社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
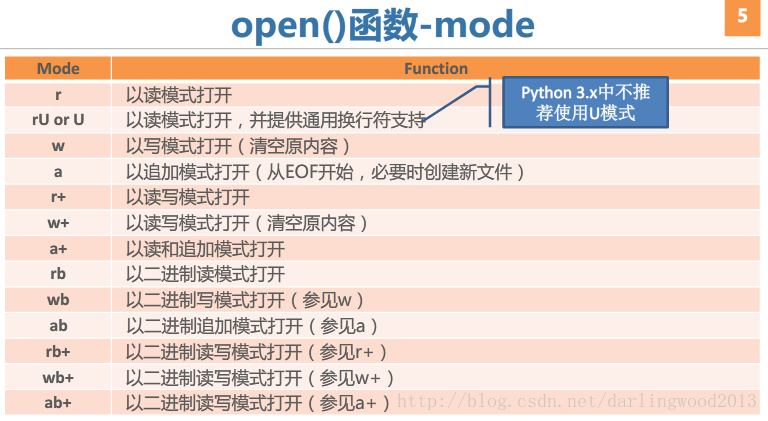
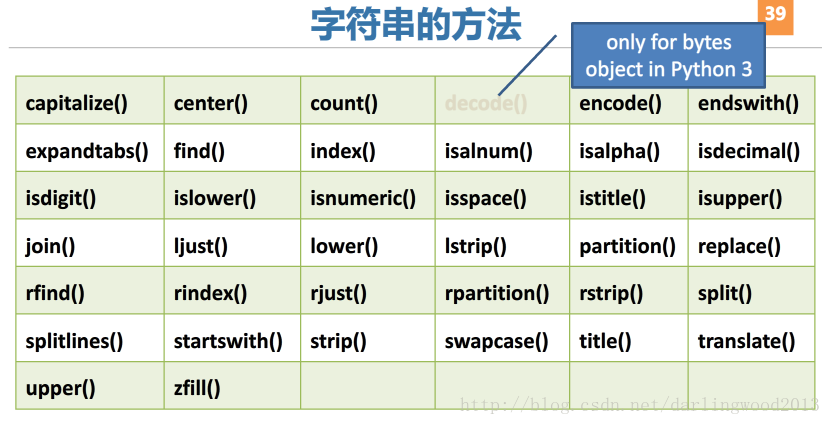
文件读写
file_obj=open(filename,mode='r',buffering=-1)
#其中mode为可选参数,默认值为r
#buffering为可选参数,默认值为-1
#(0代表不缓冲,>=1的值表示缓冲一行或指定缓冲区的大小)
#可以以文本文件方式或二进制文件方式打开
#open()函数返回一个文件(file)对象,文件对象可迭代将文件中的字符串读出,加上序号然后写进去。
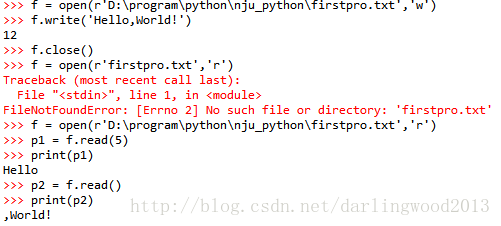
f = open(r'D:programpythonnju_pythonfirstpro.txt','r')
line = f.readlines()
#此处line的数据类型是list
for i in range(0,len(line)):
line[i]=str(i+1)+'.'+line[i]
f.close()
f1 = open(r'D:programpythonnju_pythonfirstpro.txt','w')
#这里用write()函数就不行,因为其只接受str参数
f1.writelines(line)
f1.close()小程序
#创建文件并写入歌词
f = open (r'D:programpythonnju_pythonBlowing in the wind.txt','w')
f.write('How many roads must a man walk downnBefore they call him a mann
How many seas must a white dove sailnBefore she sleeps in the sandn
How many times must the cannon balls flynBefore they're forever bannedn
The answer my friend is blowing in the windnThe answer is blowing in the windn')
f.close()
#插入歌名
f1 = open (r'D:programpythonnju_pythonBlowing in the wind.txt','r+')
sname='Blowin’ in the windn'
#print(f1.read())
s=sname+f1.read()
#print(s)
#前面read()完之后文件指针在文件末尾,记得seek回来
f1.seek(0,0)
f1.write(s)
f1.close()
#插入歌手及创作年份等
f2 = open (r'D:programpythonnju_pythonBlowing in the wind.txt','r+')
content = f2.read()
content_add = 'Bob Dylan'
pos = content.find('nHow many roads must a man walk down')
if pos!=-1:
content = content[:pos] + '-'+content_add + content[pos:]
f2.seek(0,0)
f2.write(content)
f2.seek(0,2)
f2.write('1962 by Warner Bros. Inc.')
