社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
代码中soup.select(),不明白的地方,我后续将详细解释,爬出来是空列表的情况。
import requests
from bs4 import BeautifulSoup
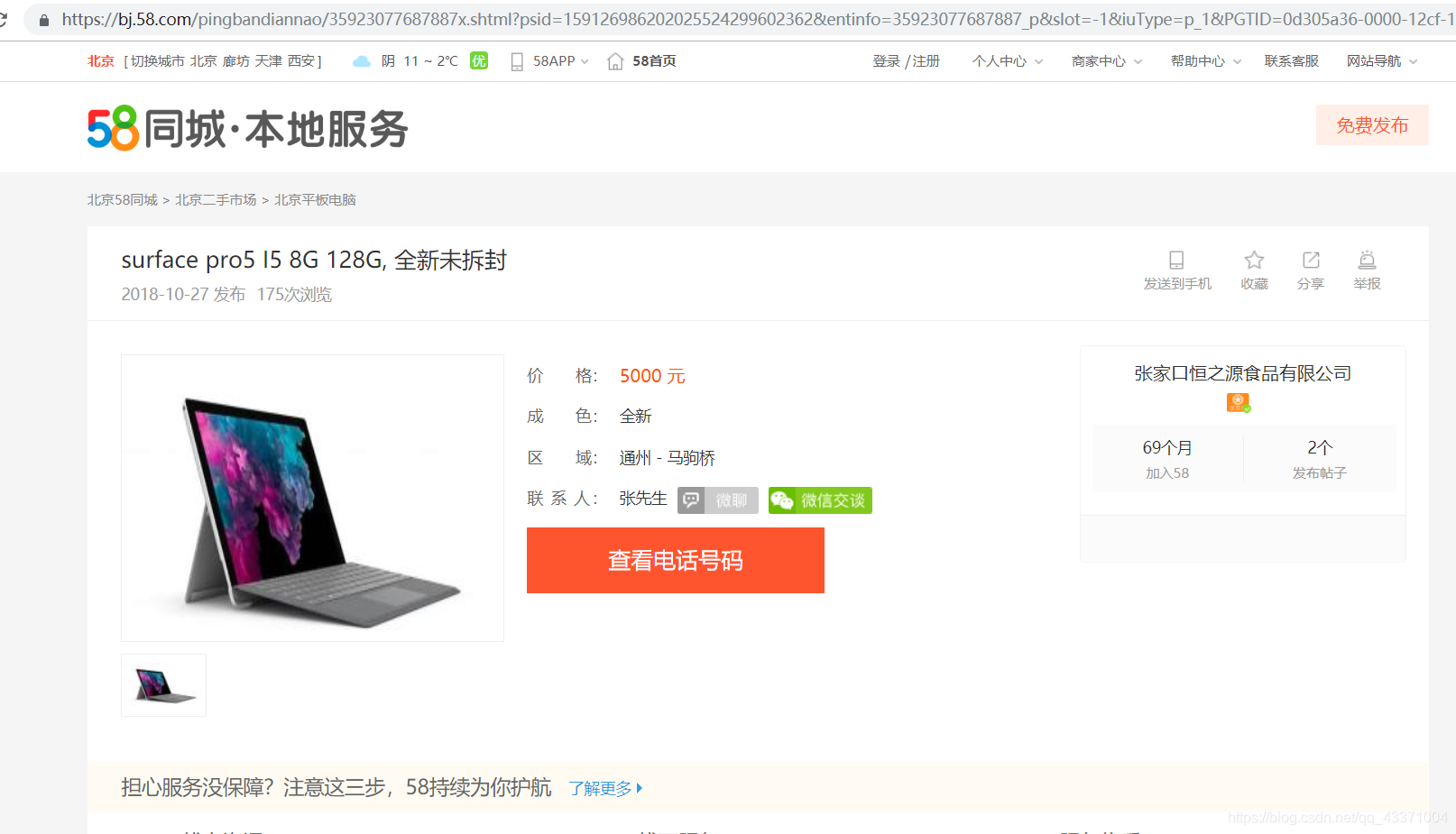
URL = 'https://bj.58.com/pingbandiannao/35923077687887x.shtml?psid=157596847202024134799949907&entinfo=35923077687887_p&slot=-1&iuType=p_1&PGTID=0d305a36-0000-19ea-0c77-0ae8025ace4f&ClickID=2'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' }
wb_data = requests.get(URL,headers=headers)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
NameList = soup.select('h1.detail-title__name')
ProductName = NameList[0].text.strip()
PriceList = soup.select('span.infocard__container__item__main__text--price')
ProductPrice = PriceList[0].text.strip()
ViewList = soup.select('div.infocard__container__item__main')
ProductView = ViewList[1].text
AreaList = soup.select('div.infocard__container__item__main > a')
ProductArea = AreaList[0].text+'-'+AreaList[1].text
SellerNameList = soup.select('div.infocard__container__item__main > a')
SellerName = SellerNameList[2].text
CatalogueList = soup.select('div.nav > a')
Catalogue = CatalogueList[-1].text
data_dict = {
