社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前面两篇文章讲了单页面如何爬取,那么我们来试试如何爬取二级页面。
在爬取页面的时候,需要有个良好的习惯,提前对爬取的页面和爬取思路进行一个分析。
目的:爬取携程无忧数据分析师的二级页面,获取每个岗位的要求。
页面的构成:二级页面是点击一级页面跳转的。
解决思路:
1、在一级页面中获取二级页面的链接
2、在二级二面中获取想要的数据。
这里我们会用到BeautifulSoup。
思路有了,那我们开始吧!
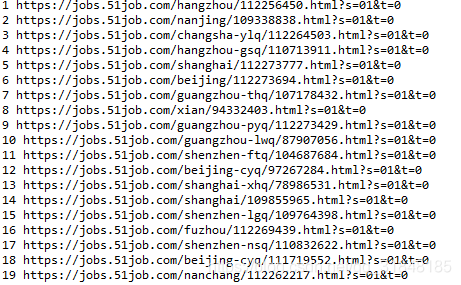
1、获取二级页面的链接,href路径获取,浏览器点开检查。找到相对应的href位置:
import requests
from bs4 import BeautifulSoup
from lxml import etree
import time
import csv
headers={
'user-agent':'Mozilla/5.0'
}#模拟浏览器进行爬取
url = 'https://search.51job.com/list/000000%252C00,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,'
#网页内容格式调整
i = 0
for n in range(1,10):
r = url+str(n)+str('.html')
html = requests.get(r,headers=headers)
html.raise_for_status()
html.encoding = html.apparent_encoding#内容获取的内容进行转码,以防出现乱码的情况。
soup = BeautifulSoup(html.text,'html.parser')
liebiao = soup.find_all('p','t1')#获取第一页href相关的位置
#print(liebiao)
for item in liebiao:
shuju = item.find('span')
link = shuju.find('a')['href']提取出href.
id = i+1 #写了一个自增长。方便自己查看当前数据是第几条。
i = id
print(id,link)
time.sleep(1)
好了,代码写好了,让我们来试试结果吧!
这里截取了部分数据,大家可以尝试一下,要是对路径获取不清楚的地方,可以去看一下我前面两篇文章。
2.获得了二级页面的连接,我们来通过这些链接抓取二级页面的数据吧!
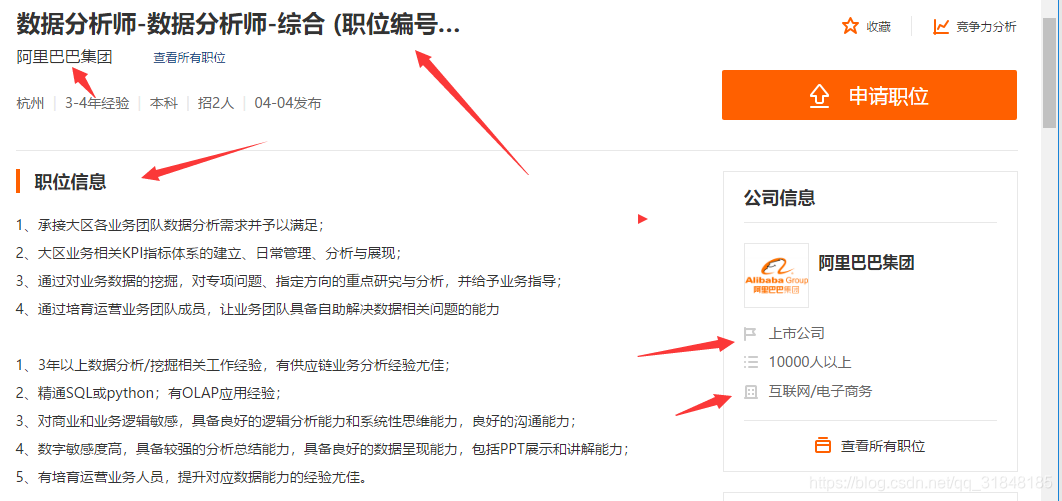
先确认一下,我们要抓取哪些信息:
我们再把xpath获取内容的方法再回顾一遍,这里也可以用前面使用的新方法,全看个人喜好恩。
我们来看看获取二级页面内容的代码:
date_html=requests.get(link,headers=headers).text
f = etree.HTML(date_html)
Date = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/@title')
print(Date)
name = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@title')
print(name)
money = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()')
print(money)
content = f.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()')
print(content)
business = f.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[1]/@title')
print(business)
address = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[1]')
print(address)
profession = f.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]')
for liebiao2 in profession:
profession2 = liebiao2.xpath('./p[3]/a/text()')
print(profession2)
数据路径有相关的规律,大家可以调整一下,参考我的二篇文章。
完整代码结合起来看看:
import requests
from bs4 import BeautifulSoup
from lxml import etree
import time
import csv
fp = open('C:/Users/MIiNA/Desktop/Date.csv','wt',newline='',encoding='utf_8_sig')
#fp = open('C:/Users/JX/Desktop/Date.csv','wt',newline='',encoding='utf_8_sig')
writer = csv.writer(fp)
headers={
'user-agent':'Mozilla/5.0'
}
url = 'https://search.51job.com/list/000000%252C00,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,'
#网页内容格式调整
i = 0
for n in range(1,10):
r = url+str(n)+str('.html')
html = requests.get(r,headers=headers)
html.raise_for_status()
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text,'html.parser')
liebiao = soup.find_all('p','t1')
for item in liebiao:
shuju = item.find('span')
link = shuju.find('a')['href']
id = i+1
i = id
# print(id,link)
print(id)
time.sleep(1)
date_html=requests.get(link,headers=headers).text
f = etree.HTML(date_html)
Date = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/@title')
print(Date)
name = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@title')
print(name)
money = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()')
print(money)
content = f.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()')
print(content)
business = f.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[1]/@title')
print(business)
address = f.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[1]')
print(address)
profession = f.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]')
for liebiao2 in profession:
profession2 = liebiao2.xpath('./p[3]/a/text()')
print(profession2)
writer.writerow((id,Date,name,money,content,business,profession2,address))
time.sleep(1)
fp.close()
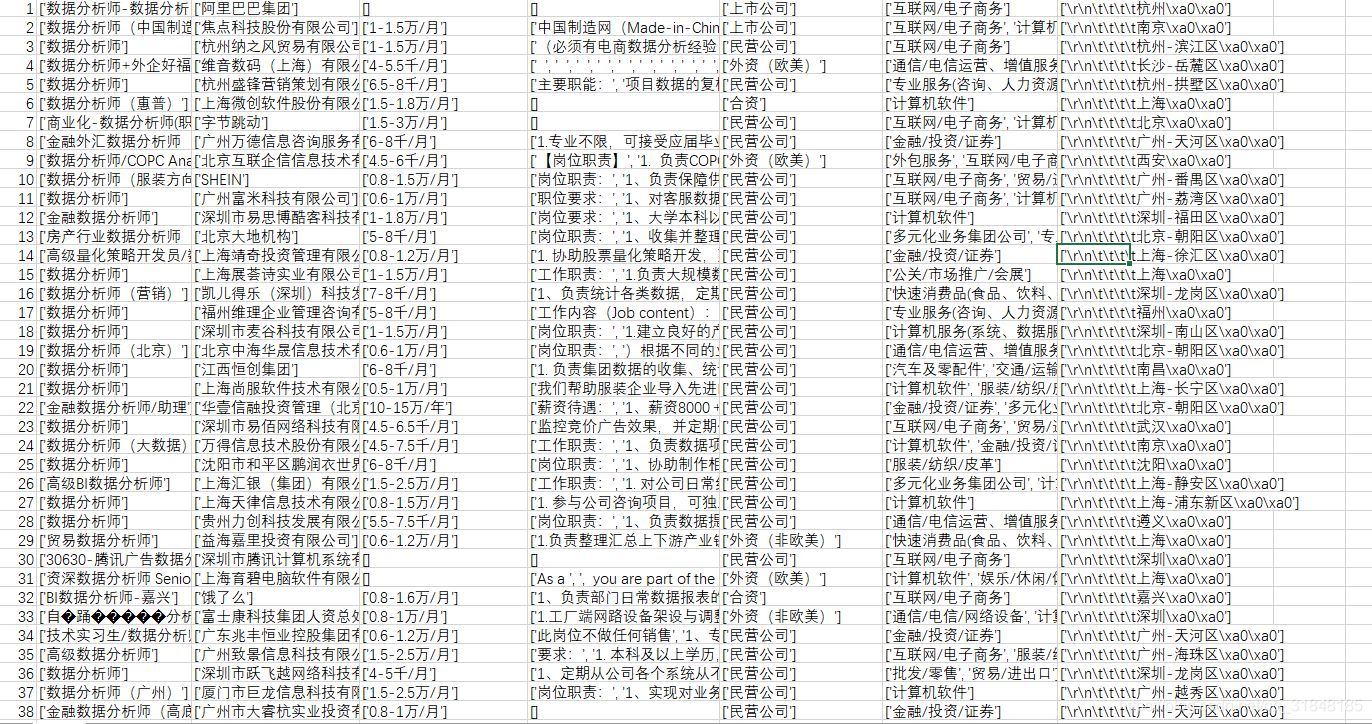
上面代码把保存方式也加上了。看看结果如何!
有些数据为空没获取到,排查原因是个别二级页面网页结构不一样导致,不影响整体使用。
欢迎大家持续关注,后期为大家带来更多分享。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!