社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
import urllib.request
import random,re
print('''
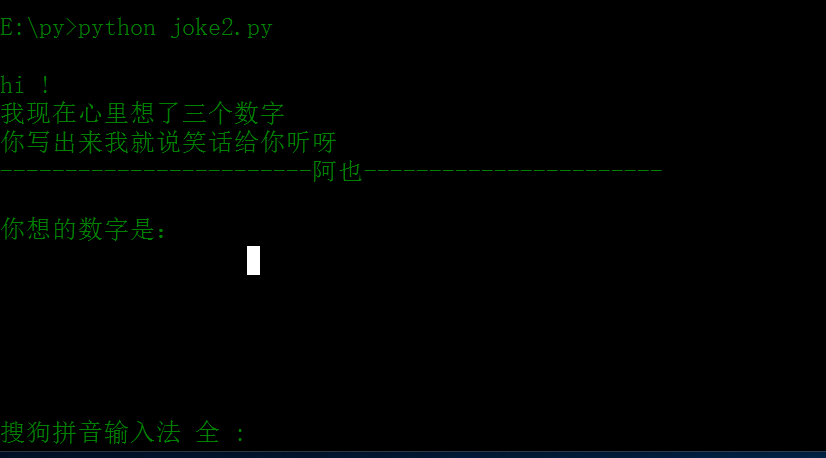
hi !
我现在心里想了三个数字
你写出来我就说笑话给你听呀
------------------------阿也-----------------------
''')
def speak():
lis = ['还能做朋友吗?','你真的在乎我?','这都猜不出来?','很难吗?','666','呵呵','你在开玩笑吗?','我已经绝望了','Are you kidding?','真笨','无敌笨','竟无语凝噎','你怕是找打哦']
print('------------------'+lis[random.randint(0,len(lis)-1)]+'------------------')
# speak()方法主要是用来打印对面输错我们心里所想的数字后的输出内容
count = 1
entry = input('你想的数字是:')
while entry != '520':
speak()
entry = input('你想的数字是:')
count = count+1
# 如果说对面一直不写520,那么就会一直要他继续写,并且打印spaek里面一些俏皮的话
if count == 1:
print('我也爱你')
elif count <= 5:
print('还行吧,才猜了%d次就猜出来了' %count)
else:
print('有点小失落,你居然猜了%d次才猜出来' %count)
# 这里主要就是统计一下用户一共猜了几次并且根据猜的次数输出不同的内容
print('------------------阿也----------------')
print('好吧,开始跟你讲笑话吧,希望你能喜欢!')
