社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
用过Docker的开发者都知道,Docker容器在本质上是宿主机上的一个进程。也就是常说的容器是操作系统级的虚拟化。容器与容器之间做了资源的隔离,所以在一个容器内部的各种操作会给人一种仿佛在独立的系统环境中的感觉。外部应用对容器进行访问时,也会有这种感觉。而做这种容器资源隔离的Linux内核机制就是namespace。
在具体了解namespace之前,我们先感受一下namespace的存在。
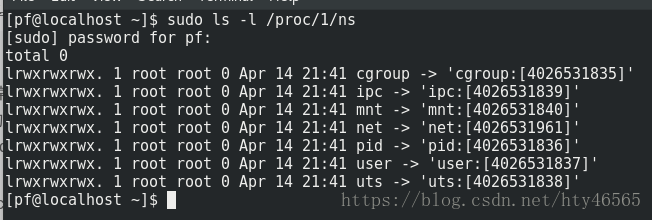
我们可以使用命令sudo ls -l /proc/[pid]/ns查看pid为[pid]的进程所属的namespace。比如我查看pid为1的进程。
可以看到namespace共分为7种类型。分别为ipc、mnt、pid、uts、net、cgroups、user。
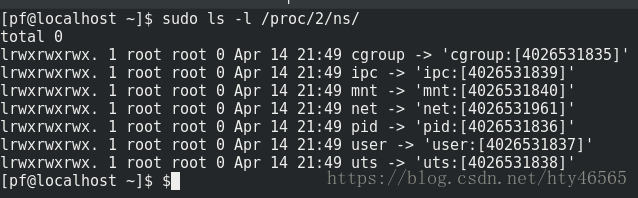
如果某个软链接如ipc指向了同一个ipc namespace,那么这两个进程则是在同一个ipc namespace下的。如
我们可以看到pid为2的进程与pid为1的进程同属一个ipc namespace。因为它们的指向相同。
以此类推,这两个进程的mnt、net、pid、user、cgroups、uts namespace也都相同。
如若两个进程某个软链接指向不同,即说明这两个进程该资源已经被隔离了。
既然我们知道了实现容器资源隔离的Linux内核机制是namespace,那么,我们就想了解一下Linux提供的namespace操作API。
包括有clone(),setns(),unshare(),接下来分别做简单介绍:
clone()系统调用大家应该都比较熟悉,它的功能是创建一个新的进程。有别于系统调用fork(),clone()创建新进程时有许多的选项,通过选择不同的选项可以创建出合适的进程。我们也可以使用clone()来创建一个属于新的namespace的进程。这是Docker使用namespace的最基本的方法。
我们可以用man命令查看clone()的调用方式。
fn:传入子进程运行的程序主函数
child_stack:传入子进程使用的栈空间
flags:使用哪些标志位,与namespace相关的标志位主要包括CLONE_NEWIPC、CLONE_NEWPID、CLONE_NEWNS、CLONE_NEWNET、CLONE_USER、CLONE_UTS。具体含义后面会详述。
arg:传入的用户参数
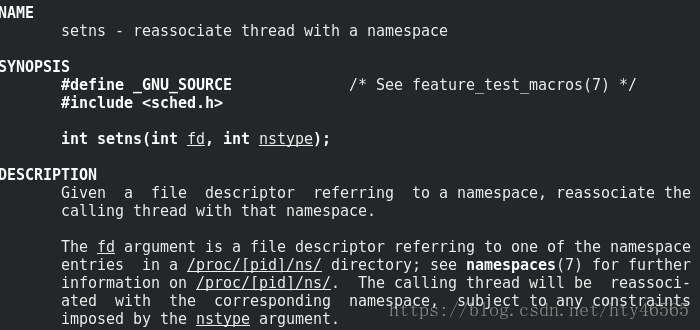
这个系统调用顾名思义就是设置namespace。详细说来,就是将进程加入到一个已经存在的namespace中。对应于Docker的操作就是在一个Docker容器中用exec运行一个新命令。因为一个Docker容器其实就是一个已经存在的namespace,而用Docker exec执行一个命令,就是将该命令在该容器的namespace中运行,也就是将该命令的进程加入到一个已经存在的namespace中。
依然用man命令看一下这个系统调用的使用。
fd:表示要加入的namespace的文件描述符。它是一个指向/proc/[pid]/ns目录的文件描述符,可以通过直接打开该目录下的链接得到。
nstype:让调用者可以检查fd指向的namespace类型是否符合实际的要求。参数为0表示不检查。
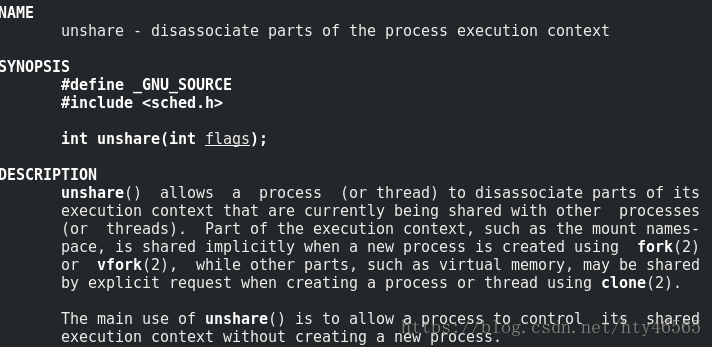
这个系统调用与clone()很像,都是做一个新的隔离。而且都通过选择flags来选择隔离的资源。不同之处在于clone()创建了一个新的进程,而unshare()是在原进程上作隔离。
参数flags是标志位,选择需要隔离的资源。与clone()的falgs参数基本相同,这里就不赘述了。