'产品类别': Catalogue,
'产品名称': ProductName,
'产品价格': ProductPrice,
'产品成色': ProductView,
'产品区域': ProductArea,
'卖家姓名': SellerName
}
print(data_dict)
注意headers需要修改成自己电脑的,详见我的博客【python爬虫–招聘信息】->headers错误信息,如果不写headers会被反爬取。
{'产品类别': '北京平板电脑', '产品名称': 'surface pro5 I5 8G 128G, 全新未拆封', '产品价格': '5000 元', '产品成色': '全新', '产品区域': '通州-马驹桥', '卖家姓名': '张先生'}
url = ‘https://bj.58.com/pingbandiannao/?PGTID=0d409654-017a-3436-09be-f01fa1e2217f&ClickID=13’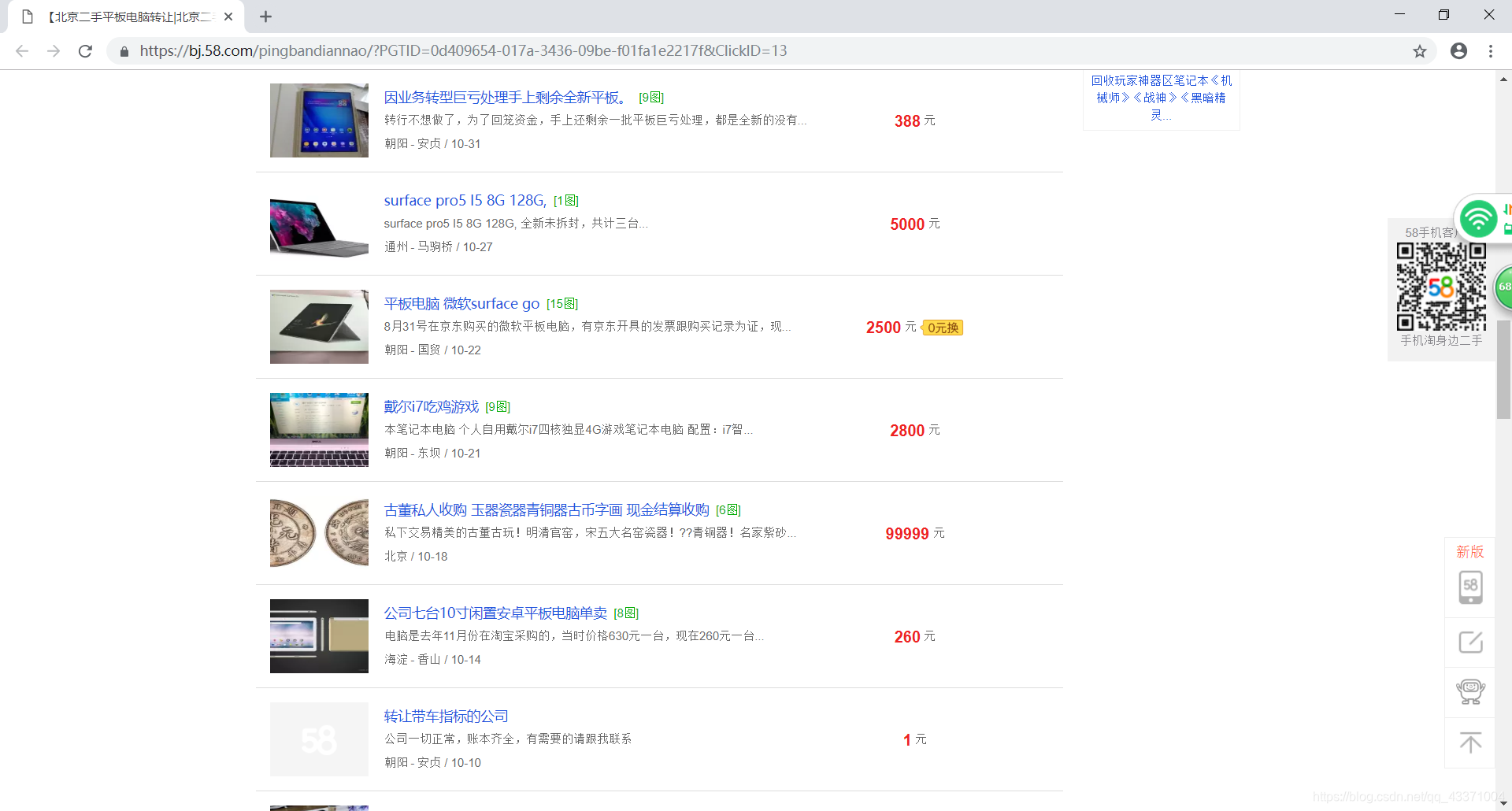
import requests
from bs4 import BeautifulSoup
#得到每个的详细信息
def get_info(URL):
#URL = 'https://bj.58.com/pingbandiannao/35923077687887x.shtml?psid=157596847202024134799949907&entinfo=35923077687887_p&slot=-1&iuType=p_1&PGTID=0d305a36-0000-19ea-0c77-0ae8025ace4f&ClickID=2'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' }
try:
wb_data = requests.get(URL,headers=headers)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
NameList = soup.select('h1.detail-title__name')
ProductName = NameList[0].text.strip()
PriceList = soup.select('span.infocard__container__item__main__text--price')
ProductPrice = PriceList[0].text.strip()
AreaList = soup.select('div.infocard__container__item__main > a')