print('-----------------阿也-------------------')
urlbasic = 'http://www.haha365.com/joke/index_'
# 所需要爬取得网页的url前面一部分是不会变的,单独拿出来是基础url
entry2 = '1'
number = 0
# 这里while循环是保证用户只要输入的不是520那么就会给用户发送笑话
while entry2 != '520':
index = random.randint(1, 4005)
# 这里弄随机数为什么是4005,因为分析源码我们发现这个网页是4005页,
url = urlbasic+'%d.htm' %index
# 这里将得到的随机数加到基础url上形成完整的url用来爬取
req = urllib.request.Request(url)
res = urllib.request.urlopen(req)
html = res.read().decode('gbk')
# 这里decode('gbk')是因为查看网页源码发现是gbk编码的
#print(html)
titleRe = '<h3><A href=".*?">(.*?)</a></h3>'
textRe = '<div id="endtext">([sS]*?)</div>'
dateRe = '<div class="fl">s*<a href=".*?" class="catname">(.*?)</a> (.*?)</div>'
# 这里就是正则表达式去匹配,就是一些正则表达式的规则
title = re.findall(titleRe,html)
text = re.findall(textRe,html)
date = re.findall(dateRe,html)
# 这里就是re模块的使用,上一篇博客里面已经说过了,这里取到的都是list,
for i in range(len(title)):
textresult = re.sub(r'&.*?;',r'',text[i])
