社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
其实我对爬虫还挺感兴趣的,因为我玩instagram(需要科学上网),上过IG的人都知道IG虽然是个晒图APP,但是它的图不管是手机端还是网页端都是不提供下载的,连右键另存为都没有。当然,稍微懂一点计算机的在网页端翻翻源码找找下载链接也是能下载,但对大众来说,看到好看的图,又不能下载是一件很讨厌的事。
之前我是怎么下的呢,我先把PO文地址发给inskeeper微信公众号,然后对面就会返回图给我。
这次老师让我们做爬虫,我一下就想到了这件事,公众号能够根据链接给我返图,很明显是服务器端根据链接用爬虫把图爬了下来。我就想自己写一个爬虫,也能给个链接把图爬下来。而且,我还想更方便一点,给个某个人的IG首页地址,我就自动把他发过的所有图片和视频都一次性打包下载下来,想想就很爽啊。代码就是懒人的天堂,要是什么事都能一次码几行代码,以后千年万年再遇到这事打开运行一下就完事,那世界多美好啊!
我这次做的是爬图:
至于,用开发者模式写爬虫的基本姿势、静态多页怎么爬,动态瀑布流网页又怎么爬请自行参考Refenrence中链接网址,百度贴吧的源码我不记得是来自哪个网址了= = 如果原作者看到求原谅!!在评论备注吧感激不尽!!
我的代码主干基本来自大佬们的博客,只是做了增加或者改动,其中IG爬取的代码改动较大,我将POST方式改为了PUT方式,POST以及不能得到Json了。
这个是第一次写(改= =)Python,代码结构乱请原谅…比较久远的代码懒得改了= =
很简单,自行读代码+百度。忘了大佬原博客真的抱歉= =
这里我做到改动是,将小图链接进一步爬取转换成了大图链接。
源码如下:GitHub下载:BaiduBarOnePageCrawler.py
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取贴吧/图库图片
import requests
import re
# 根据url获取网页html内容
def getHtmlContent(url):
page = requests.get(url)
return page.text
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
def getJPGs(html):
# 解析jpg图片url的正则
jpgs = []
print(jpgs)
#https: // www.instagram.com / p / BgfjlvlDg4H /?taken - by = tee_jaruji
jpgReg1 = re.compile(r'"shortcode":"(.+?)"')
print(jpgReg1)
jpgs1 = re.findall(jpgReg1, html)
print(jpgs1)
for url1 in jpgs1:
print('https://www.instagram.com/p/'+url1+'/?taken-by=tee_jaruji')
html = getHtmlContent('https://www.instagram.com/p/'+url1+'/?taken-by=tee_jaruji')
#750w,https://scontent-nrt1-1.cdninstagram.com/vp/cdb59589c0f5abc42a923bf73b5506d0/5B36AA4F/t51.2885-15/e35/29415875_200094744088937_5818414838958784512_n.jpg 1080w"
#print(html)
jpgReg2 = re.compile(r'750.+?{"src":"(https://.+?.jpg)","config_width":1080')
print(jpgReg2)
jpgs2 = re.findall(jpgReg2,html)
print(jpgs2)
if len(jpgs2)!=0:
jpgs.append(jpgs2[0])
print(jpgs)
return jpgs
# 用图片url下载图片并保存成制定文件名
def downloadJPG(imgUrl,fileName):
# 可自动关闭请求和响应的模块
from contextlib import closing
with closing(requests.get(imgUrl,stream = True)) as resp:
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk)
# 批量下载图片,默认保存到当前目录下
def batchDownloadJPGs(imgUrls,path = './img/'):
# 用于给图片命名
count = 1
for url in imgUrls:
print(url)
downloadJPG(url,''.join([path,'{0}.jpg'.format(count)]))
print('下载完成第{0}张图片'.format(count))
count = count + 1
# 封装:从百度贴吧网页下载图片
def download(url):
html = getHtmlContent(url)
#print(html)
jpgs = getJPGs(html)
batchDownloadJPGs(jpgs, './img/')
def main():
url = 'https://www.instagram.com/tee_jaruji/'
download(url)
if __name__ == '__main__':
main()
这个爬虫总共100行左右,一般是我后来加的注释,也就是说代码50行。
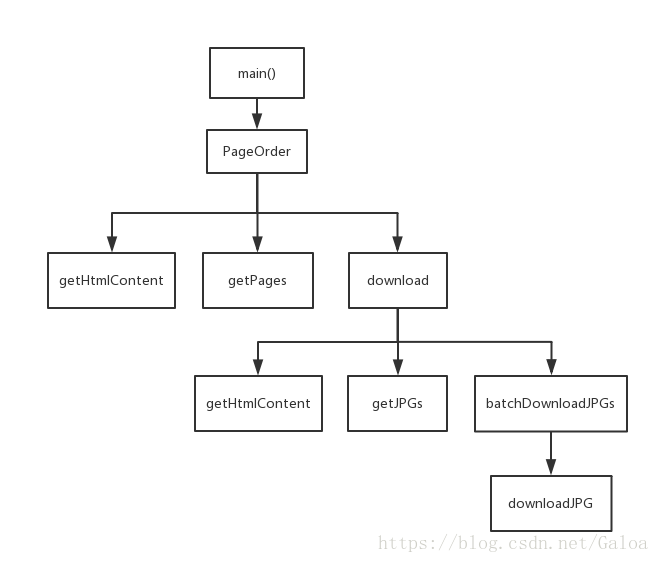
代码函数关系如下:
函数调用关系就像图里展示的,主函数调用PageOrder来获取某一帖子中所有页面的链接,getHtmlContent是由链接获取网页源码文本的函数,getPages是由首页正则匹配获取记录下一页链接并进入下一页如此递归获取所有页面链接的函数,download是由某一页面链接获取所有图片链接并下载的函数。
