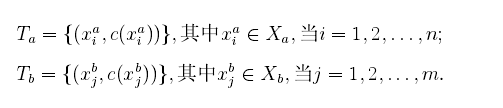社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
TradaBoost算法由来已久,现在也有各种针对算法的该进,本文只讨论最初的算法。
1.迁移学习
传统的机器学习的模型都是建立在训练数据和测试数据服从相同的数据分布的基础上。典型的比如有监督学习,我们可以在训练数据上面训练得到一个分类器,用于测试数据。但是在许多的情况下,这种同分布的假设并不满足,有时候我们的训练数据会期,而重新去标注新的数据又是十分昂贵的。这个时候如果丢弃训练数据又是十分可惜的,所以我们就想利用这些不同分布的训练数据,训练出一个分类器,在我们的测试数据上可以取得不错的分类效果。
迁移学习的目标就是将从一个环境中学习得到的知识用于新环境的学习任务,迁移学习不会像传统的机器学习那样同分布假设,迁移学习的思想在我们的生活中也是很常见的,比如说一旦你学会了骑自行车,那么学习骑摩托车是很方便的。
定义迁移学习的模型如下:设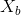
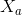
测试数据:
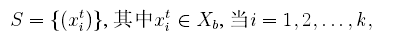
其中测试数据是未标注的,我么可以将训练数据划分为两个数据集:
其中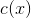
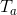
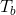
2.TrAdaBoost算法
我们利用AdaBoost算法的思想原理来解决这个问题,起初给训练数据T中的每一个样例都赋予一个权重,当一个源域
可以看到,在每一轮的迭代中,如果一个辅助训练数据被误分类,那么这个数据可能和源训练数据是矛盾的,那么我们就可以降低这个数据的权重。具体来说,就是给数据乘上一个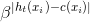
可以看到,TrAdaBoost算法在源数据和辅助数据具有很多的相似性的时候可以取得很好效果,但是算法也有不足,当开始的时候辅助数据中的样本如果噪声比较多,迭代次数控制的不好,这样都会加大训练分类器的难度。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!