社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
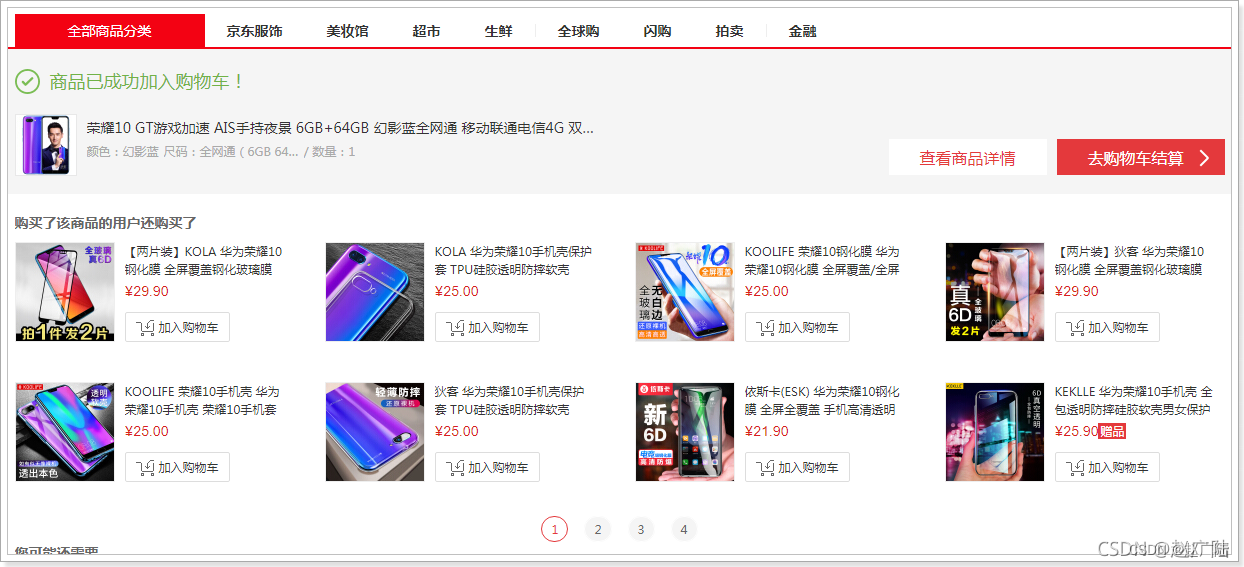
什么是智能推荐?
定义: 根据用户行为习惯所提供的数据, 系统提供策略模型,自动推荐符合用户行为的信息。
例举:
比如根据用户对商品的点击数据(时间周期,点击频次), 推荐类似的商品;
根据用户的评价与满意度, 推荐合适的品牌;
根据用户的使用习惯与点击行为,推荐类似的资讯。
应用案例:
什么是实时数仓
数据仓库(Data Warehouse),可简写为DW或DWH,是一个庞大的数据存储集合,通过对各种业务数
据进行筛选与整合,生成企业的分析性报告和各类报表,为企业的决策提供支持。实时仓库是基于
Storm/Spark(Streaming)/Flink等实时处理框架,构建的具备实时性特征的数据仓库。
应用案例
分析物流数据, 提升物流处理效率。
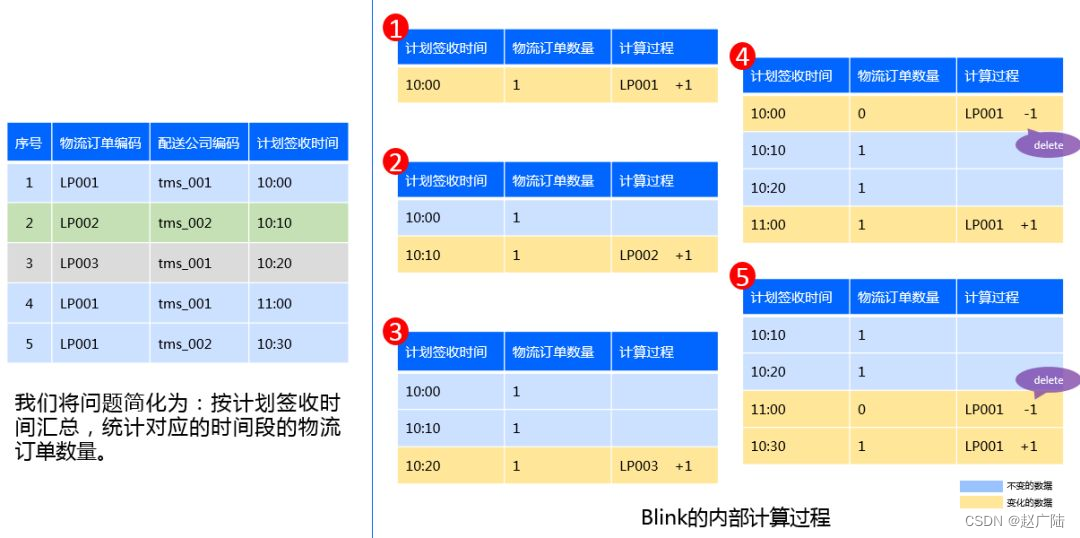
阿里巴巴菜鸟网络实时数仓设计:
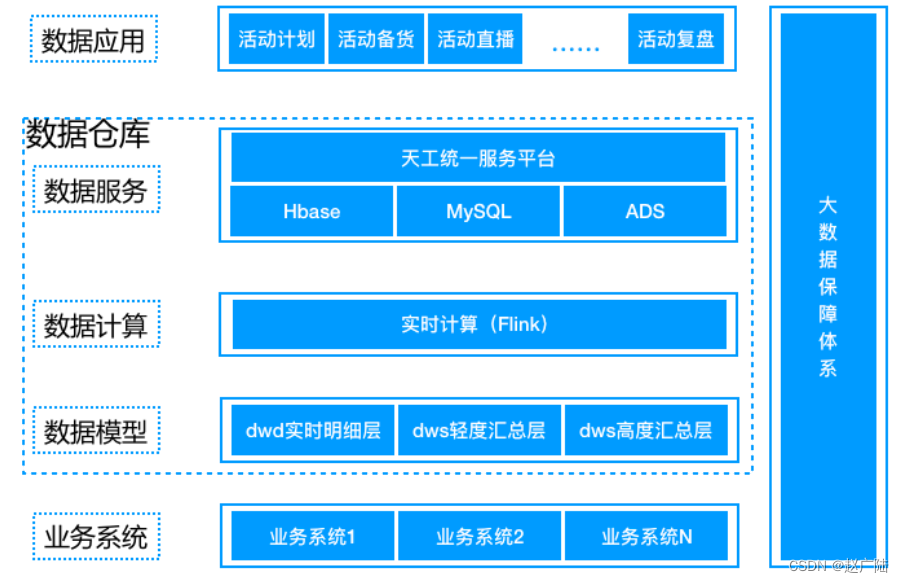
数仓分层处理架构(流式ETL):
ODS -> DWD -> DWS -> ADS
ODS(Operation Data Store):操作数据层, 一般为原始采集数据。
DWD(Data Warehouse Detail) :明细数据层, 对数据经过清洗,也称为DWI。
DWS(Data Warehouse Service):汇总数据层,基于DWD层数据, 整合汇总成分析某一个主题域的服
务数据,一般是宽表, 由多个属性关联在一起的表, 比如用户行为日志信息:点赞、评论、收藏等。
ADS(Application Data Store): 应用数据层, 将结果同步至RDS数据库中, 一般做报表呈现使用。
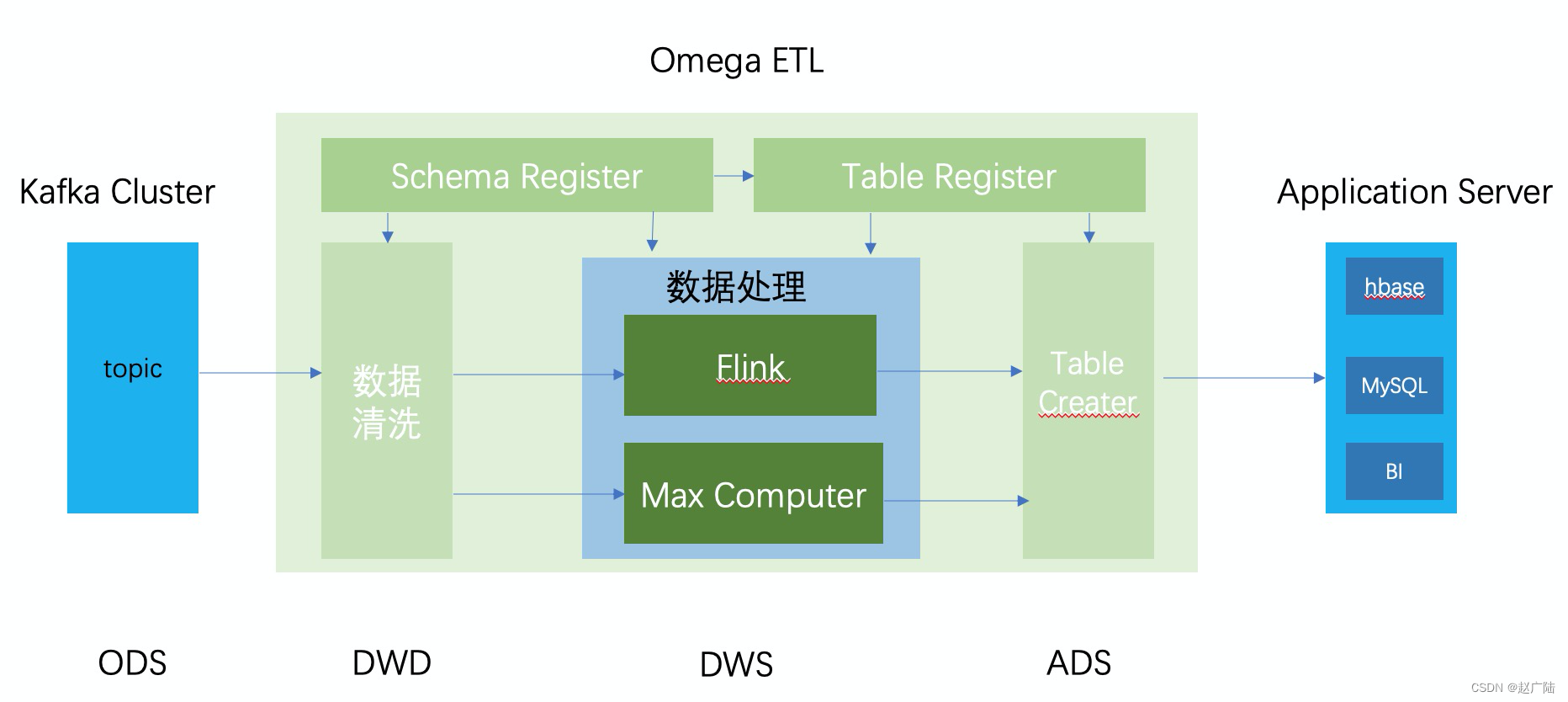




Flink 连接器包含数据源输入与汇聚输出两部分。Flink自身内置了一些基础的连接器,数据源输入包含文件、目录、Socket以及 支持从collections 和 iterators 中读取数据;汇聚输出支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
官方地址
Flink还可以支持扩展的连接器,能够与第三方系统进行交互。目前支持以下系统:
Flink还可以支持扩展的连接器,能够与第三方系统进行交互。目前支持以下系统:
常用的是Kafka、ES、HDFS以及JDBC。
Flink Connectors JDBC 如何使用?
功能: 将集合数据写入数据库中
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.11.2</version>
</dependency>
代码:
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
public class JDBCConnectorApplication {
public static void main(String[] args)throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建集合数据
List<String> list = Arrays.asList(
"192.168.116.141\t1601297294548\tPOST\taddOrder",
"192.168.116.142\t1601297294549\tGET\tgetOrder"
);
// 3. 读取集合数据,写入数据库
env.fromCollection(list).addSink(JdbcSink.sink(
// 配置SQL语句