ProductArea = AreaList[0].text.strip()+'-'+AreaList[1].text.strip()
SellerNameList = soup.select('div.infocard__container__item__main > a')
SellerName = SellerNameList[2].text
CatalogueList = soup.select('div.nav > a')
Catalogue = CatalogueList[-1].text
data_dict = {
'产品类别': Catalogue,
'产品名称': ProductName,
'产品价格': ProductPrice,
'产品区域': ProductArea,
'卖家姓名': SellerName
}
print(data_dict)
except:
print('此项信息被修改,所以爬取错误') #不想看到这句话,可以写pass
#get_info()
'''
下面是得到一整页中每个卖家信息的链接,这里只爬取了第一页中的全部信息,
也可以爬取好多页。只需要将下方的url中根据每页信息的不同变化相应的数字页码。
'''
def get_all_info():
url = 'https://bj.58.com/pingbandiannao/?PGTID=0d409654-017a-3436-09be-f01fa1e2217f&ClickID=13'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' }
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text, 'lxml')
GetLink = soup.select('td.t > a')
#print(GetLink)
for i in GetLink:
link = i.get('href') #得到href链接
#删选是平板电脑的链接
if 'pingbandiannao' in link:
get_info(link)
get_all_info()
{'产品类别': '北京平板电脑', '产品名称': '上门回收IPAD平板电脑 IPHONE全系列', '产品价格': '4999 元', '产品区域': '北京-邢先生', '卖家姓名': ''}
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': '展柜展示柜钛合金展柜精品展柜珠宝玉器展柜化妆品展柜', '产品价格': '面议', '产品区域': '东城-东城周边', '卖家姓名': '徐经理'}