mount namespace通过隔离文件系统挂载点对文件系统进行隔离。隔离之后,不同的mount namespace下的文件结构发生变化也不会互相影响。或许有人注意到,在clone()的flags中,表示新mount namespace的标志位是CLONE_NEWNS。这是因为mount namespace是历史上第一个Linux namespace。
cgroup Namspace虚拟化了进程的cgroups视图。cgroups是Linux内核的一个工具,用来做资源的限制的。这里对此就不详述了,下次会写一篇专门讲述cgroups机制的文章。
我们都知道,在Linux操作系统中,每一个进程的PID都是在系统中是唯一的。而在容器中,进程的PID可以和另一个容器中某进程的PID相同。这就是对PID的虚拟化。因为两个容器处于不同的PID namespace下,所以这两个容器的PID可以有重复出现。
另外,每一个PID namespace下都会有一个PID为1的进程,它会像传统Linux中的init进程一样拥有特权,起特殊作用。
我们可以写一段代码来感受下PID namespace的隔离。
#define _GNU_SOURCE
#include<sys/types.h>
#include<sys/wait.h>
#include<stdio.h>
#include<sched.h>
#include<signal.h>
#include<unistd.h>
#define STACK_SIZE (1024*1024)
static char child_stack[STACK_SIZE];
char * const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void *args) {
printf("在子进程中!n");
execv(child_args[0],child_args);
return 1;
}
int main() {
printf("程序开始:n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID|SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出n");
return 0;
}
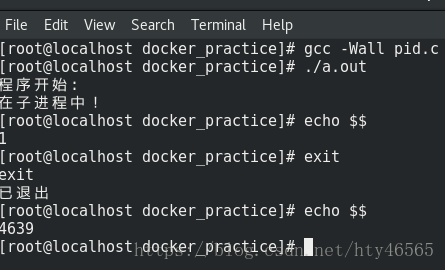
编译运行代码,结果如下
我们可以看到,使用clone()新创建了一个进程并进行隔离之后,此当前进程的pid为1。当退出进程后当前进程号又恢复为4639。这个pid为1的进程就是PID namespace中的第一进程,也就是我刚才说的像是Linux下拥有特权的init进程。
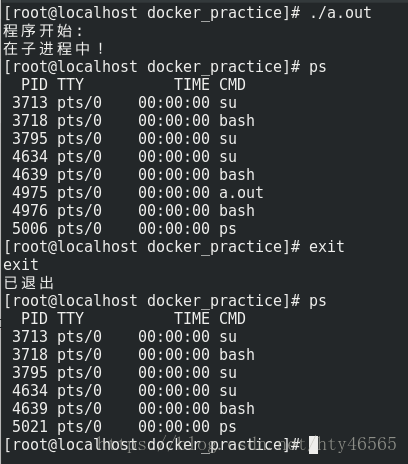
我们也可以在新的PID namespace下看看ps命令的结果。
奇怪的是,为什么在新PID Namespce下使用ps命令还是能看到所有的进程呢?难道不是已经将PID隔离了吗?理论上应该是不能看到的。
这是因为ps命令或者top命令都是从Linux系统中的/proc目录下取值的。因为这个时候我们和还没有用mount namespace进行挂载点的隔离,所以我们总是可以看到这些PID。
同样的道理,IPC namespace也是一种namespace,它隔离了IPC(进程间通信)如信号量、消息队列和共享内存。在同一个IPC namespace下的进程互相可见,不同IPC namespace下的进程互相不可见。
我们看下如下示例:
#define _GNU_SOURCE
#include<sys/types.h>
#include<sys/wait.h>
#include<stdio.h>
#include<sched.h>
#include<signal.h>
#include<unistd.h>
#define STACK_SIZE (1024*1024)
static char child_stack[STACK_SIZE];
char * const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void *args) {
printf("在子进程中!n");