这份代码用到了三个库,request进行网页请求、接收和转码,re进行正则匹配,这两个包实现了爬虫功能,获取所有的下载链接,最后由contextlib中的closing包进行图片下载。
总结来说,对于有下一页链接的静态页面进行多级页面的爬取就是爬源码,正则匹配下一页链接,递归爬取所有链接,挨个进去爬所要内容即可。
这一部分我写的注释非常详细了,应该很好懂。
源码如下:GitHub下载:BaiduBarPicsCrawler .py
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取贴吧/图库图片
###################################################
import requests
import re
#####################################################################
# 根据url获取网页html内容
#####################################################################
def getHtmlContent(url):
page = requests.get(url) #页面get请求,获得网页对象
return page.text #返回网页源码
#####################################################################
#从html中解析出页数以及每页链接,以备后面一页页爬图
#正则表达式同下面图片URL解析
#####################################################################
def getPages(html,pages):
#<a href="/p/2256306796?pn=2">下一页</a> <a href="/p/2256306796?pn=10">下一页</a>
print('.')
pageReg = re.compile(r'<a href="(/p/.+?pn=.+?)">下一页</a>') #下一页链接关键字的正则表达式
list1 = re.findall(pageReg,html) #匹配出下一页链接
if len(list1)!=0:
pages.append(list1[0]) #当前页有下一页则将链接关键字存入pages list
url = 'https://tieba.baidu.com/'+ list1[0] #用下一页关键字拼接出下一页链接
html = getHtmlContent(url) #爬取下一页源码
getPages(html, pages) #以下一列源码递归爬取下一页链接关键字,直至最后一页
return pages #返回所有页面的链接关键字List
#####################################################################
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
#####################################################################
def getJPGs(html):
# 解析jpg图片url的正则
jpgReg = re.compile(r'<img.+?/sign=.+?/(.+?.jpg)" width') #网页中图片链接的关键字正则表达式
jpgs = re.findall(jpgReg, html) #正则匹配页面中所有图片链接的关键字
return jpgs #返回图片关键字list
#####################################################################
# 用图片url下载图片并保存成指定文件名
#####################################################################
def downloadJPG(imgUrl,fileName):
# 可自动关闭请求和响应的模块
from contextlib import closing
with closing(requests.get(imgUrl,stream = True)) as resp: #下载图片
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk) #下载写入图片
#####################################################################
# 批量下载图片,默认保存到当前目录下
#####################################################################
def batchDownloadJPGs(imgUrls,pp,path = './img/'):
# 用于给图片命名
count = 1
num = pp*100 + count #图片所在页数的计数器
for url in imgUrls:
url='http://imgsrc.baidu.com/forum/pic/item/'+url #图片下载链接关键字转化为完整链接
downloadJPG(url,''.join([path, '{0}.jpg'.format(num)])) #下载图片到指定文件夹
print('下载完成第{0}张图片'.format(count))
count = count + 1
num +=1
#####################################################################
# 封装:从百度贴吧网页下载图片
#####################################################################
def download(url,pp):
html = getHtmlContent(url) #获取url网页源码
jpgs = getJPGs(html) #获取当前网页所有图片下载链接关键字
batchDownloadJPGs(jpgs, pp,'./img/') #用图片关键字list下载当前页所有图片