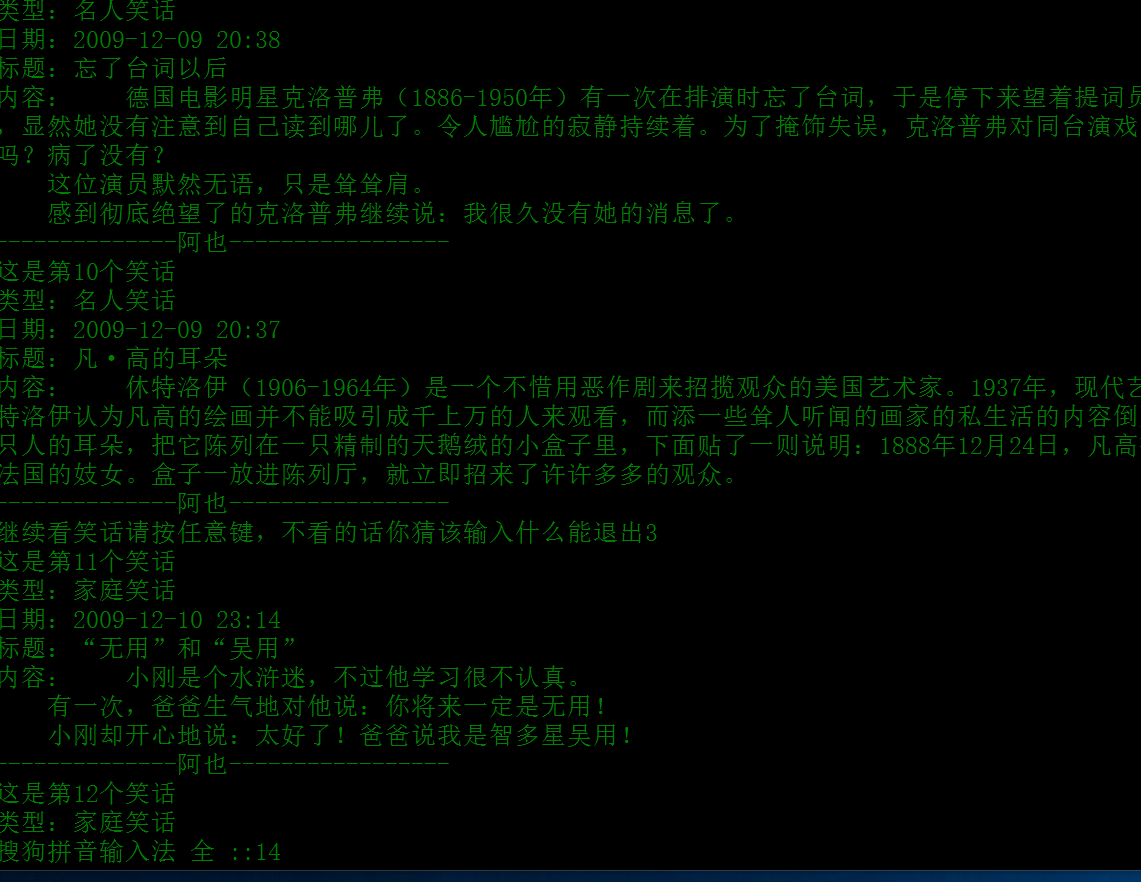
print('这是第%d个笑话'%(number+i+1))
# 这里就是输出说了多少笑话
print('类型:%s'%date[i][0])
print('日期:%s'%date[i][1])
print('标题:%s'%title[i])
print('内容:%s'%textresult.replace('<br />','').replace('<p>','').replace('</p>',''))
# 这里发现内容里面很多其他的<br />、之类的html代码,所以用replace替换为空
print('--------------阿也-----------------')
# 这里for循环是用来输出一个页面里面多个笑话的内容
number = number+len(title)
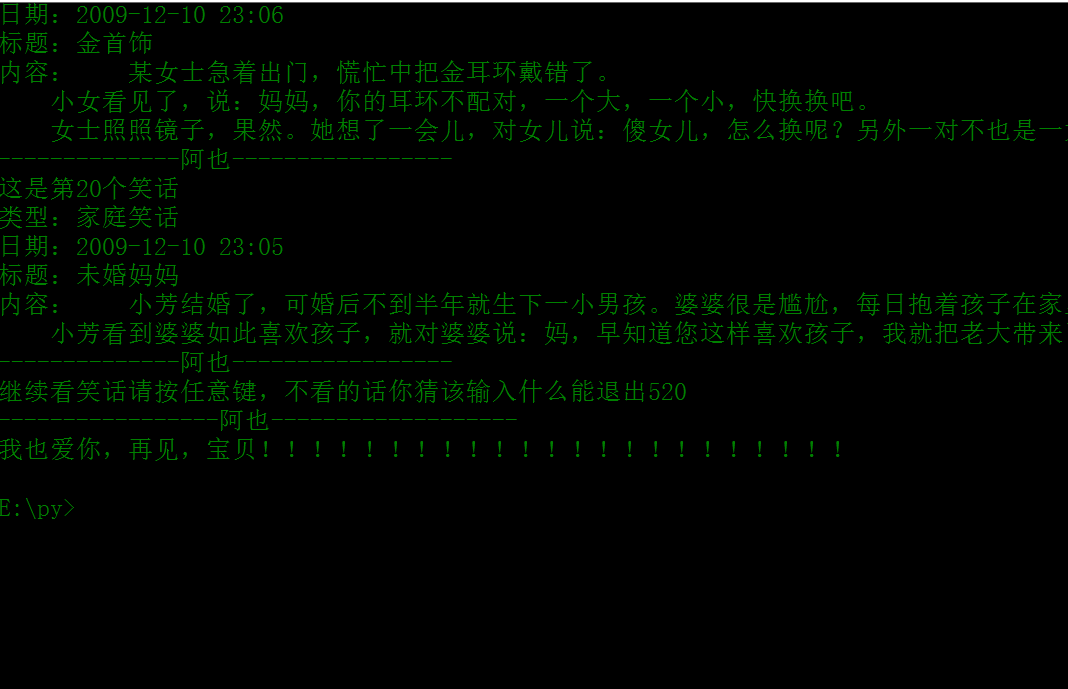
entry2 = input('继续看笑话请按任意键,不看的话你猜该输入什么能退出')
#
print('-----------------阿也-------------------')
print('我也爱你,再见,宝贝!!!!!!!!!!!!!!!!!!!!!!!')我们首先要找到这样一个笑话网站,我这里找到的是http://www.haha365.com/joke/index_7.htm这个网站,
这个网站有一个特点就是每次点下一页它url变化的仅仅只是后面的那个数字,我们要抓住这个特点。
爬虫嘛,当然首先是去分析这个页面的源代码
其实从网页源码里面可以发现:
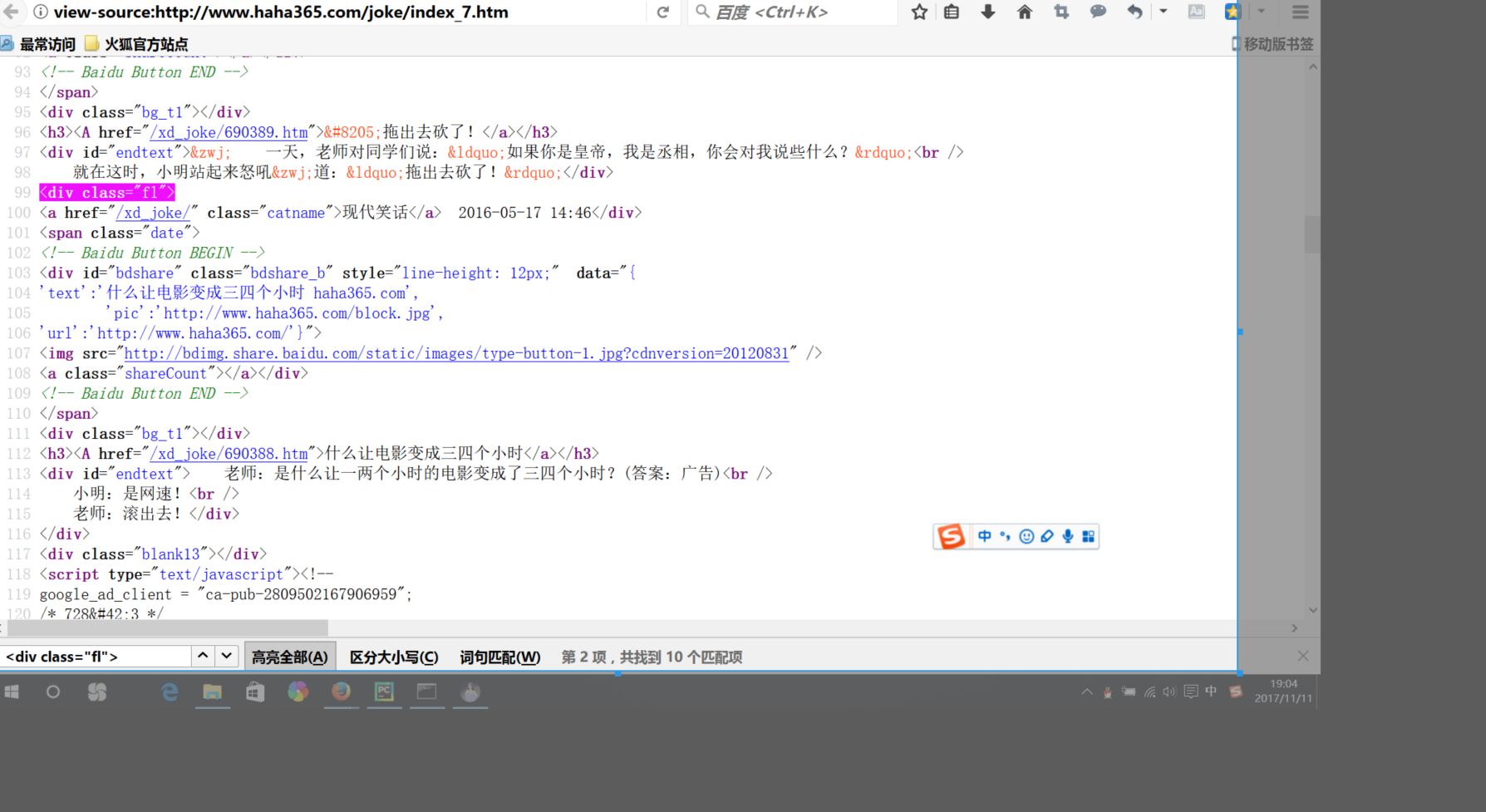
<h3><A href="/xd_joke/690388.htm">什么让电影变成三四个小时</a></h3>这个是标题
<div id="endtext"> 老师:是什么让一两个小时的电影变成了三四个小时?(答案:广告)<br /> 小明:是网速!<br /> 老师:滚出去!</div>这个是内容
<a href="/xd_joke/" class="catname">现代笑话</a> 2016-05-17 13:45</div>这个是类型和时间
ctrl+f搜一下网页源码,我们可以发现这些标签恰好都是对应的每一条笑话的,所以我们可以利用正则表达式去筛选出网页源码中的我们所需要的笑话内容标题时间等等。。在上面的代码中可以看见。
最后输出如下:
这里是刚运行的样子
===========================================================================
然后输入
======================================================================
不输入520就会一直让你输,直到输入520
============================================================================
一个网页的笑话输出完之后,就会问继续看笑话请按任意键,不按的话你猜该输入什么才能退出
==============================================================================
输入520后会退出
但是这样只能在你本地计算机上运行,你要想发给别人让别人去运行,那么就得将.py文件转为.exe文件
具体的转化方法请看我上一篇博客,http://blog.csdn.net/three_co/article/details/78503320
然后打包完成发给别人就可以了,但是要注意,pyinstaller 的时候不要加上-w了,因为这个是在命令行里面运行的,
你加上了-w后打包出来的exe文件就运行不了了。
以上,如有不足,请多指教。Thanks~!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!