{'产品类别': '北京平板电脑', '产品名称': '联想Yogabook Android 128G 雅黑色', '产品价格': '2000 元', '产品区域': '朝阳-望京', '卖家姓名': '胡先生'}
此项信息被修改,所以爬取错误
此项信息被修改,所以爬取错误
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': '戴尔i7吃鸡游戏', '产品价格': '2800 元', '产品区域': '朝阳-东坝', '卖家姓名': 's***0'}
{'产品类别': '北京平板电脑', '产品名称': '古董私人收购 玉器瓷器青铜器古币字画 现金结算收购', '产品价格': '99999 元', '产品区域': '北京-陈枫', '卖家姓名': ''}
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': '转让带车指标的公司', '产品价格': '1 元', '产品区域': '朝阳-安贞', '卖家姓名': '郭先生'}
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': '华为荣耀畅玩二平板电脑', '产品价格': '650 元', '产品区域': '石景山-金顶街', '卖家姓名': 'z***3'}
{'产品类别': '北京平板电脑', '产品名称': 'Lenovo/联想 Miix5 I5 转卖~', '产品价格': '4396 元', '产品区域': '石景山-衙门口', '卖家姓名': 'l***8'}
{'产品类别': '北京平板电脑', '产品名称': '九成新转让平板电脑', '产品价格': '1600 元', '产品区域': '昌平-沙河', '卖家姓名': 'm***t'}
{'产品类别': '北京平板电脑', '产品名称': '公司发的福利,一共两台,出售一台', '产品价格': '1200 元', '产品区域': '丰台-蒲黄榆', '卖家姓名': 'e***6'}
{'产品类别': '北京平板电脑', '产品名称': '全新未拆封微软Surface Por电脑', '产品价格': '6000 元', '产品区域': '朝阳-大屯', '卖家姓名': 'q***8'}
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': '三星TAB3 16G 8.1寸', '产品价格': '500 元', '产品区域': '大兴-观音寺', '卖家姓名': 's***5'}
