社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前面在 python3爬虫系列20之反爬需要登录的网站三种处理方式中介绍的第三种方法,使用自动化测试工具selenium 库。
他的作用呢?
之前爬虫都是使用到了一些 python 的请求库,模拟浏览器的请求之类的,这些毕竟都是人工的,
而如果让爬虫自己去打开浏览器,自己去请求我们要爬取的网站,自己去模拟登录啊搜索啊等等。
就可以借我们的selenium 来自动化了。
本来呢,
selenium 一直使用在自动化测试岗位,很多搞测试的妹纸就会玩这个,支持各种主流的浏览器,有点类似按键精灵,可以直接运行在浏览器上。
而在python爬虫以后呢,有人就发现使用selenium可以更好的躺好,让他自己C网站,省时省力,赶紧学起来。
不多bb,本博客喜欢讲实战类,不喜欢讲原理类。
咱们学习了selenium,就让它来实现 selenium登录163,读取未读邮件内容。
有看过其他博客,大多数代码已经不可用了,因为163现在改版了。
这是最新版的。
目标地址:
首先分析了一下它的登录页面,一开始没有我们的输入账号密码的页面。
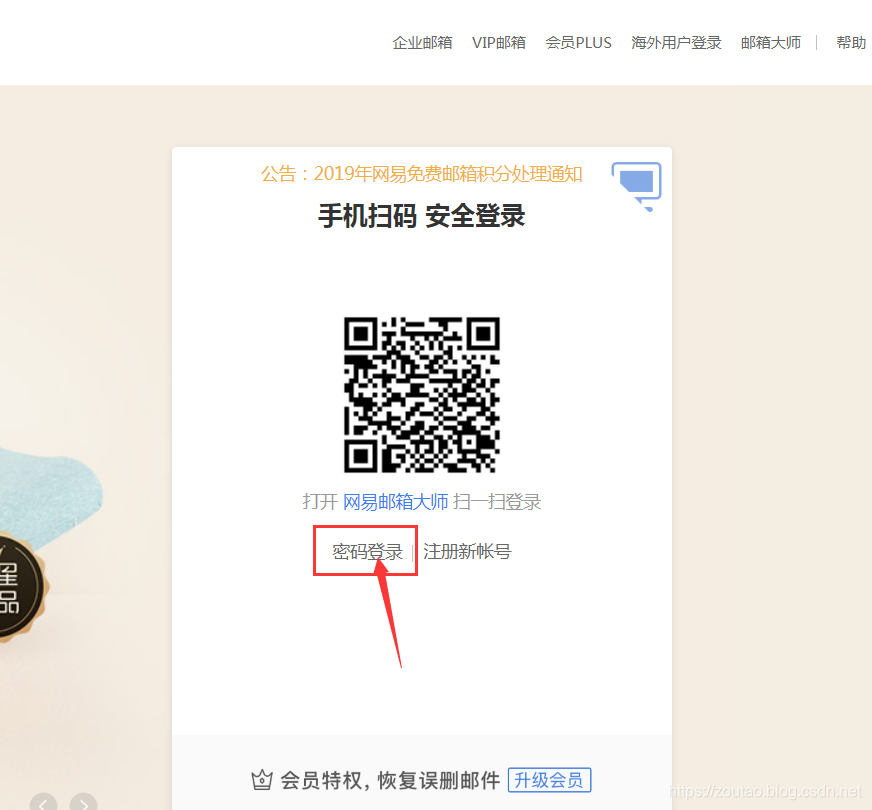
需要先点击一下调整到输入账号密码的页面去: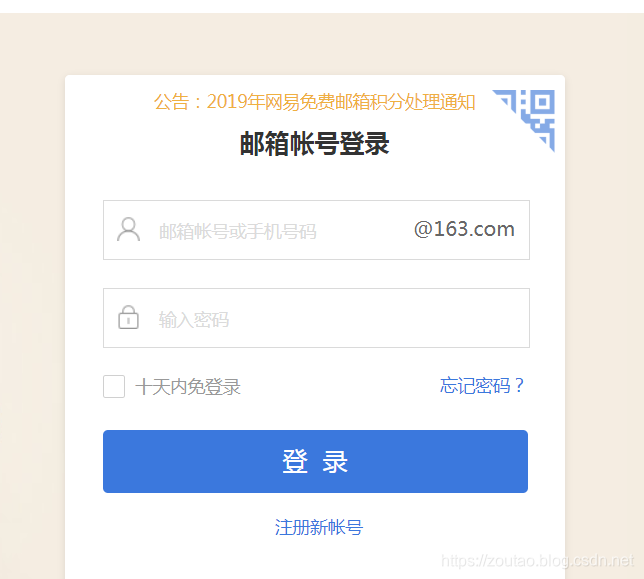
其次,打开审查元素,我们可以发现,输入账号和输入密码两个地方的input,id都是采用动态变化的,每次打开后缀都不一样:
所以我们要以唯一的标识,比如name,来找到邮箱的账号和密码输入框以及登录按钮。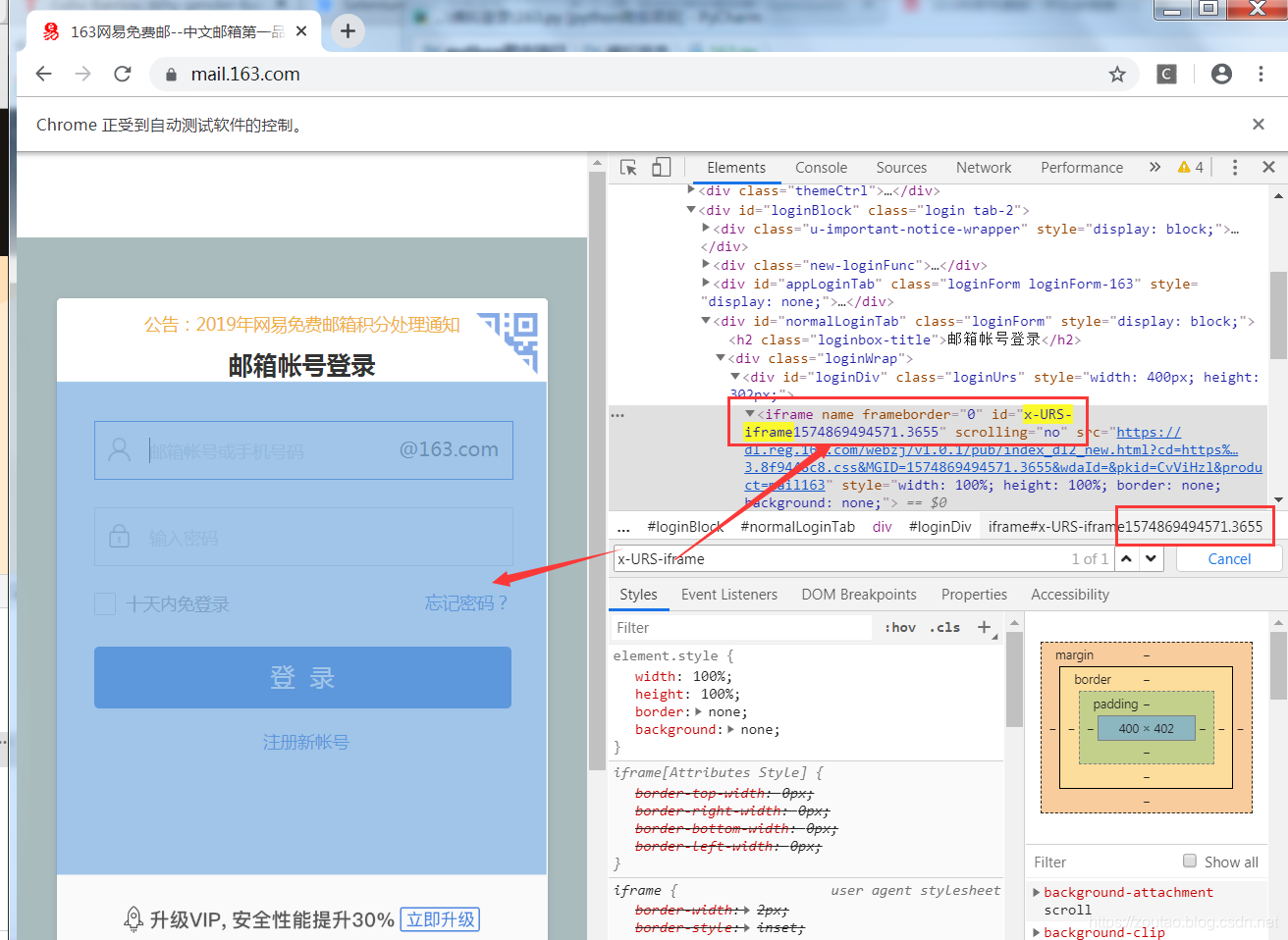
