社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
什么是文本挖掘 ?
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。
一、搭建语料库
语料库:要进行文本分析的所有文档的集合。
需要用到的模块:os、os.path、codecs、pandas
代码如下:
import os
import os.path
import codecs
import pandas
filePaths = []
for root, dirs, files in os.walk(
r"C:Userswww12Desktopdata2.1SogouC.miniSample"
):
#使用os.walk()方法遍历输出一个文件夹下的所有文件名
1.os.walk()方法:
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
语法:
walk()方法语法格式如下:os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]])
参数:
> top – 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。root 所指的是当前正在遍历的这个文件夹的本身的地址 dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件名(不包括子目录) topdown --可选,为 True,则优先遍历 top
目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top
文件夹中每一个子目录。onerror – 可选, 需要一个 callable 对象,当 walk 需要异常时,会调用。
followlinks – 可选, 如果为 True,则会遍历目录下的快捷方式(linux 下是 symbolic
link)实际所指的目录(默认关闭)。返回值:
该方法没有返回值。
#os.path.join()方法拼接文件名返回所有文件的路径,并储存在变量filePaths中
for name in files:
filePaths.append(os.path.join(root, name))
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
#codecs.open()方法打开每个文件,用文件的read()方法依次读取其中的文本,将所有文本内容依次储存到变量fileContenst中,然后close()方法关闭文件。
#创建数据框corpos,添加filePaths和fileContents两个变量作为数组
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents})
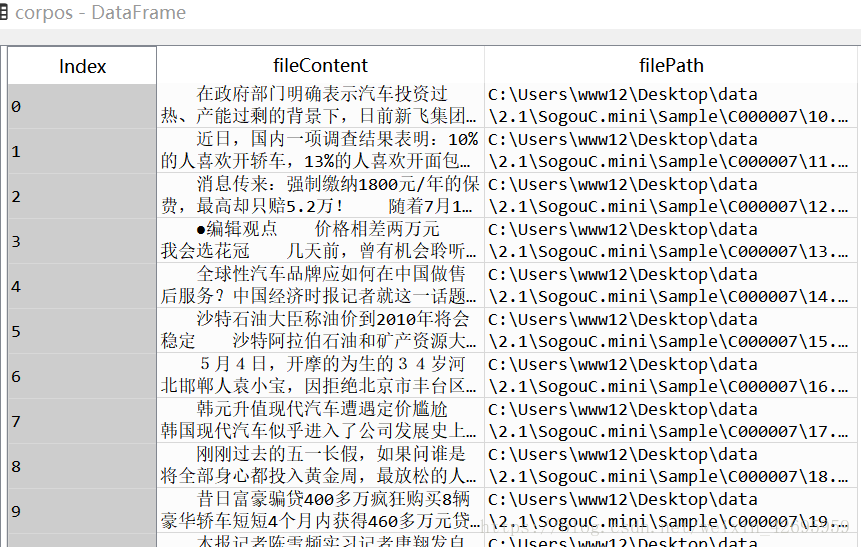
这个数据框就是我们要进行文本分析的语料库了。
如图:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!