT = 2
- MOVES = [SHIFT, RIGHT, LEFT]
- def transition(move, i, stack, parse):
- global SHIFT, RIGHT, LEFT
- if move == SHIFT:
- stack.append(i)
- return i + 1
- elif move == RIGHT:
- parse.add_arc(stack[-2], stack.pop())
- return i
- elif move == LEFT:
- parse.add_arc(i, stack.pop())
- return i
- raise GrammarError("Unknown move: %d" % move)
LEFT 和 RIGHT 操作添加依赖关系并弹栈,而 SHIFT 压栈并增加缓存中 i 值。
因此,语法解析器以一个空栈开始,缓存索引为0,没有依赖关系记录。选择一个有效的操作,应用到当前状态。继续选择操作并应用直到栈为空且缓存索引到达输入数组的终点。(没有逐步跟踪是很难理解这种算法的。尝试准备一个句子,画出映射解析树,接着通过选择正确的转换序列遍历完解析树。)
下面是代码中的解析循环:
- class Parser(object):
- ...
- def parse(self, words):
- tags = self.tagger(words)
- n = len(words)
- idx = 1
- stack = [0]
- deps = Parse(n)
- while stack or idx < n:
- features = extract_features(words, tags, idx, n, stack, deps)
- scores = self.model.score(features)
- valid_moves = get_valid_moves(i, n, len(stack))
- next_move = max(valid_moves, key=lambda move: scores[move])
- idx = transition(next_move, idx, stack, parse)
- return tags, parse
- def get_valid_moves(i, n, stack_depth):
- moves = []
- if i < n:
- moves.append(SHIFT)
- if stack_depth >= 2:
- moves.append(RIGHT)
- if stack_depth >= 1:
- moves.append(LEFT)
- return moves
我们以标记的句子开始,进行状态初始化。然后将状态映射到一个采用线性模型评分的特征集合。接着寻找得分***的有效操作,应用到状态中。
这里的评分模型和词性标注中的一样工作。如果对提取特征和使用线性模型评分的观点感到困惑,你应该复习这篇文章。下面是评分模型如何工作的提示:
- class Perceptron(object)
- ...
- def score(self, features):
- all_weights = self.weights
- scores = dict((clas, 0) for clas in self.classes)
- for feat, value in features.items():
- if value == 0:
- continue
- if feat not in all_weights:
- continue
- weights = all_weights[feat]
- for clas, weight in weights.items():
- scores[clas] += value * weight
- return scores
这里仅仅对每个特征的类权重求和。这通常被表示为一个点积,然而我发现处理很多类时就不太适合了。
定向解析器(RedShift)遍历多个候选元素,但最终只会选择***的一个。我们将关注效率和简便而忽略其准确性。我们只进行了单一的分析。我们的搜索策略将是完全贪婪的,就像词性标记一样。我们将锁定在选择的每一步。
如果认真阅读了词性标记,你可能会发现下面的相似性。我们所做的是将解析问题映射到一个使用“扁平化”解决的序列标记问题,或者非结构化的学习算法(通过贪婪搜索)。
特征提取代码总是很丑陋。语法分析器的特征指的是上下文中的一些标识。
我们指出了上述12个标识的单词表,词性标注,和标识关联的左右孩子数目。
因为使用的是线性模型,特征指的是原子属性组成的三元组。
- def extract_features(words, tags, n0, n, stack, parse):
- def get_stack_context(depth, stack, data):
- if depth >;= 3:
- return data[stack[-1]], data[stack[-2]], data[stack[-3]]
- elif depth >= 2:
- return data[stack[-1]], data[stack[-2]], ''
- elif depth == 1:
- return data[stack[-1]], '', ''
- else:
- return '', '', ''
- def get_buffer_context(i, n, data):
- if i + 1 >= n:
- return data[i], '', ''
- elif i + 2 >= n:
- return data[i], data[i + 1], ''
- else:
- return data[i], data[i + 1], data[i + 2]
- def get_parse_context(word, deps, data):
- if word == -1:
- return 0, '', ''
- deps = deps[word]
- valency = len(deps)
- if not valency:
- return 0, '', ''
- elif valency == 1:
- return 1, data[deps[-1]], ''
- else:
- return valency, data[deps[-1]], data[deps[-2]]
- features = {}
- # Set up the context pieces --- the word, W, and tag, T, of:
- # S0-2: Top three words on the stack