登录以后,也会发现未读栏:末尾的都是变化的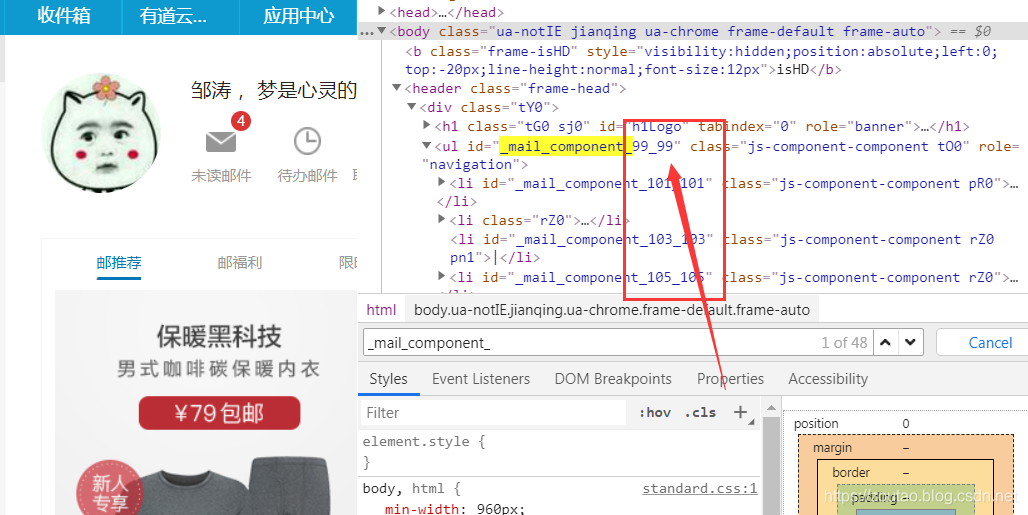
最后,发现我们的邮件内容页面,是嵌套在html中的iframe。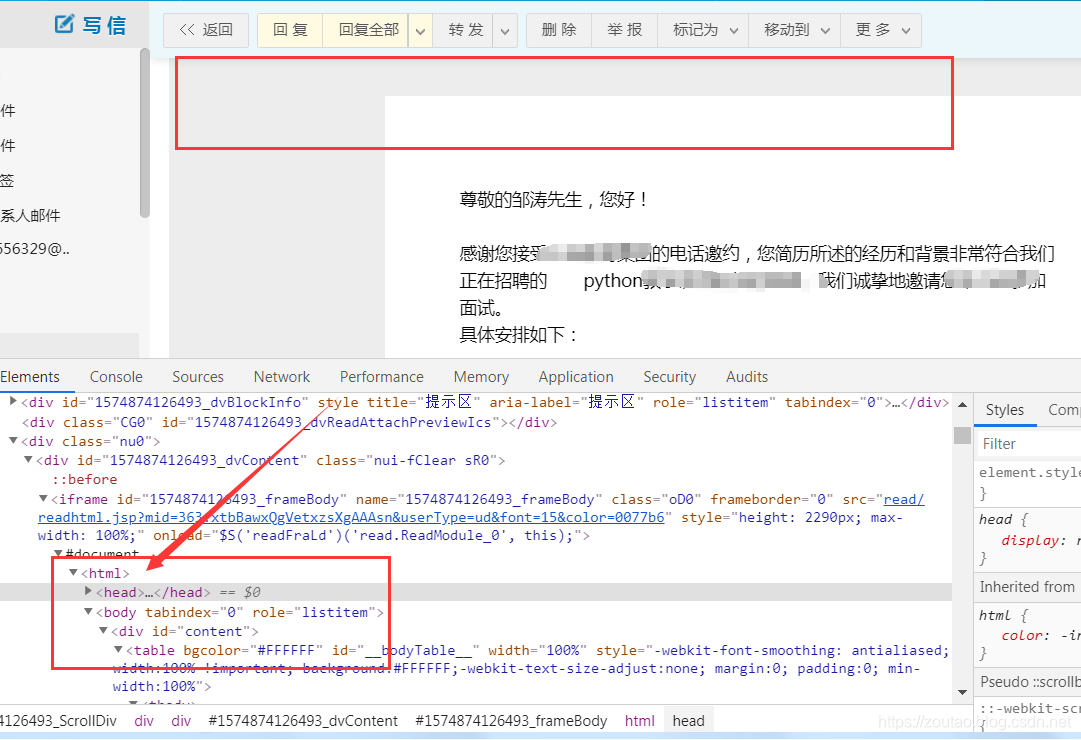
由 iframe表单嵌套,由于网页中iframe的id是动态的,所以不能用id寻找邮箱账号对应的iframe,所以这里用frame的index来定位,代码如下:
browser.switch_to.frame(0)
好了,问题基本上都分析完毕了。
接下来就是撸码阶段。
完整代码如下:
#!/usr/bin/python3
#@Readme : selenium登录163,读取未读邮件内容
import time
from fake_useragent import UserAgent
from selenium import webdriver
ua = UserAgent()
print(ua.random) # 随机产生
headers = {
'User-Agent': ua.random # 伪装
}
def auto_pc(url,username,password):
# selenium实例
browser = webdriver.Chrome() # 或填入chromedriver.exe的绝对路径
normal_window = browser.get(url)
time.sleep(5) # 加延迟,为了加载元素,避免太快出现异常