execv(child_args[0],child_args);
return 1;
}
int main() {
printf("程序开始:n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWIPC|SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出n");
return 0;
}
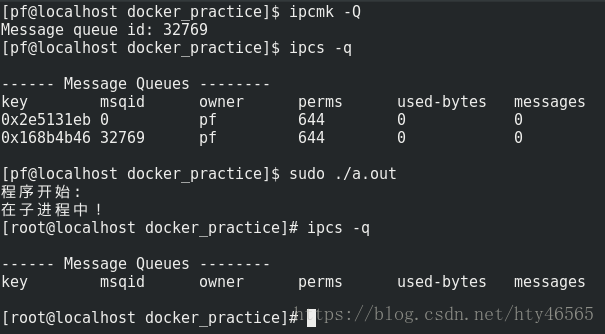
如图,首先我们使用ipcmk -Q创建了一个消息队列。可以知道,这个消息队列是在该IPC namespace下的。然后我们依然通过clone()创建了一个新进程,该进程位于新的IPC namespace中。于是使用ipcs -q命令查看该namespace下的消息队列,发现在刚才namespace下创建的消息队列在该namespace下并没有出现。这就说明了IPC namespace将进程间通信消息队列隔离了。
user namespace主要隔离安全相关的标识符和属性,包括用户ID、用户组ID、root目录、key以及特殊权限。简单来说,我们可以在Linux中用非root的用户来创建一个容器,它创建的容器进程却属于拥有超级权限的用户。
UTS(Unix Time-sharing System) namespace提供了主机名与域名的隔离。这样,我们每一个容器都可以拥有自己独立的主机名和域名了,在外部进行访问时好似访问了一个独立的节点。
同样,我们用clone()创建一个位于新的UTS namespace下的新进程。
#define _GNU_SOURCE
#include<sys/types.h>
#include<sys/wait.h>
#include<stdio.h>
#include<sched.h>
#include<signal.h>
#include<unistd.h>
#define STACK_SIZE (1024*1024)
static char child_stack[STACK_SIZE];
char * const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void *args) {
printf("在子进程中!n");
sethostname("Newnamespace",12);
execv(child_args[0],child_args);
return 1;
}
int main() {
printf("程序开始:n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS|SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出n");
return 0;
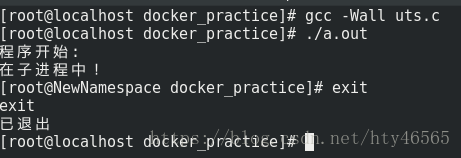
}编译并运行代码:
我们发现,在运行这个程序后主机名改为了Newnamespace了,这就说明,在新的UTS namespace下,主机名被隔离了,我们允许每个容器拥有自己独立的主机名和域名。
network namespace主要提供了关于网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、套接字等。简单说,我们在每个容器中都可以启动一个Apache进程并占用“80端口”而不会出现端口冲突。我们知道,假设计算机只有一个物理网络设备时,该设备只能位于一个network namespace下提供网络服务。解决的方法是通过创建veth pair在不同的network namespace间进行通信。
本文从功能角度分类讨论了namespace。并举了一些例子进行实际感受。实际上Docker底层的内核知识不仅包括用来资源隔离的namespace,还包括用来作资源限制与资源监控的cgroups。下一篇文章会简述cgroups的功能及原理。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!