- # N0-2: First three words of the buffer
- # n0b1, n0b2: Two leftmost children of the first word of the buffer
- # s0b1, s0b2: Two leftmost children of the top word of the stack
- # s0f1, s0f2: Two rightmost children of the top word of the stack
- depth = len(stack)
- s0 = stack[-1] if depth else -1
- Ws0, Ws1, Ws2 = get_stack_context(depth, stack, words)
- Ts0, Ts1, Ts2 = get_stack_context(depth, stack, tags)
- Wn0, Wn1, Wn2 = get_buffer_context(n0, n, words)
- Tn0, Tn1, Tn2 = get_buffer_context(n0, n, tags)
- Vn0b, Wn0b1, Wn0b2 = get_parse_context(n0, parse.lefts, words)
- Vn0b, Tn0b1, Tn0b2 = get_parse_context(n0, parse.lefts, tags)
- Vn0f, Wn0f1, Wn0f2 = get_parse_context(n0, parse.rights, words)
- _, Tn0f1, Tn0f2 = get_parse_context(n0, parse.rights, tags)
- Vs0b, Ws0b1, Ws0b2 = get_parse_context(s0, parse.lefts, words)
- _, Ts0b1, Ts0b2 = get_parse_context(s0, parse.lefts, tags)
- Vs0f, Ws0f1, Ws0f2 = get_parse_context(s0, parse.rights, words)
- _, Ts0f1, Ts0f2 = get_parse_context(s0, parse.rights, tags)
- # Cap numeric features at 5?
- # String-distance
- Ds0n0 = min((n0 - s0, 5)) if s0 != 0 else 0
- features['bias'] = 1
- # Add word and tag unigrams
- for w in (Wn0, Wn1, Wn2, Ws0, Ws1, Ws2, Wn0b1, Wn0b2, Ws0b1, Ws0b2, Ws0f1, Ws0f2):
- if w:
- features['w=%s' % w] = 1
- for t in (Tn0, Tn1, Tn2, Ts0, Ts1, Ts2, Tn0b1, Tn0b2, Ts0b1, Ts0b2, Ts0f1, Ts0f2):
- if t:
- features['t=%s' % t] = 1
- # Add word/tag pairs
- for i, (w, t) in enumerate(((Wn0, Tn0), (Wn1, Tn1), (Wn2, Tn2), (Ws0, Ts0))):
- if w or t:
- features['%d w=%s, t=%s' % (i, w, t)] = 1
- # Add some bigrams
- features['s0w=%s, n0w=%s' % (Ws0, Wn0)] = 1
- features['wn0tn0-ws0 %s/%s %s' % (Wn0, Tn0, Ws0)] = 1
- features['wn0tn0-ts0 %s/%s %s' % (Wn0, Tn0, Ts0)] = 1
- features['ws0ts0-wn0 %s/%s %s' % (Ws0, Ts0, Wn0)] = 1
- features['ws0-ts0 tn0 %s/%s %s' % (Ws0, Ts0, Tn0)] = 1
- features['wt-wt %s/%s %s/%s' % (Ws0, Ts0, Wn0, Tn0)] = 1
- features['tt s0=%s n0=%s' % (Ts0, Tn0)] = 1
- features['tt n0=%s n1=%s' % (Tn0, Tn1)] = 1
- # Add some tag trigrams
- trigrams = ((Tn0, Tn1, Tn2), (Ts0, Tn0, Tn1), (Ts0, Ts1, Tn0),
- (Ts0, Ts0f1, Tn0), (Ts0, Ts0f1, Tn0), (Ts0, Tn0, Tn0b1),
- (Ts0, Ts0b1, Ts0b2), (Ts0, Ts0f1, Ts0f2), (Tn0, Tn0b1, Tn0b2),
- (Ts0, Ts1, Ts1))
- for i, (t1, t2, t3) in enumerate(trigrams):
- if t1 or t2 or t3:
- features['ttt-%d %s %s %s' % (i, t1, t2, t3)] = 1
- # Add some valency and distance features
- vw = ((Ws0, Vs0f), (Ws0, Vs0b), (Wn0, Vn0b))
- vt = ((Ts0, Vs0f), (Ts0, Vs0b), (Tn0, Vn0b))
- d = ((Ws0, Ds0n0), (Wn0, Ds0n0), (Ts0, Ds0n0), (Tn0, Ds0n0),
- ('t' + Tn0+Ts0, Ds0n0), ('w' + Wn0+Ws0, Ds0n0))
- for i, (w_t, v_d) in enumerate(vw + vt + d):
- if w_t or v_d:
- features['val/d-%d %s %d' % (i, w_t, v_d)] = 1
- return features
学习权重和词性标注使用了相同的算法,即平均感知器算法。它的主要优势是,它是一个在线学习算法:例子一个接一个流入,我们进行预测,检查真实答案,如果预测错误则调整意见(权重)。
循环训练看起来是这样的:
- class Parser(object):
- ...