{'产品类别': '北京平板电脑', '产品名称': '小米平板便宜出需要的联系我', '产品价格': '500 元', '产品区域': '顺义-李桥', '卖家姓名': 'f***6'}
{'产品类别': '北京平板电脑', '产品名称': '电影孩子学习有帮助', '产品价格': '1499 元', '产品区域': '房山-阎村', '卖家姓名': 'h***r'}
此项信息被修改,所以爬取错误
{'产品类别': '北京平板电脑', '产品名称': 'surfacePro4全新基本未用', '产品价格': '4300 元', '产品区域': '丰台-丽泽桥', '卖家姓名': '1***h'}
{'产品类别': '北京平板电脑', '产品名称': '个人全新Ipad Pro转让', '产品价格': '3666 元', '产品区域': '丰台-马家堡', '卖家姓名': 'o***4'}
{'产品类别': '北京平板电脑', '产品名称': '华为P20亮黑色', '产品价格': '3300 元', '产品区域': '朝阳-大山子', '卖家姓名': 'n***9'}
{'产品类别': '北京平板电脑', '产品名称': '处理老台式显示器', '产品价格': '150 元', '产品区域': '朝阳-甘露园', '卖家姓名': 'x***3'}
{'产品类别': '北京平板电脑', '产品名称': '转全新国行未拆封ipad一台', '产品价格': '2150 元', '产品区域': '朝阳-北苑', '卖家姓名': '小***滔'}
{'产品类别': '北京平板电脑', '产品名称': '自用ipad air2 wifi版', '产品价格': '1800 元', '产品区域': '海淀-马连洼', '卖家姓名': '1***o'}
{'产品类别': '北京平板电脑', '产品名称': '海尔品牌一体电脑', '产品价格': '260 元', '产品区域': '昌平-城北', '卖家姓名': 'z***1'}
Process finished with exit code 0
图片比较:
这里的标签被网页改了,所以以前的代码会报错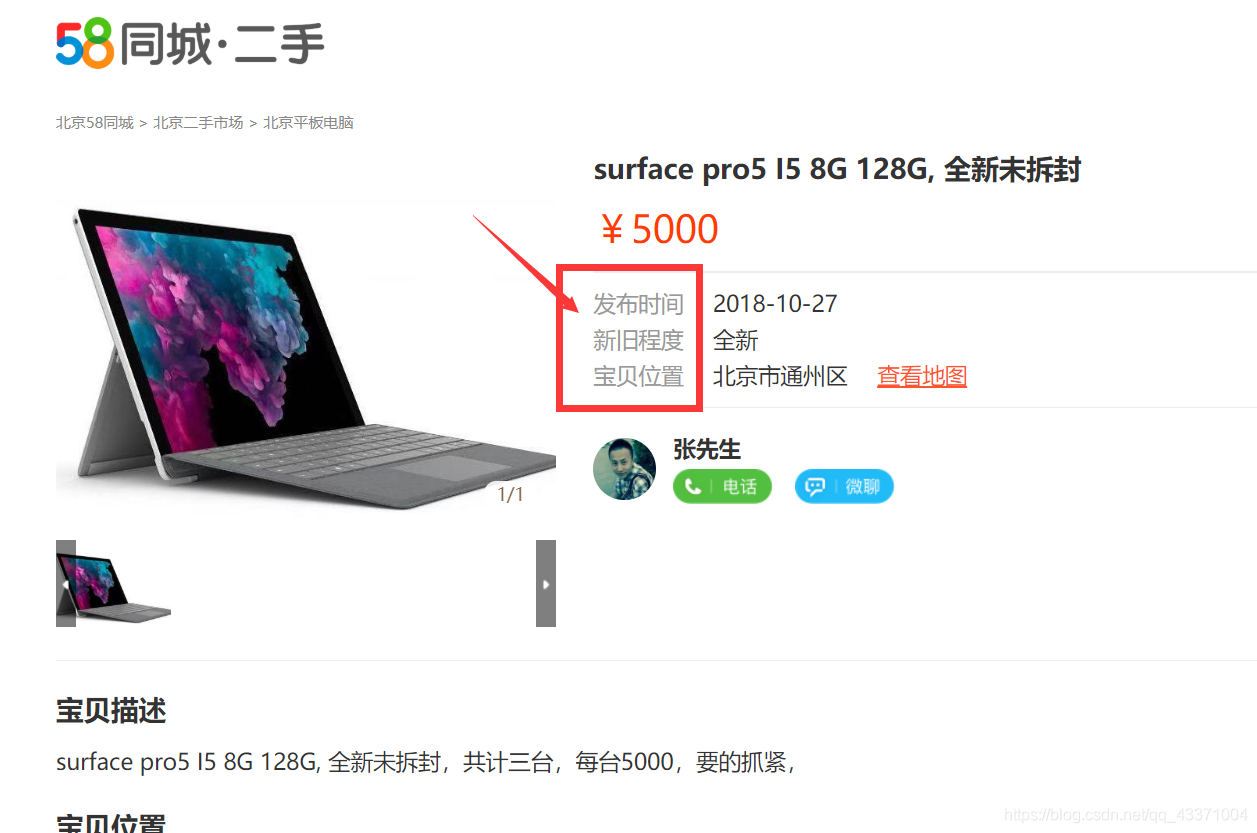
------------------------------------------------------------------------------------
谢谢支持,亲测运行成功。注意更改headers,(好像不修改也可以用)!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!