社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
import time
from multiprocessing import Pool
from tqdm import tqdm
import pandas as pd
import matplotlib.pyplot as plt
def run(i):
count=0
for j in range(100000):
count+=j*j
return count
def test(cpu_count):
main_start = time.time() #记录主进程开始的时间
with Pool(cpu_count) as p:
#results = p.map(self.run, range(params_list_len))
results = list(p.map(run, range(1000)))
main_end = time.time() #记录主进程结束时间
return main_end-main_start
cup_time_list=[]
for i in range(1,25):
print(i)
now_time=test(i)
cup_time_list.append([i,now_time])
cpu_time=pd.DataFrame(cup_time_list)
plt.plot(list(cpu_time[0]),list(cpu_time[1]))
plt.title("the relationship between the cup_num and computing time consume",color='red')
plt.show()
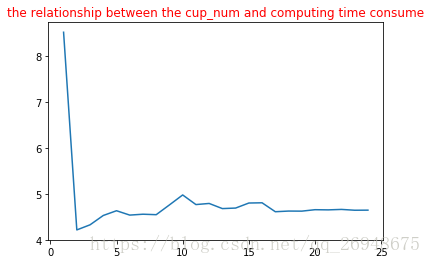
在本地的4核的ubuntu上运行的结果:
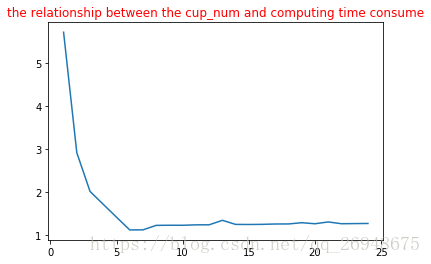
在服务器上,12核的运算结果如下:
非严谨结论:在4核的情况下,跑两个进程是最快的,在12核的情况下,跑6个进程是最快的。都是理论的进程数的一半,难道是因为这两台电脑真正的核数分别是2,和6,4和12是从真正核切割出来的?懵逼中
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!