- def train_one(self, itn, words, gold_tags, gold_heads):
- n = len(words)
- i = 2; stack = [1]; parse = Parse(n)
- tags = self.tagger.tag(words)
- while stack or (i + 1) < n:
- features = extract_features(words, tags, i, n, stack, parse)
- scores = self.model.score(features)
- valid_moves = get_valid_moves(i, n, len(stack))
- guess = max(valid_moves, key=lambda move: scores[move])
- gold_moves = get_gold_moves(i, n, stack, parse.heads, gold_heads)
- best = max(gold_moves, key=lambda move: scores[move])
- self.model.update(best, guess, features)
- i = transition(guess, i, stack, parse)
- # Return number correct
- return len([i for i in range(n-1) if parse.heads[i] == gold_heads[i]])
训练过程中最有趣的部分是 get_gold_moves。 通过Goldbery 和 Nivre (2012),我们的语法解析器的性能可能会有所提升,他们曾指出我们错了很多年。
在词性标注文章中,我提醒大家,在训练期间,你要确保传递的是***两个预测标记做为当前标记的特征,而不是***两个黄金标记。测试期间只有预测标记,如果特征是基于训练过程中黄金序列的,训练环境就不会和测试环境保持一致,因此将会得到错误的权重。
在语法分析中我们面临的问题是不知道如何传递预测序列!通过采用黄金标准树结构,并发现可以转换为树的过渡序列,等等,使得训练得以工作,你获得返回的动作序列,保证执行运动,将得到黄金标准的依赖关系。
问题是,如果语法分析器处于任何没有沿着黄金标准序列的状态时,我们不知道如何教它做出的“正确”运动。一旦语法分析器发生了错误,我们不知道如何从实例中训练。
这是一个大问题,因为这意味着一旦语法分析器开始发生错误,它将停止在不属于训练数据的任何一种状态——导致出现更多的错误。
对于贪婪解析器而言,问题是具体的:一旦使用方向特性,有一种自然的方式做结构化预测。
像所有的***突破一样,一旦你理解了这些,解决方案似乎是显而易见的。我们要做的就是定义一个函数,此函数提问“有多少黄金标准依赖关系可以从这种状态恢复”。如果能定义这个函数,你可以依次进行每种运动,进而提问,“有多少黄金标准依赖关系可以从这种状态恢复?”。如果采用的操作可以让少一些的黄金标准依赖实现,那么它就是次优的。
这里需要领会很多东西。
因此我们有函数 Oracle(state):
Oracle(state) = | gold_arcs ∩ reachable_arcs(state) |
我们有一个操作集合,每种操作返回一种新状态。我们需要知道:
现在,至少一种操作返回0。Oracle(state)提问:“前进的***路径的成本是多少?”***路径的***步是转移,向右,或者向左。
事实证明,我们可以得出 Oracle 简化了很多过渡系统。我们正在使用的过渡系统的衍生品 —— Arc Hybrid 是 Goldberg 和 Nivre (2013)提出的。
我们把oracle实现为一个返回0-成本的运动的方法,而不是实现一个功能的Oracle(state)。这可以防止我们做一堆昂贵的复制操作。希望代码中的推理不是太难以理解,如果感到困惑并希望刨根问底的花,你可以参考 Goldberg 和 Nivre 的论文。
- def get_gold_moves(n0, n, stack, heads, gold):
- def deps_between(target, others, gold):
- for word in others:
- if gold[word] == target or gold[target] == word:
- return True
- return False
- valid = get_valid_moves(n0, n, len(stack))
- if not stack or (SHIFT in valid and gold[n0] == stack[-1]):
- return [SHIFT]
- if gold[stack[-1]] == n0:
- return [LEFT]
- costly = set([m for m in MOVES if m not in valid])
- # If the word behind s0 is its gold head, Left is incorrect
- if len(stack) >= 2 and gold[stack[-1]] == stack[-2]:
- costly.add(LEFT)
- # If there are any dependencies between n0 and the stack,
- # pushing n0 will lose them.
