社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
今天收到老师的一个题目:

于是我打开了图片网址:

发现并没有发现所有城市的天气情况
只有一个搜索栏

于是我输入成都按下F12查看网络请求发现了这个请求:

一共返回了四条数据对应提示框的四条数据,暂时不知道返回的数据有什么用,先点击搜索试一下

然后发现跳转到了另一个网页,如下:

我们需要的数据刚好在这里,那么问题来了我怎么知道第二个网页的地址是什么,怎么请求,我看了一下请求的地址再看了一下上一个页面返回的数据:
第二页:

第一页返回数据:

于是我猜测第二页的地址是由第一页返回的数据拼接出来的,我们再试几个关键词:


简直一模一样有木有QWQ
于是我们思路就有了:
第一页请求关键字获取数据进行字符串拼接,获得第二页的数据,再调用request请求第二页,最后利用Beautifulsoup获取我们需要的东西即可。
开始写代码:
所有城市关键字:
namelist=["成都","北京","上海","广州","杭州","武汉","南京","深圳","苏州","厦门","合肥"]
获取第一页返回数据:
url = "http://toy1.weather.com.cn/search?cityname=" + name + "&callback=success_jsonpCallback&_=1542459051265"
response = requests.get(url)
htmlstr = response.text
字符串拼接下一页地址:
#正则表达式 匹配以 :"开头 以~结尾的字符串
mlist = re.findall(r'(:".*?~)', htmlstr)
#字符串切片获取我们需要的citycode
citycode = mlist[0][2:-1]
nexturl = "http://www.weather.com.cn/weather1d/" + citycode + ".shtml#input"
请求下一页获取下一页HTML代码
html = requests.get(nexturl)
html.encoding = 'utf-8'
Beautifulsoup解析HTML(QWQ如果不知道怎么解析的请去看我Beautifulsoup使用的那篇博客)
soup = BeautifulSoup(html.text, "html.parser")
#找到class为clearfix city的所有<ul>标签
ans = soup.findAll("ul", class_="clearfix city")
#遍历<ul>标签下所有<li>标签
for item in ans[0].findAll("li"):
tmp=str(item.a.i.string).split("/")
print("%-10s %-12s %-14s %-18s" % (name, item.a.span.string, tmp[0] + "度", tmp[1]+"度"))