"insert into t_access_log(ip, time, type, api) values(?, ?, ?, ?)",
new JdbcStatementBuilder<String>() {
@Override
public void accept(PreparedStatement preparedStatement,
String s) throws SQLException {
System.out.println("receive ====> " + s);
// 解析数据
String[] elements = String.valueOf(s).split("\t");
for (int i = 0; i < elements.length; i++) {
// 新增数据
preparedStatement.setString(i+1, elements[i]);
}
}
},
// JDBC 连接配置
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://192.168.116.141:3306/flink?useSSL=false")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build()
));
// 4. 执行任务
env.execute("jdbc-job");
}
}
数据表:
DROP TABLE IF EXISTS `t_access_log`;
CREATE TABLE `t_access_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`ip` varchar(32) NOT NULL COMMENT 'IP地址',
`time` varchar(255) NULL DEFAULT NULL COMMENT '访问时间',
`type` varchar(32) NOT NULL COMMENT '请求类型',
`api` varchar(32) NOT NULL COMMENT 'API地址',
PRIMARY KEY (`id`)
) ENGINE = InnoDB AUTO_INCREMENT=1;
自定义写入数据源
功能:读取Socket数据, 采用流方式写入数据库中。
代码:
public class CustomSinkApplication {
public static void main(String[] args)throws Exception {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取Socket数据源
DataStreamSource<String> socketTextStream =
env.socketTextStream("192.168.116.141", 9911, "\n");
// 3. 转换处理流数据
SingleOutputStreamOperator<AccessLog> outputStreamOperator =
socketTextStream.map(new MapFunction<String, AccessLog>() {
@Override
public AccessLog map(String s) throws Exception {
System.out.println(s);
// 根据分隔符解析数据
String[] elements = s.split("\t");
// 将数据组装为对象
AccessLog accessLog = new AccessLog();
accessLog.setNum(1);
for (int i = 0; i < elements.length; i++) {
if (i == 0) accessLog.setIp(elements[i]);
if (i == 1) accessLog.setTime(elements[i]);