#####################################################################
#从当前页递归获取所有下一页网页链接直至最后一页
#####################################################################
def PageOrder(html):
print('正在爬取数据,请耐心等待_(:зゝ∠)_')
html = getHtmlContent(html) #获取html链接页面的源码text
pages = ['/p/2256306796?pn=1', ] #建立所有分页面链接关键字的list,存第一页关键字
getPages(html, pages) #从第一页开始递归爬取所有页(下一页)关键字
cnt = 1 #计页数
for url in pages:
print('正在下载第%d页图片:'%cnt)
url = 'https://tieba.baidu.com/'+ url #将关键字拼接成网页链接
download(url,cnt) #爬取此页所有图片链接,转换为原图链接,并下载
cnt+=1
#####################################################################
#开始爬取某帖子所有页面所有图片
#####################################################################
def main():
url = 'https://tieba.baidu.com/p/2256306796?pn=1' #帖子首页链接
PageOrder(url) #按页爬图
if __name__ == '__main__':
main()
IG页面初始时只显示12张照片,屏幕一直往下滚动,会显示更多,直到显示出所有的照片和视频。在此过程中,该网页并没有重新加载。所以新显示出来的照片和视频是通过Ajax技术从服务器获取到的。
之前理解的爬虫一直是找HTML文件中的某些内容,并且根据某些规则不停地更新需要请求的网页列表,这样就不断的有新的HTML文件。
针对现在这种情况。会有两种解决方案。一种是在代码中模拟屏幕滚动,将所有内容都显示出来后,爬下整个HTML,从中找到照片和视频的url(或者边滚动边查找);另一种是直接去找XHR(XmlHttpRequest对象),其中肯定存有照片和视频的url信息。
关于python的文件流操作和下载操作,跟爬虫其实关系不大,我这里就略去不说了。
源码爬下来了彭于晏的2170张图和XX个视频。
另外这个IG的爬虫比贴吧的好用,贴吧的不同帖子之间资源的链接的编码格式是不同的,所以你要爬不同帖子的图就得跟举这个帖子,自己重新做一遍正则匹配。但是IG的Json包格式和资源链接格式是一致的,你要做的事只是换个首页地址就行,只有一点,太老的图,因为IG换了Json包的协议格式,你需要换个Json格式去解码,比如彭于晏的比第2170张更之前图估计就得换之前的Json格式去解码了。
源码如下:GitHub下载:InstagramPics&VidsCrawlerForPresentation.py
import os
import requests
import json
import re
from contextlib import closing
# 起个名字
user_name = 'Galo'
# HTTP请求中找的
user_id = 2158725
media_after = 'AQCN46TlLBVMhGaf7xrr_i4Jc4KaqbzH2IN_-EM0j-XbSjmYpByx_kpMPVHyoQV2t64sXopRP_zX0LMr83ufqr4rvKRksXp1IDRaSSpLptUEnw'
query_id = 1521636438
img_links = []
video_links = []
i = 1
j = 1
k = 1
headers = {
"Origin": "https://www.instagram.com/",
"Referer": "https://www.instagram.com/yuyanpeng/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36",
"Host": "www.instagram.com"}
# 先创建两个文件夹
if os.path.isdir(user_name + '_images'):
print('已有images文件夹')
else:
os.makedirs(user_name + '_images')
print('创建了images文件夹')
if os.path.isdir(user_name + '_videos'):
print('已有videos文件夹')
else:
os.makedirs(user_name + '_videos')
print('创建了videos文件夹')
# # 保存链接的函数,不要了,直接写在下边吧。
# # 这样一行行的写入,底下是直接报links列表组合一下,一起写
# def save_image_links(links):
# with open('images.txt', 'w') as f:
# for link in links:
# f.write(link + 'n')
# print('共保存了' + str(len(links)) + '张图片。')
# def save_video_links(links):
# with open('videos.txt', 'w') as f:
# for link in links:
# f.write(link + 'n')
# print('共保存了' + str(len(links)) + '个视频。')
def find_video_url(video_code):
# 通过node的code先生成查找视频的HTTP请求url
# 貌似video_code对了就行了,后边跟的查询字符不是必须的。爬梅西的视频时忘改了,但还是正确的爬下来了
query_video_url = 'https://www.instagram.com/p/'+ video_code +'/?taken-by=yuyanpeng'