- if SHIFT not in costly and deps_between(n0, stack, gold):
- costly.add(SHIFT)
- # If there are any dependencies between s0 and the buffer, popping
- # s0 will lose them.
- if deps_between(stack[-1], range(n0+1, n-1), gold):
- costly.add(LEFT)
- costly.add(RIGHT)
- return [m for m in MOVES if m not in costly]
进行“动态 oracle”训练过程会产生很大的精度差异——通常为1-2%,和运行时的方式没有区别。旧的“静态oracle”贪婪训练过程已经完全过时;没有任何理由那样做了。
我感觉,语言技术,特别是那些相关语法,特别神秘。我不能想象什么样的程序可以实现。
我认为对于人们来说,***的解决方案可能相当复杂是很自然的。200,000 行的Java包感觉为宜。
但是,仅仅实现一个单一算法时,算法代码往往很短。当你只实现一种算法时,在写之前你确实知道要写什么,你不需要关注任何不必要的具有很大性能影响的抽象概念。
[1] 我真的不确定如何计算Stanford解析器的代码行数。它的jar文件装载了200k大小内容,包括大量不同的模型。这并不重要,但在50k左右似乎是安全的。
[2]例如,如何解析“John’s school of music calls”?你需要确认“John’s school”短语和“John’s school calls”、“John’s school of music calls”有相同的结构。对可以放入短语的不同的“插槽”进行推理是我们推理句法分析的关键途径。你能想到每个短语为具有不同形状的连接器,你需要插入不同的插槽——每个短语也有一定数量不同形状的插槽。我们正试图弄清楚什么样的连接器在什么地方,因此可以搞清句子是如何连接在一起的。
[3]这里有使用了“深度学习”技术的 Stanford 解析器更新版本,此版本准确性更高。但是,最终模型的准确度仍排在***的移进归约分析器后面。这是一篇伟大的文章,该想法在一个语法分析器上实现,这个语法分析器是不是***进其实并不重要。
[4]一个细节:Stanford 依赖关系实际上是给定黄金标准短语结构树自动生成的。参考这里的Stanford依赖转换器页面:http://nlp.stanford.edu/software/stanford-dependencies.shtml。
长期以来,增量语言处理算法是科学界的主要兴趣。如果你想要编写一个语法分析器来测试人类语句处理器如何工作的理论,那么,这个分析器需要建立部分解释器。这里有充分的证据,包括常识性反思,它设立我们不缓存的输入,说话者完成表达立即分析。
但与整齐的科学特征相比,当前算法胜出!尽我所能告诉大家,胜出的秘诀就是:
和人类语句处理的联系看起来诱人。我期待看到这些工程的突破是否带来一些心理语言学方面的进步。
NLP 的文献几乎完全开放。所有相关论文都可以在这里找到:http://aclweb.org/anthology/。
我所描述的解析器是动态oracle arc-hybrid 系统的实现:
Goldberg, Yoav; Nivre, Joakim
Training Deterministic Parsers with Non-Deterministic Oracles
TACL 2013
然而,我编写了自己的特征。arc-hybrid 系统的最初描述在这里:
Kuhlmann, Marco; Gomez-Rodriguez, Carlos; Satta, Giorgio
Dynamic programming algorithms for transition-based dependency parsers
ACL 2011
这里最初描述了动态oracle训练方法:
A Dynamic Oracle for Arc-Eager Dependency Parsing
Goldberg, Yoav; Nivre, Joakim
COLING 2012
当Zhang 和 Clark 研究定向搜索时,这项工作依赖于以转换为基础的解析器在准确性上的重大突破。他们发表了很多论文,但***的引用是:
Zhang, Yue; Clark, Steven
Syntactic Processing Using the Generalized Perceptron and Beam Search