# //*[@id="switchAccountLogin"]
browser.find_element_by_id('switchAccountLogin').click() #点一下账号密码登录选项
# 切换到iframe表单,这是网易邮箱通用的一个框架-x-URS-iframe1574869494571.3655,
browser.switch_to.frame(0)
# 自动填入
browser.find_element_by_name("email").clear()
browser.find_element_by_name("email").send_keys(username)
browser.find_element_by_name("password").clear()
browser.find_element_by_name("password").send_keys(password)
browser.find_element_by_css_selector("#dologin").click() # 登录按钮
browser.implicitly_wait(10) # 隐式等待(作用:等待网页加载完成)
# 登录成功后获取cookie
cookie = browser.get_cookies()
# ----------------------查看是否登录成功---------------------
# 退出iframe,之前切换到iframe框架上,当进入网页后,需要退出iframe才能操作网页其他的元素
browser.switch_to.default_content()
# 简单判断登录是否成功
name = browser.find_element_by_id("spnUid").text
print(name)
if name == (username+'@163.com'):
print('登录成功')
read_email(browser)
else:
print('登录失败')
def read_email(browser):
# 读邮件
# class="gWel-mailInfo-ico"
browser.find_element_by_class_name('gWel-mailInfo-ico').click() # 点未读
time.sleep(2)
#class="tv0" 获取内容列表
readList = browser.find_elements_by_class_name('tv0')
print(type(readList))
for read in readList:
print(read.text) # 输出列表内容
# 邮件标题
readList2 = browser.find_element_by_class_name('rF0.kw0.nui-txt-flag0')
print('邮件标题:',readList2.text,type(readList))
readList2.click()
# 切换到iframe架构中
frame1 = browser.find_element_by_class_name('oD0')
browser.switch_to.frame(frame1) # 把iframe赋值给frame1,然后传递给方法