# 发送请求,get方法
video_r = requests.get(query_video_url, headers=headers)
# 返回的数据仍是json格式的,与下边整体数据的加载类似
#返回不是json!!!!正则匹配下载链接
videoReg = re.compile(r'content="(https://scon.+?/vp/.+?.mp4)"')
videoSource = re.findall(videoReg,video_r.text)
# 视频的链接就在media下的video_url中
#video_json_data_media = video_json_data['media']
return videoSource[0]
res = requests.get('https://www.instagram.com/graphql/query/?query_hash=472f257a40c653c64c666ce877d59d2b&variables=%7B%22id%22%3A%222158725%22%2C%22first%22%3A12%2C%22after%22%3A%22AQBjhIn0c9Aukpi7CZcidt81XmdjGDeIQKkvGUhLErS0ne-Ds-TG5IjH__DKhtjH7E1xR1kqZwXGZ1xLdrftI7ciT43sbGj-VkN-hYYmWzO1Xw%22%7D', headers=headers)
dic =json.loads(res.text)
data = dic['data']['user']['edge_owner_to_timeline_media']['edges']
cnt = 0
nodes = []
while cnt<=len(data)-1:
nodes.append(data[int(cnt)]['node'])
cnt+=1
end_cursor = dic['data']['user']['edge_owner_to_timeline_media']['page_info']['end_cursor']
has_next_page = dic['data']['user']['edge_owner_to_timeline_media']['page_info']['has_next_page']
lee_id = nodes[0]["owner"]["id"] # '313386162'
for node in nodes:
if not node['is_video']:
link = node['display_url']
if link and link not in img_links:
print('找到了第' + str(i) + '张新的图。')
img_links.append(node['display_url'])
i = i + 1
else:
video_code = node['shortcode']
# 根据若是视频,根据node的code去生成视频链接的HTTP请求url
# 写成了函数find_video_url
video_link = find_video_url(video_code)
if video_link and video_link not in video_links:
print('找到了第' + str(j) + '个新的视频。')
video_links.append(video_link)
j = j + 1
print('加载')
# 查询的url,不同数据的查询并不是通过url的不同来体现
url = 'https://www.instagram.com/graphql/query/?query_hash=472f257a40c653c64c666ce877d59d2b&variables=%7B%22id%22%3A%222158725%22%2C%22first%22%3A12%2C%22after%22%3A%22AQBjhIn0c9Aukpi7CZcidt81XmdjGDeIQKkvGUhLErS0ne-Ds-TG5IjH__DKhtjH7E1xR1kqZwXGZ1xLdrftI7ciT43sbGj-VkN-hYYmWzO1Xw%22%7D'
# query_video_url = 'https://www.instagram.com/p/2KrdZNpIxk/?taken-by=yejinhand&__a=1'
# 通过form data 来进行不同数据的查询。不同在after后的一串数字。
#query_data = {
# 'q': 'ig_user(' + str(user_id) + '){media.after(' + media_after + ', 12){nodes{code,display_src,id,is_video},page_info}}',
# 'ref': 'users::show',
# 'query_id': str(query_id)
#}
# 首先读取文件中的video_links和img_links,加入上边两个List中
# 打开文件时 只读方式 r
# 不对,应该用r+,读写,若文件不存在,创建文件
with open(user_name + '_videos' + '/videos.txt', 'r+') as f:
for line in f.readlines():
video_links.append(line.strip('n'))
with open(user_name + '_images' + '/images.txt', 'r+') as f:
for line in f.readlines():
img_links.append(line.strip('n'))
# 已经有的视频、图像连接
print('已有' + str(len(video_links)) + '个视频链接。')
print('已有' + str(len(img_links)) + '个图片链接。')
#while True:
while i<=2170:
# 进行post请求。注意有个data项。即HTTP请求中的form data项。
r = requests.get(url,headers=headers)