if (i == 2) accessLog.setType(elements[i]);
if (i == 3) accessLog.setApi(elements[i]);
}
return accessLog;
}
});
// 4. 配置自定义写入数据源
outputStreamOperator.addSink(new MySQLSinkFunction());
// 5. 执行任务
env.execute("custom jdbc sink");
}
自定义数据源
private static class MySQLSinkFunction extends RichSinkFunction<AccessLog>{
private Connection connection;
private PreparedStatement preparedStatement;
@Override
public void open(Configuration parameters) throws Exception {
String url="jdbc:mysql://192.168.11.14:3306/flik?useSSL=fales";
String username="admin";
String password="admin";
connection= DriverManager.getConnection(url,username,password);
String sql="insert into xxx_log(ip,time,type,api) valuse(?,?,?,?)"
preparedStatement=connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
try {
if (null==connection)connection.close();
connection=null;
}catch (Exception e){
e.printStackTrace();
}
}
@Override
public void invoke(AccessLog accessLog, Context context) throws Exception {
preparedStatement.setString(1,accessLog.getIp());
preparedStatement.setString(2,accessLog.getTime());
preparedStatement.setString(3,accessLog.getType());
preparedStatement.setString(4,accessLog.getApi());
preparedStatement.execute();
}
}
AccessLog:
@Data
public class AccessLog {
/**
* IP地址
*/
private String ip;
/**
* 访问时间
*/
private String time;
/**
* 请求类型
*/
private String type;
/**
* API地址
*/
private String api;
private Integer num;
}
测试数据:注意 \t
192.168.116.141 1603166893313 GET getOrder
192.168.116.142 1603166893314 POST addOrder
自定义读取数据源
功能: 读取数据库中的数据, 并将结果打印出来。
代码:
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 配置自定义MySQL读取数据源
DataStreamSource<AccessLog> streamSource = env.addSource(new
MySQLSourceFunction());