f2.seek(0,0)
print(f2.read())
f2.close()从网络获取数据
import urllib.request
r = urllib.request.urlopen("https://www.baidu.com/")
html = r.read()
print(html)对象身份比较:
在 python2中,<>表示!=的意思,在python中已不再支持<>。
序列:字符串、列表、元组
>>> week=['MON','TUE','WED','THU','FRI','SAT','SUN']
>>> print(week[::-3])
['SUN', 'THU', 'MON']
>>> print(week[::-2])
['SUN', 'FRI', 'WED', 'MON']
>>> print(week[::-1])
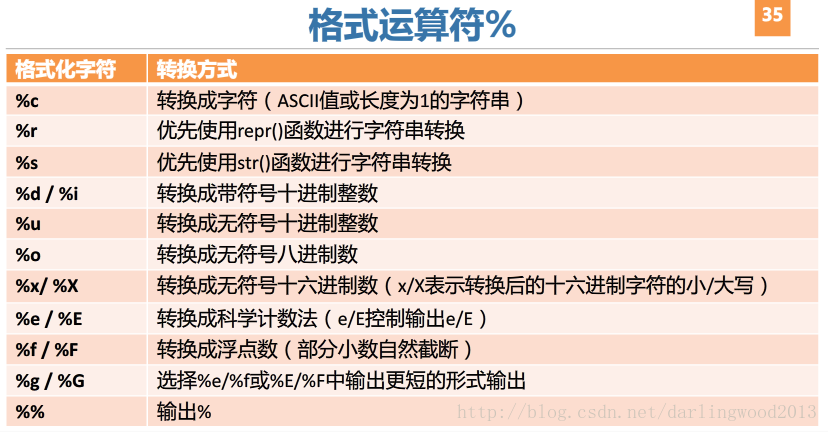
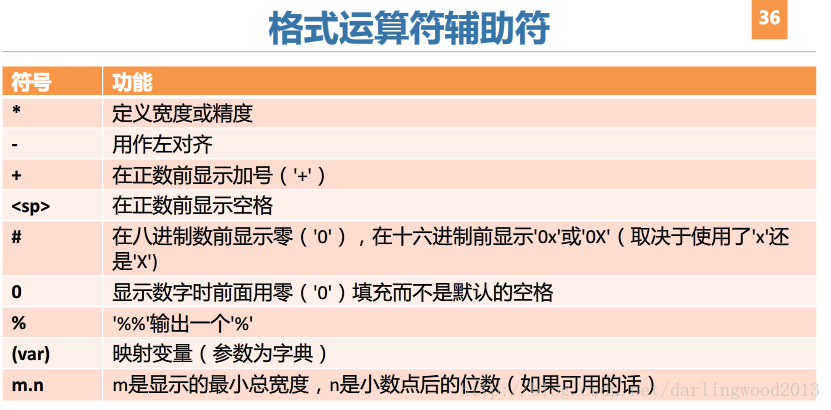
['SUN', 'SAT', 'FRI', 'THU', 'WED', 'TUE', 'MON']格式输出
aStr = 'What do you think of this saying "No pain,No gain"?'
#lindex = aStr.index('"',0,len(aStr))
#rindex = aStr.rindex('"',0,len(aStr))
#tempStr = aStr[lindex+1:rindex]
#上面三句可由下面一句代替
#表示用"将字符串分为三部分,我们需要第二部分,即下标为1的部分
tempstr = aStr.split('"')[1]
if tempstr.istitle():
print('It is title format.')
else:
print('It is not title format.')
print(tempstr.title())列表
同一个列表中可以包含不同的数据类型。
列表是可变的。
eg b = [1,2,'p',3.5] #包涵整形、字符串和实型week = ['MON','TUE','WED','THU','FRI']
weekend = ['SAT','SUN']
week.extend(weekend)
#enumerate()序号默认从0开始
for i,j in enumerate(week):
print(i+1,j)
输出:
1 MON
2 TUE
3 WED
4 THU
5 FRI
6 SAT
7 SUN
动态创建列表!厉害厉害!
元组
元组使用场合:
单元测验
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> numbers[0: -1]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> numbers[0::3]
[1, 4, 7, 10]
>>> numbers[-2:]
[9, 10]
>>> numbers[0: 2]
[1, 2]编程题
第一题
统计字符串中各个字母出现次数,不区分大小写:
#法一:
def countchar(str):
charmap=[]
#初始化
#只有添加进去元素之后才能用下标访问
#不能通过下标添加元素
for i in range(26):
charmap.append(0)
str=str.upper()
for c in str:
if c.isalpha():
charmap[ord(c)-65]+=1
return charmap
if __name__ == "__main__":
str = input()
print(countchar(str))
#法二:
def countchar(str):
#字典
charmap={}
#初始化
#chr(i)函数表示返回整数i对应的ASCII字符。与ord()作用相反
#参数i是取值范围[0, 255]之间的正数
for i in range(26):
charmap[chr(i+65)]=0
str=str.upper()
for c in str:
if ord('A')<=ord(c)<=ord('Z'):
charmap[c]+=1
return [charmap[chr(i+65)] for i in range(26)]
if __name__ == "__main__":
str = input()
print(countchar(str))第二题
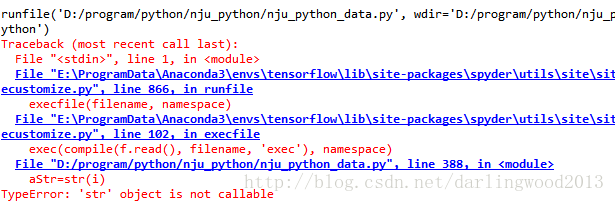
获取多个网页内容并打印在文件里
import urllib.request
for i in range(0,10):
aStr=str(i)
print(aStr)
url_str='http://tieba.baidu.com/p/100000000'+aStr
r = urllib.request.urlopen(url_str)
html = r.read()
url_str=r'D:programpythonnju_python100000000'+aStr+'.html'
f = open(url_str,'w')
f.write(html)
#遇到很神奇的错误,不能解决,把错误贴在下面如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!