# 返回的数据是json格式。用json库来解析。
dic = json.loads(r.text)
# dic现在就是一个字典,dict,有键有值。
data = dic['data']['user']['edge_owner_to_timeline_media']['edges']
cnt = 0
nodes = []
while cnt <= len(data)-1:
nodes.append(data[int(cnt)]['node'])
cnt += 1
end_cursor = dic['data']['user']['edge_owner_to_timeline_media']['page_info']['end_cursor']
has_next_page = dic['data']['user']['edge_owner_to_timeline_media']['page_info']['has_next_page']
# lee_id = nodes[0]["owner"]["id"] # '313386162'
for node in nodes:
if not node['is_video']:
link = node['display_url']
if link and link not in img_links:
print('找到了第' + str(i) + '张新的图。')
img_links.append(node['display_url'])
i = i + 1
else:
video_code = node['shortcode']
# 根据若是视频,根据node的code去生成视频链接的HTTP请求url
# 写成了函数find_video_url
video_link = find_video_url(video_code)
if video_link and video_link not in video_links:
print('找到了第' + str(j) + '个新的视频。')
video_links.append(video_link)
j = j + 1
# 有关下一页的信息在'json_data_media'中的page_info中
# json_data_page_info = json_data_media['page_info']
# 根据其中的has_next_page,可以判断有无下一页,更多的数据
if has_next_page:
# 下一页的HTTP请求url就是根据json_data_page_info中的end_cursor生成的
# end_cursor = json_data_page_info['end_cursor']
# new_q = 'ig_user(' + str(user_id) + '){media.after('+ end_cursor +', 12){nodes{code,display_src,id,is_video},page_info}}'
# 修改成为查询下一页
url = 'https://www.instagram.com/graphql/query/?query_hash=472f257a40c653c64c666ce877d59d2b&variables=%7B"id"%3A"2158725"%2C"first"%3A12%2C"after"%3A%22'+end_cursor+'%22%7D'
print('######又加载了一页######')
k = k + 1
else:
print('已经到头了。')
break
# save_image_links(img_links)
# save_video_links(video_links)
# 此时写入是用的w,不能用a+否则就重复了
# 怎样一些写入一个列表
with open(user_name + '_images' + '/images.txt', 'w') as f:
f.write('n'.join(img_links) + 'n')
with open(user_name + '_videos' + '/videos.txt', 'w') as f:
f.write('n'.join(video_links) + 'n')
def downloadJPG(imgUrl,fileName):
# 可自动关闭请求和响应的模块
with closing(requests.get(imgUrl,stream = True)) as resp:
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk)
def downloadVID(vidUrl,fileName):
# 可自动关闭请求和响应的模块
with closing(requests.get(vidUrl,stream = True)) as resp:
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk)
cnt = 1
for imgurl in img_links:
if imgurl != '':
downloadJPG(imgurl, ''.join(['./Galo_images/', '{0}.jpg'.format(cnt)]))
cnt+=1
cnt = 1
for vidurl in video_links:
if vidurl != '':
downloadVID(vidurl, ''.join(['./Galo_videos/', '{0}.MP4'.format(cnt)]))
cnt+=1
print('完成!')
print('共进行了' + str(k) + '次的查询。')
print('共新增了视频' + str(j - 1) + '个。')
print('共新增了图片' + str(i - 1) + '张。')
# print(video_links)
print('现在共有' + str(len(video_links)) + '个视频。')
# print(img_links)
print('现在共有' + str(len(img_links)) + '张图片。')
Python爬虫–爬取孙艺珍Instagram上的照片和视频
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!