// 3. 设置并行度
streamSource.print().setParallelism(1);
// 4. 执行任务
env.execute("custom jdbc source");
}
通过Sink写入HDFS数据
功能: 将Socket接收到的数据, 写入至HDFS文件中。
依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.1</version>
</dependency>
代码:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.fs.StringWriter;
import org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink;
import org.apache.flink.streaming.connectors.fs.bucketing.DateTimeBucketer;
public class HDFSSinkApplication {
public static void main(String[] args) {
// 1. 创建运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取Socket数据源
// DataStreamSource<String> socketTextStream =
env.socketTextStream("127.0.0.1", 9911, "\n");
DataStreamSource<String> socketTextStream =
env.socketTextStream("192.168.116.141", 9911, "\n");
// 3. 创建hdfs sink
BucketingSink<String> bucketingSink = new BucketingSink<>("F:/oldlu/Flink/hdfs");
bucketingSink.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd--HHmm"));
bucketingSink.setWriter(new StringWriter())
.setBatchSize(5 * 1024)// 设置每个文件的大小
.setBatchRolloverInterval(5 * 1000)// 设置滚动写入新文件的时间
.setInactiveBucketCheckInterval(30 * 1000)// 30秒检查一次不写入 的文件
.setInactiveBucketThreshold(60 * 1000);// 60秒不写入,就滚动写入新的文件
// 4. 写入至HDFS文件中
socketTextStream.addSink(bucketingSink).setParallelism(1);
// 5. 执行任务
env.execute("flink hdfs source");
}
}
数据源模拟实现:
<!-- Netty 核心组件依赖 -->
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.16.Final</version>
</dependency>
<!-- spring boot 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<!-- Spring data jpa 组件依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.jdbc.version}</version>
</dependency>
<!-- Redis 缓存依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