至此程序流程就结束的,附上一张运行结果GIF:
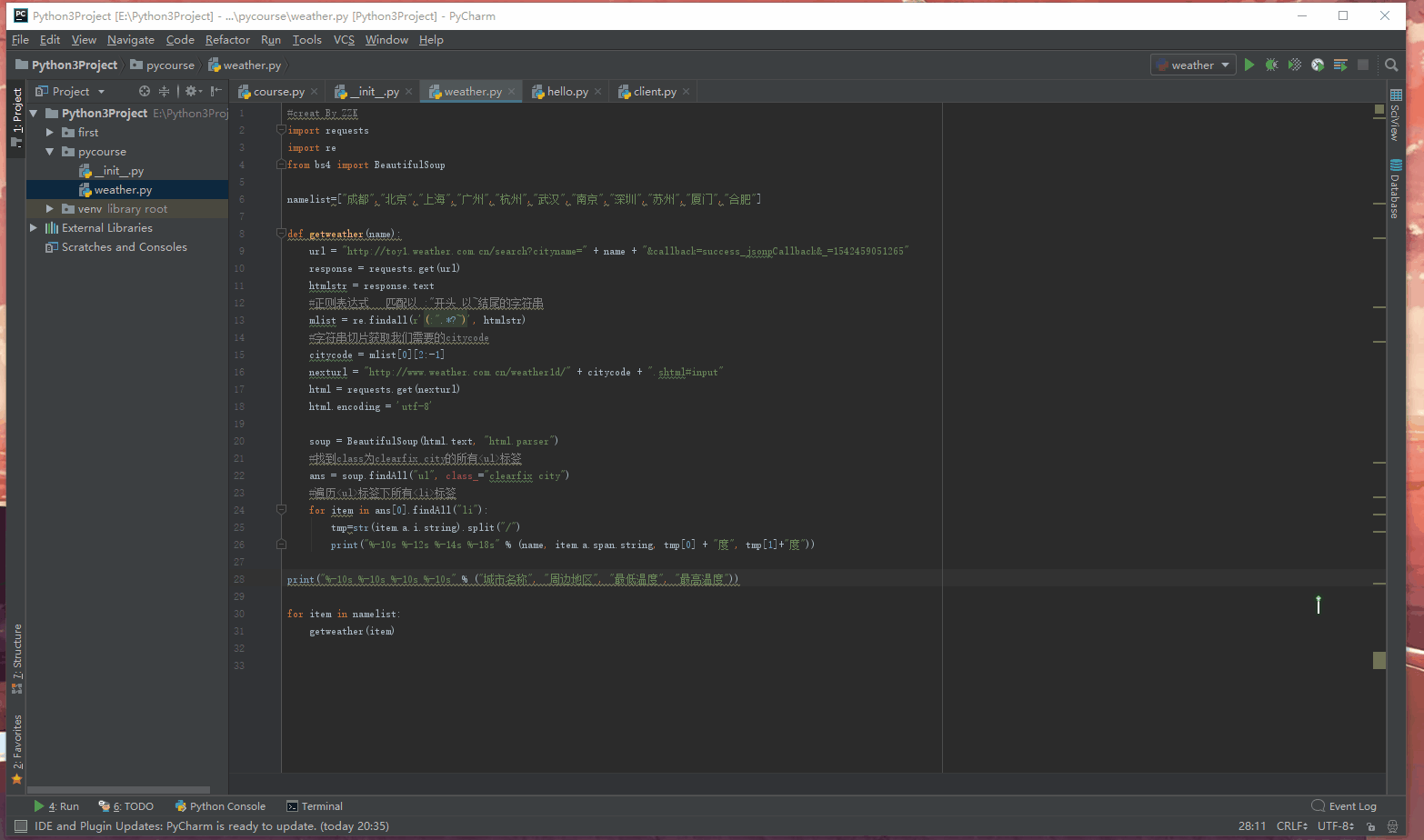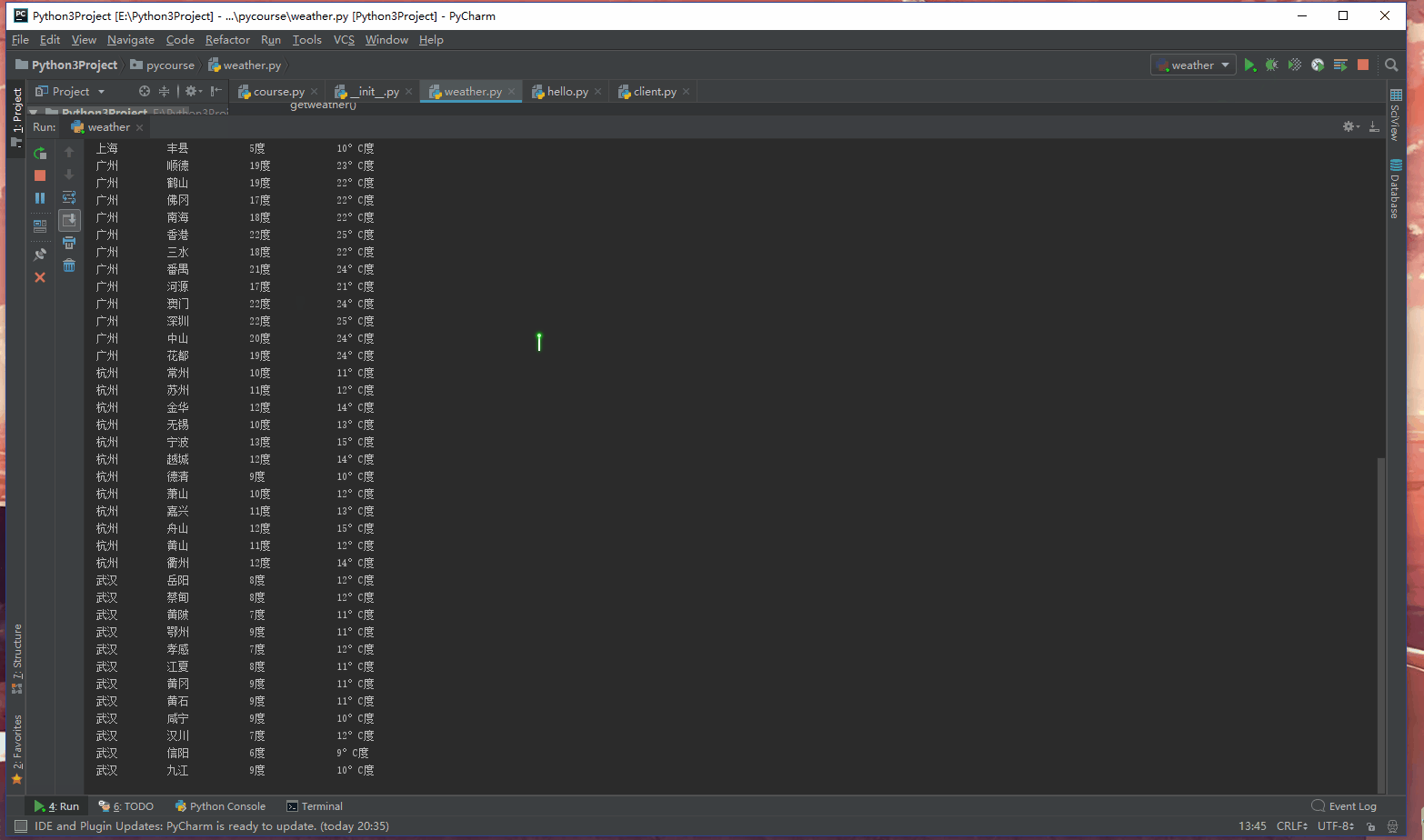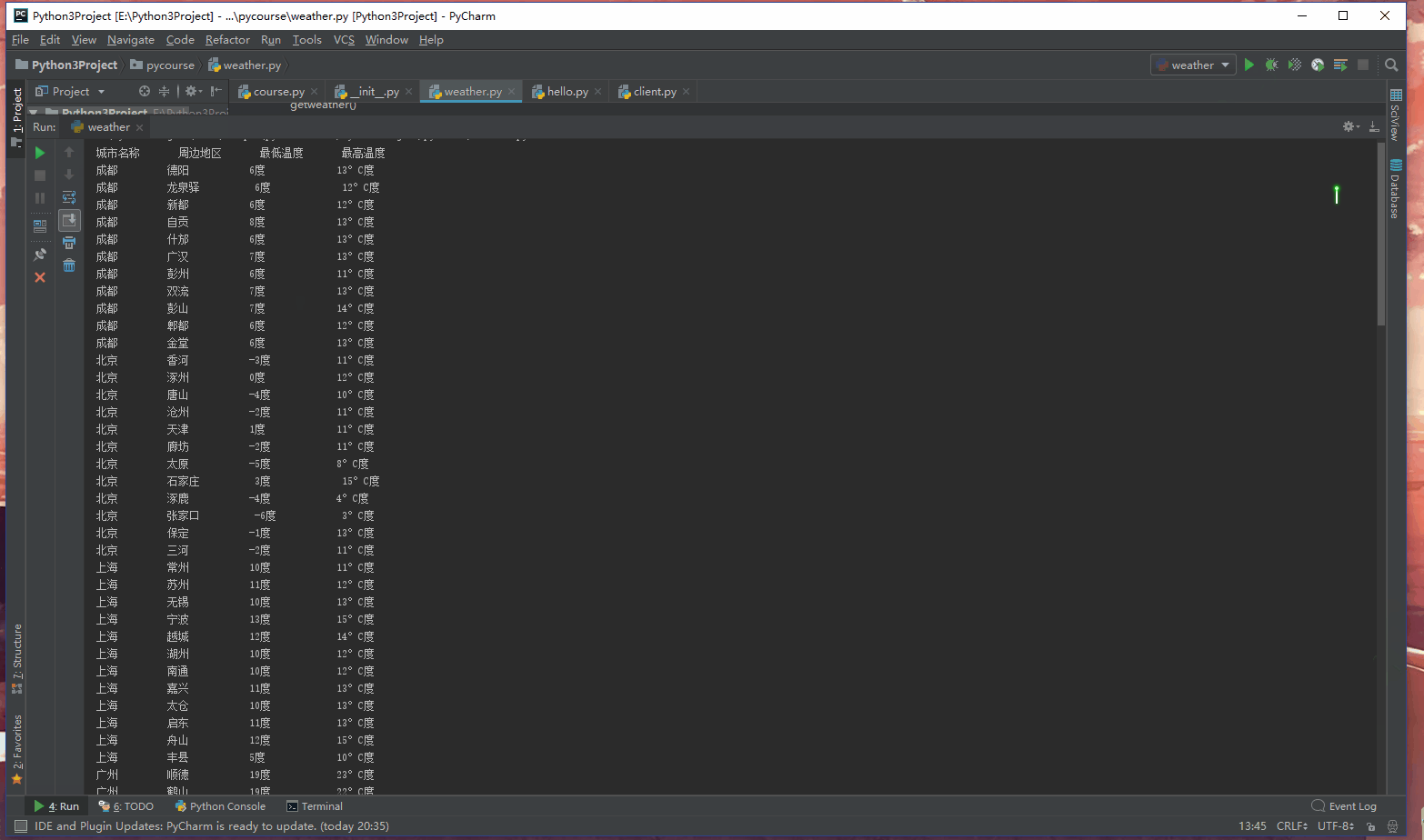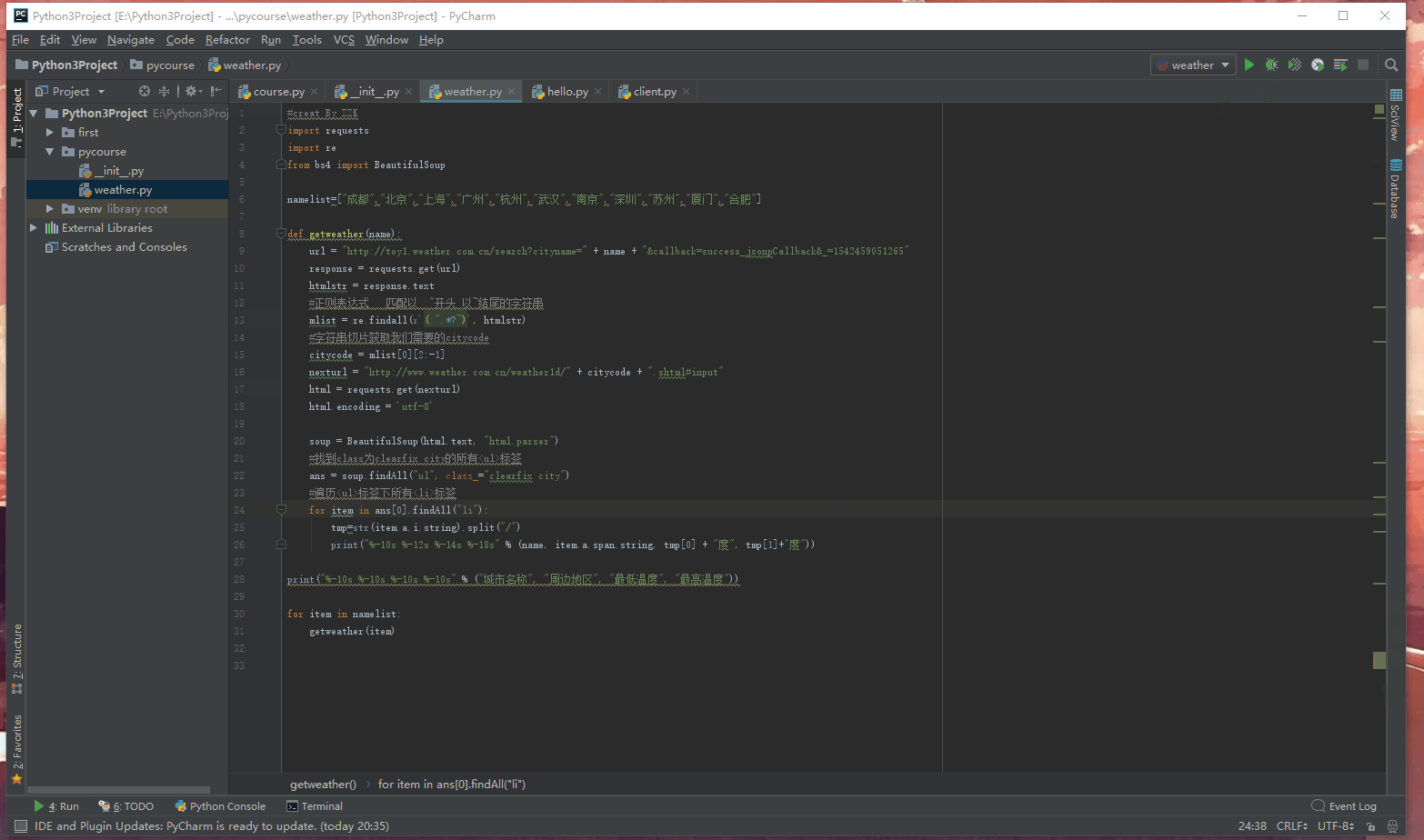
完整代码:
# creat By ZZK
import requests
import re
from bs4 import BeautifulSoup
namelist = ["成都", "北京", "上海", "广州", "杭州", "武汉", "南京", "深圳", "苏州", "厦门", "合肥"]
def getweather(name):
url = "http://toy1.weather.com.cn/search?cityname=" + name + "&callback=success_jsonpCallback&_=1542459051265"
response = requests.get(url)
htmlstr = response.text
# 正则表达式 匹配以 :"开头 以~结尾的字符串
mlist = re.findall(r'(:".*?~)', htmlstr)
# 字符串切片获取我们需要的citycode
citycode = mlist[0][2:-1]
nexturl = "http://www.weather.com.cn/weather1d/" + citycode + ".shtml#input"
html = requests.get(nexturl)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, "html.parser")
# 找到class为clearfix city的所有<ul>标签
ans = soup.findAll("ul", class_="clearfix city")
# 遍历<ul>标签下所有<li>标签
for item in ans[0].findAll("li"):
tmp = str(item.a.i.string).split("/")
print("%-10s %-12s %-14s %-18s" % (name, item.a.span.string, tmp[0] + "度", tmp[1] + "度"))
print("%-10s %-10s %-10s %-10s" % ("城市名称", "周边地区", "最低温度", "最高温度"))
for item in namelist:
getweather(item)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
