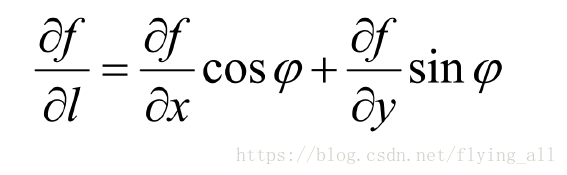社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
机器学习三个部分:编程能力+数学统计知识+业务知识
1 监督学习:例如分类、房价预测
2 无监督学习:例如聚类
3 强化学习:例如动态系统、机器人控制系统
| 是否连续 | 无监督 | 有监督 |
|---|---|---|
| 连续 | 聚类 && 降维 | 回归 |
| PCA | 线性回归/多项式回归 | |
| SVD | 决策树 | |
| K-means | 随机森林 | |
| 不连续 | 隐马尔科夫 | 分类 |
| 相关性分析 | KNN/Trees | |
| FP-Growth/Apriori | 逻辑回归/朴素贝叶斯/SVM |
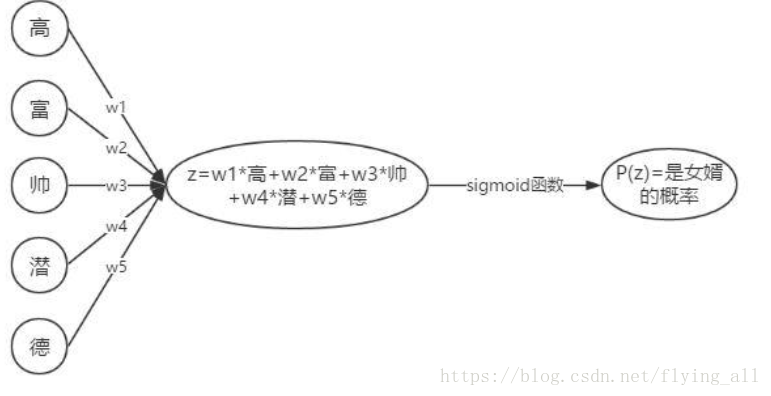
分析得到多个特征:高、富、帅、潜等;
观察多个数据得到每个数据的每个特征值;
设计得分函数;
设计损失函数;
损失函数最小化,求得特征权重;
根据得分函数,对新数据预测。
微积分用于求损失函数的最小值。
导数定义与意义:导数是曲线的斜率;二阶导数是斜率变化快慢的反应。
常用函数的导数
方向导数:是标量
梯度:是有方向的,是一个向量;是f函数对坐标轴求偏导得到的。
梯度的方向是函数在该点增长最快的方向。
在损失函数最小值计算中用到。
凸函数的定义:有
凸函数判定依据:,f(x)是凸的。
条件概率:
全概率公式:
贝叶斯公式:
概率:已知总体,已知概率分布参数,求某种情况发生的概率。已知总体,求抽样(某事件)发生的概率。
数理统计:已知总体分布,但不知道具体参数,从抽样数据中推出总体参数。
在有监督的机器学习中,已知数据,求得权重的过程是数理统计的过程:从样本推出总体参数;这是机器学习的训练过程。
在有监督的机器学习中,已知数据和权重,求得标签的过程是概率:已知总体,求抽样发生的概率;这是机器学习的预测过程。
观察已有数据的标签分布、每个特征的分布;评估了分布后,大致可以得到某些特征和标签的相关性较强,某些特征和标签的相关性较弱。
统计估计的是分布,机器学习训练出来的是模型。模型可能包含了多个分布。
模型是有误差的。误差本身可以是概率的形式。
期望
方差
协方差:可以评价特征与标签的相关性;用于特征选择
相关系数
A.x的含义
SVD的几何意义
矩阵乘法
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!