content=browser.find_element_by_class_name('FoxDiv20191010101211487871') # 这是某个未读邮件的class
print('邮件内容:',content.text)
# 回到上一层架构:(多表单时,进入一个表单要切回上一层架构,在切入到另一个表单中)
browser.switch_to.default_content()
time.sleep(2)
# --------------------退出登录,退出浏览器--------------------
browser.find_element_by_link_text('退出').click()
browser.close()
browser.quit()
if __name__ == '__main__':
url = 'https://mail.163.com/'
username ='xxxxxx' # 账号
password='xxxxxxxx' # 密码
auto_pc(url, username, password)
效果图:
登录以后,自动点击未读邮件选项:
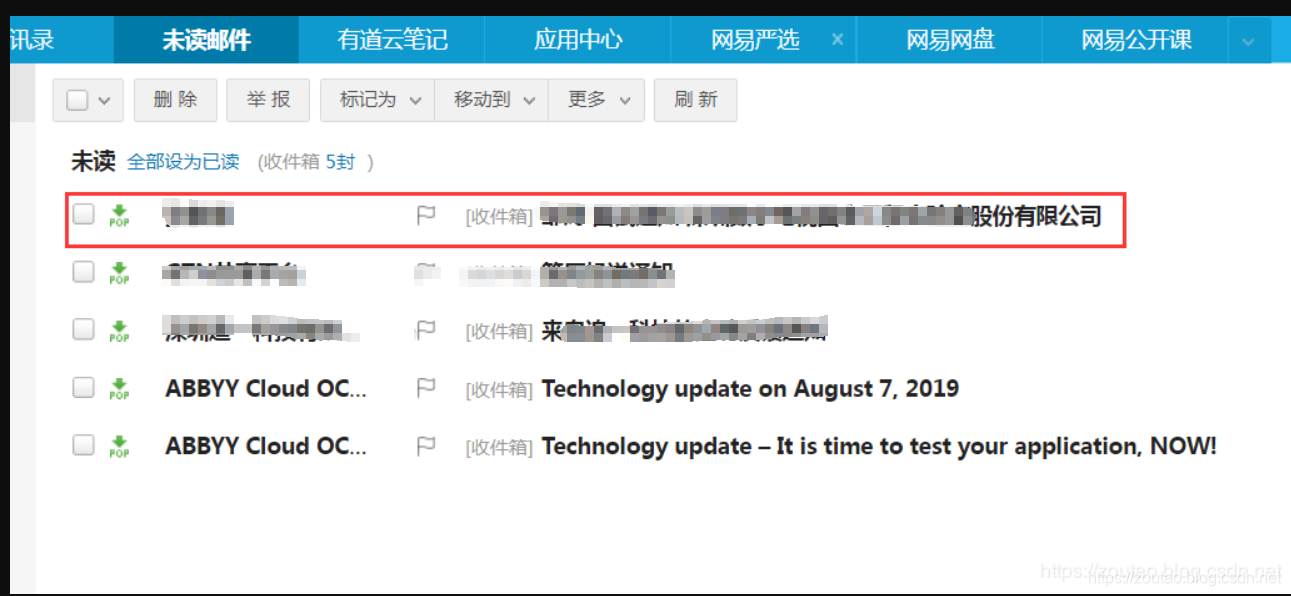
邮件内容: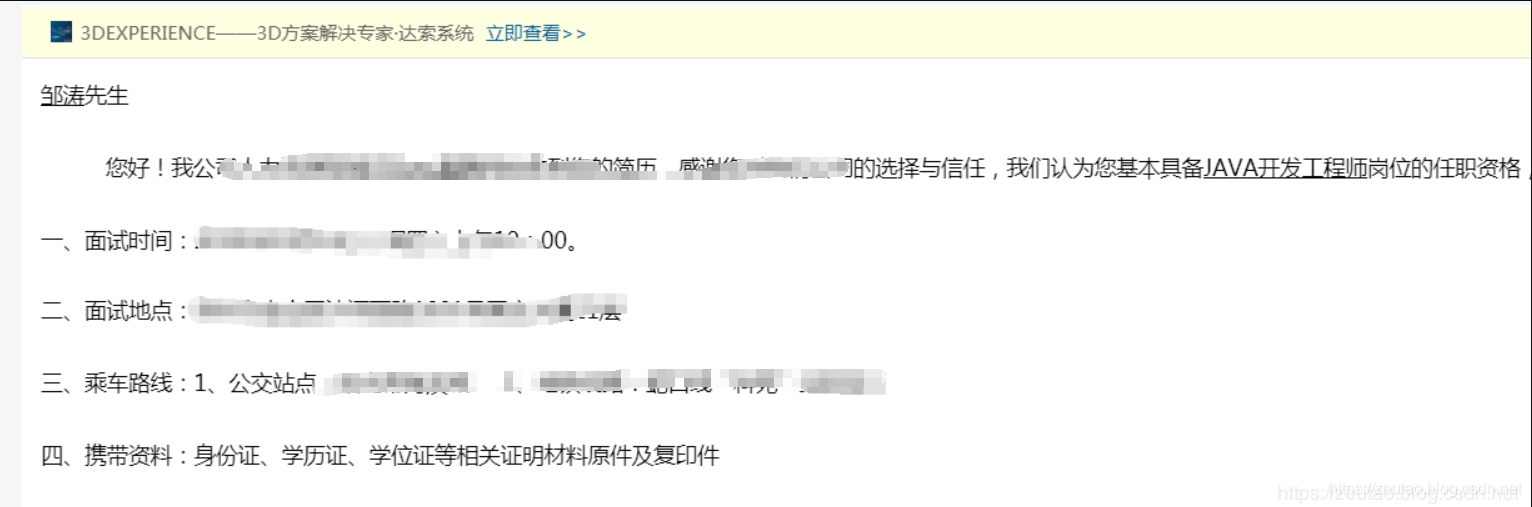
读取:
多时候,很多并列的元素如list表单,class都是共用同一个,如:elements方法可以返回的是一个list列表。
获取了一个 div,然后div的子元素获取:
browser.find_element_by_class_name('className').find_element_by_xpath('div')
如果我们知道想要定位的元素在页面中是第n个,则可以这样定位:
driver.find_elements_by_class_name("classname")[n] (注意:是elements,不是element)
需要注明的是,使用上述方法,即使这网页中样的元素只有一个,得到的依旧是一个list对象,只不过长度为1。
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。
说起无界面浏览器呢,有一个叫做 phantomjs 的玩意。
网上有很多selenium + phantomjs 达到完全模拟浏览器操作的案例。
如果你喜欢,更多用法可以参考文末地址。
但是呢本文不推荐它,为甚?
因为你使用phantomjs 的时候就会发现:
selenium已经放弃PhantomJS了,建议使用火狐或者谷歌无界面浏览器。
所以还是先 【弃用掉PhantomJS早点改用推荐的Headless Chrome比较好】
headless也是一款无界面无痕的浏览器。
chome59以上版本对应的Chromedriver可以支持headless模式。
这些放到以后再说吧,今天就先到这里了。
参考网站:
html元素定位中html中嵌有html怎么定位?https://blog.csdn.net/yinlin330/article/details/94566372
selenium + phantomjs 具体用法:https://www.cnblogs.com/miqi1992/p/8093958.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
