社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
由于我们公司需要对各个业务的数据进行采集,所以我们需要搭建一个数据采集平台。原本的计划是使用大数据比较常见的双层flume+kafka的模型,但是我们公司的后端表示,不希望采用flume的方式采集,因为flume是需要跑在JVM上的,总体加起来可能需要好几百M,打成docker镜像比较麻烦(PS我们的某些业务才几十M),所以我们需要一个比较轻量的收集器。最终我们决定使用Filbeat。
1.首先我们有几百个应用,分布在不同的机器上,我们需要一个日志采集工具,并且我们是需要达成Docker镜像的,所以需要一个比较小的日志采集工具。
2.由于我们的应用比较多,所以如果所有的日志采集都直接连kafka的话,对kafka来说的压力太大,所以希望连接kafka的线程数尽量少。
3.由于公司比较穷,机器的配置不高,磁盘大小希望能节省使用(即不需要的数据就别传进kafka里)。
首先在选择日志采集工具时,我们最终决定使用轻量日志采集工具Filebeat,但是我们的应用非常多直接连接kafka压力非常大,所以我们在中间接了一层logstash用来减少连接kafka的线程数,并且在logstash层我们配置了两台logstash,用来容灾。在其中一台挂掉的情况下,短时间内不影响日志采集。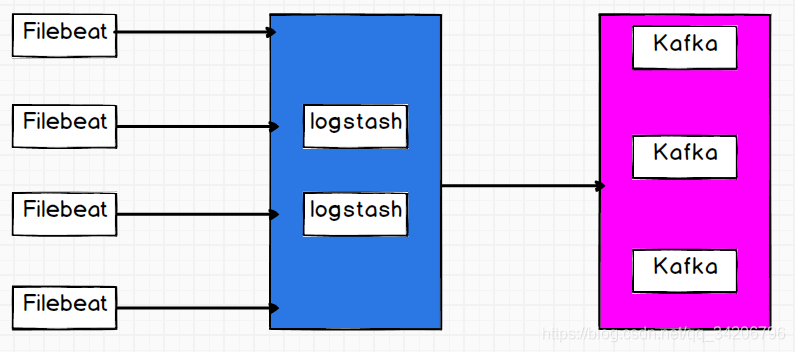
Filebeat是go语言写的,是一个轻量的日志采集工具,由于是二进制可执行文件,因此不需要JVM也能运行,实际占内存也就几十M,可以说非常符合我们的需求了,并且Filebeat出自Elastic,非常简单易用,仅仅通过配置就能完成绝大部分常见的需求,而且由于是Elastic家的和ELK的整合非常好(对自己家的应用适配度是相当的高,但是对其他的来说可能就没有那么方便了)。
虽然说FIlebeat比较简单易用,但是实际操作起来还是有很多坑在里面。比如Filebeat按照默认的情况会给我们的数据加上很多字段。长这样:
{"host":{"name":"hdfs1.nspt.cs"},"tags":["beats_input_codec_plain_applied"],"topic":"test_logstash","message":"456","input":{"type":"log"},"@timestamp":"2019-09-16T03:18:09.786Z","log":{"file":{"path":"/home/hadoop/ding/log.txt"},"offset":1560},"@version":"1","agent":{"version":"7.3.1","id":"844f5a8b-d896-4b62-9b1f-031bd5728c9d","hostname":"hdfs1.nspt.cs","ephemeral_id":"26afd21e-d680-4779-921b-ac26542e1cbd","type":"filebeat"},"ecs":{"version":"1.0.1"}}
实际上我们的数据只有message字段(也就是456)是我们采集过来的数据,其他的都是Filebeat给我添加的。最重要的是我在官网找了半天都没找到怎么配置输出字段,我看到一个官方论坛的帖子,好像是这个是配置不了的,你可以往里头添加,不能减。这样就不符合我们的需求3。当然我们还有其他的办法。
我们要使用Filebeat很简单,只需要一个配置文件即可。这里我直接给我写的配置文件:
#=========================== Filebeat inputs =============================
#配置输入
filebeat.inputs:
- type: log
paths:#这里可以配置多目录,支持*号,监控目录的多文件
- /home/hadoop/ding/log.txt
codec: 'plain'#解码方式
fields:#添加字段topic
topic: test_logstash
fields_under_root: true#没有这一句的话会添加fields:{topic:test_logstash}有这一句是topic:test_logstash
#================================ Outputs =====================================
#----------------------------- Logstash output --------------------------------
output.logstash:
#The Logstash hosts
hosts: ["192.168.5.243:5044","192.168.5.244:5044"]
loadbalance: true
codec: json#编码方式
#================================ Processors =====================================
#处理器,类似于logstash阉割版的过滤器
processors:
- drop_fields:#这里我们删除一部分不需要的字段,有些字段无法删除,例如时间戳和版本号,只能在logstash中处理了,尽量在这里处理,减少io
fields: ["ecs","agent","input","log.offset"]
这样我们的filebeat就配好了,接下来我们配置logstash。

Logstash对于使用ELK的同学来说是在熟悉不过了,这里有不过多介绍了。直接上配置文件。
input {#输入
beats {
port => 5044
}
}
filter {#过滤器,过滤掉filebeat无法过滤的字段。
mutate {
remove_field => ["@timestamp", "@version","tags"]
}
}
output {#输出到kafka
kafka {
bootstrap_servers => "192.168.5.242:9092,192.168.5.243:9092,192.168.5.244:9092"
acks => "all"
topic_id => "test_logstash"
codec => json#这里必须填json,否在logstash输出到kafka的格式。是不符合的。会输出message,时间戳,host。
}
}
这样Logstash就配置完毕了。去kafka看看数据是否正常进入kafka。
{"host":{"name":"hdfs1.nspt.cs"},"topic":"test_logstash","log":{"file":{"path":"/home/hadoop/ding/log.txt"}},"message":"456"}
{"host":{"name":"hdfs1.nspt.cs"},"topic":"test_logstash","log":{"file":{"path":"/home/hadoop/ding/log.txt"}},"message":"456"}
{"host":{"name":"hdfs1.nspt.cs"},"topic":"test_logstash","log":{"file":{"path":"/home/hadoop/ding/log.txt"}},"message":"456"}
{"host":{"name":"hdfs1.nspt.cs"},"topic":"test_logstash","log":{"file":{"path":"/home/hadoop/ding/log.txt"}},"message":"456"}
格式正确,这里我并没有把filebeat加入的字段都过滤,留下host和log路径作为后面报警提供的数据,这样我们就能很快的找到是哪个应用出现问题了。
这里我们把所有数据都写入kafka的一个主题里面,但我们的日志可能来源不同,也格式不同,所以放进一个主题里面还是不好的。而且我们在filebeat配置里面增加了一个字段topic。我希望logstash能和flume一样解析topic字段,然后动态写入kafka的主题里面。我在官网好像并没有查询到有关的配置,但是我在logstash官网高版本的logstash可以用java语言编写自定义输入输出和过滤器,我们可以通过自定义输出来完成这一步。期待后面的更新。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