Computational Linguistics 2011 (1)
另外一篇重要的文章是这个短篇的特征工程文章,这篇文章进一步提高了准确性:
Zhang, Yue; Nivre, Joakim
Transition-based Dependency Parsing with Rich Non-local Features
ACL 2011
作为定向解析器的学习框架,广义的感知器来自这篇文章
Collins, Michael
Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms
EMNLP 2002
文章开头的结果引用了华尔街日报语料库第22条。Stanford 解析器执行如下:
- java -mx10000m -cp "$scriptdir/*:" edu.stanford.nlp.parser.lexparser.LexicalizedParser
- -outputFormat "penn" edu/stanford/nlp/models/lexparser/englishFactored.ser.gz $*
应用了一个小的后处理,撤销Stanford 解析器为数字添加的假设标记,使数字符合 PTB 标记:
- """Stanford parser retokenises numbers. Split them."""
- import sys
- import re
- qp_re = re.compile('xc2xa0')
- for line in sys.stdin:
- line = line.rstrip()
- if qp_re.search(line):
- line = line.replace('(CD', '(QP (CD', 1) + ')'
- line = line.replace('xc2xa0', ') (CD ')
- print line
由此产生的PTB格式的文件转换成使用 Stanford 转换器的依赖关系:
- for f in $1/*.mrg; do
- echo $f
- grep -v CODE $f > "$f.2"
- out="$f.dep"
- java -mx800m -cp "$scriptdir/*:" edu.stanford.nlp.trees.EnglishGrammaticalStructure
- -treeFile "$f.2" -basic -makeCopulaHead -conllx > $out
- done
我不能轻易的读取了,但它应该只是使用相关文献的一般设置,将一个目录下的每个.mrg文件转换成一个CoNULL格式的 Stanford 基本依赖文件。
接着我从华尔街日报语料库第22条转换了黄金标准树进行评估。准确的分数是指所有未标记标识中未标记的附属分数(如弧头索引)
为了训练 parser.py,我将华尔街日报语料库 02-21 的黄金标准 PTB 树结构输出到同一个转换脚本中。
一言以蔽之,Stanford 模型和 parser.py 在同一组语句中进行训练,在我们知道答案的持有测试集上进行预测。准确性是指我们答对多少正确的语句首词。
在一个 2.4Ghz 的 Xeon 处理器上测试速度。我在服务器上进行了实验,为 Stanford 解析器提供了更多内存。parser.py 系统在我的MacBook Air上运行良好。在parser.py 的实验中,我使用了PyPy;与早期的基准相比,CPython大约快了一半。
parser.py 运行如此之快的一个原因是它进行未标记解析。根据以往的实验,经标记的解析器可能慢400倍,准确度提高大约1%。如果你能访问数据,使程序适应已标记的解析器对读者来说将是很好的锻炼机会。
RedShift 解析器的结果是从版本 b6b624c9900f3bf 取出的,运行如下:
- ./scripts/train.py -x zhang+stack -k 8 -p ~/data/stanford/train.conll ~/data/parsers/tmp
- ./scripts/parse.py ~/data/parsers/tmp ~/data/stanford/devi.txt /tmp/parse/
- ./scripts/evaluate.py /tmp/parse/parses ~/data/stanford/dev.conll
原文链接: honnibal 翻译: 伯乐在线 - lulu
译文链接: http://blog.jobbole.com/67009/
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
