社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
首先要得到这张图片的地址,可以直接找到图片然后复制地址,还可以在网站中右击然后检查(谷歌浏览器快捷键是F12)中找到,这里用后种方式方便后面的理解,如图:
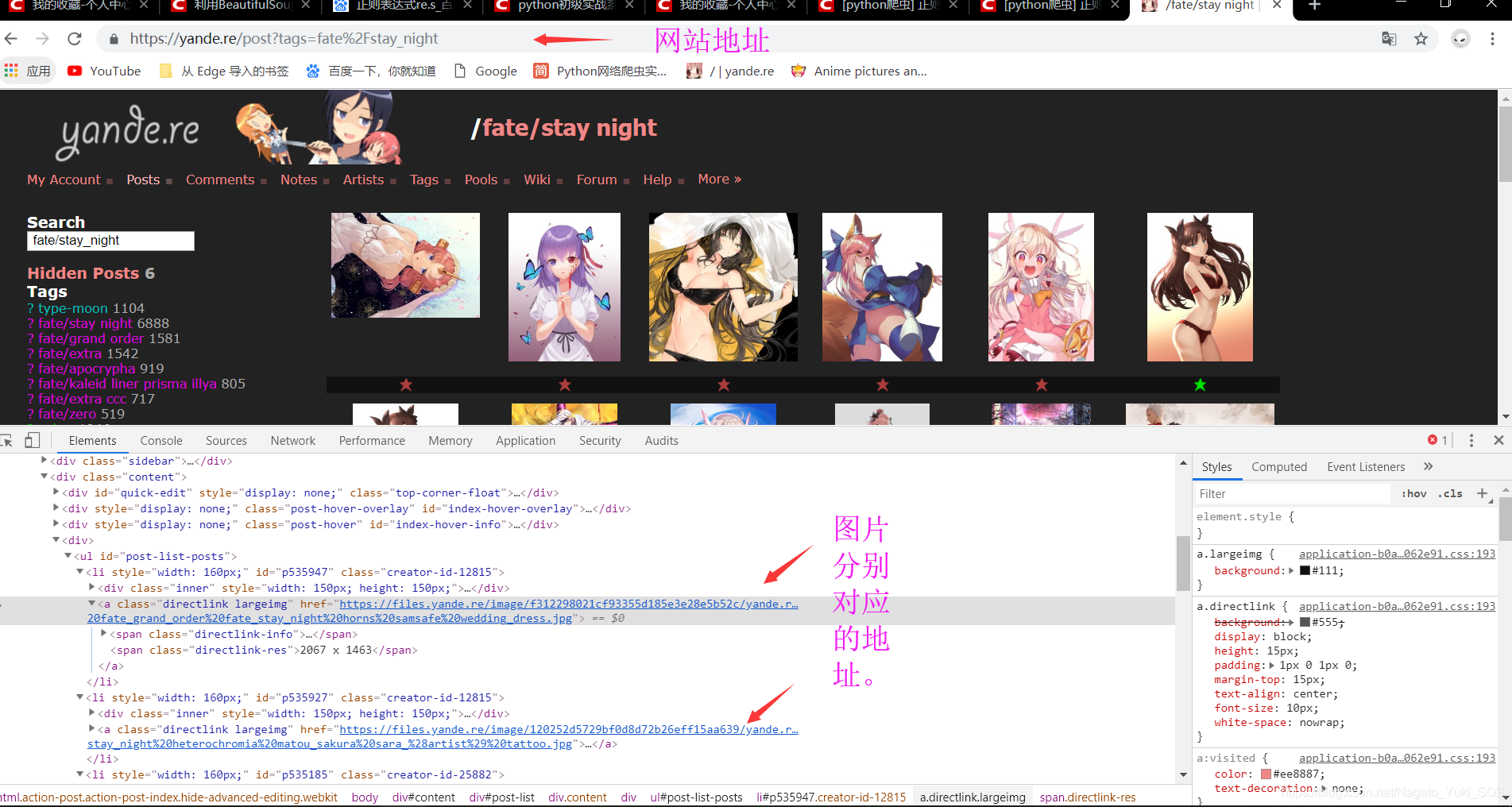
然后就可以把地址复制到代码中去,代码如下:
import requests
import os #这是一个和路径相关的库
#图片所在的网址,jpg,png等格式
url="https://files.yande.re/image/f312298021cf93355d185e3e28e5b52c/yande.re%20535947%20berserker_of_black_%28fate_apocrypha%29%20breast_hold%20cleavage%20dress%20fate_apocrypha%20fate_grand_order%20fate_stay_night%20horns%20samsafe%20wedding_dress.jpg"
root="F://pic//" #需要存储的根目录
path=root+url.split('/')[-1] #需要存储的路径以及文件名,若要自定义文件名则只需将改为path=root+"文件名.jpg
try: #处理异常用
if not os.path.exists(root): #判断根目录是否存在,不存在就创建
os.mkdir(root)
if not os.path.exists(path): #查看文件(文件路径)是否存在
r=requests.get(url) #浏览器向服务器发出请求
print(r.status_code) #查看状态码,结果为200则获取成功
with open(path,'wb') as f:
f.write(r.content) #把获取到的内容以二进制形式写入文件(图片等文件都是二进制存储的)
f.close() #写完后好像with自己会关,这行代码可要可不要
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
代码的详细注释都在上面,执行之后的图片如下: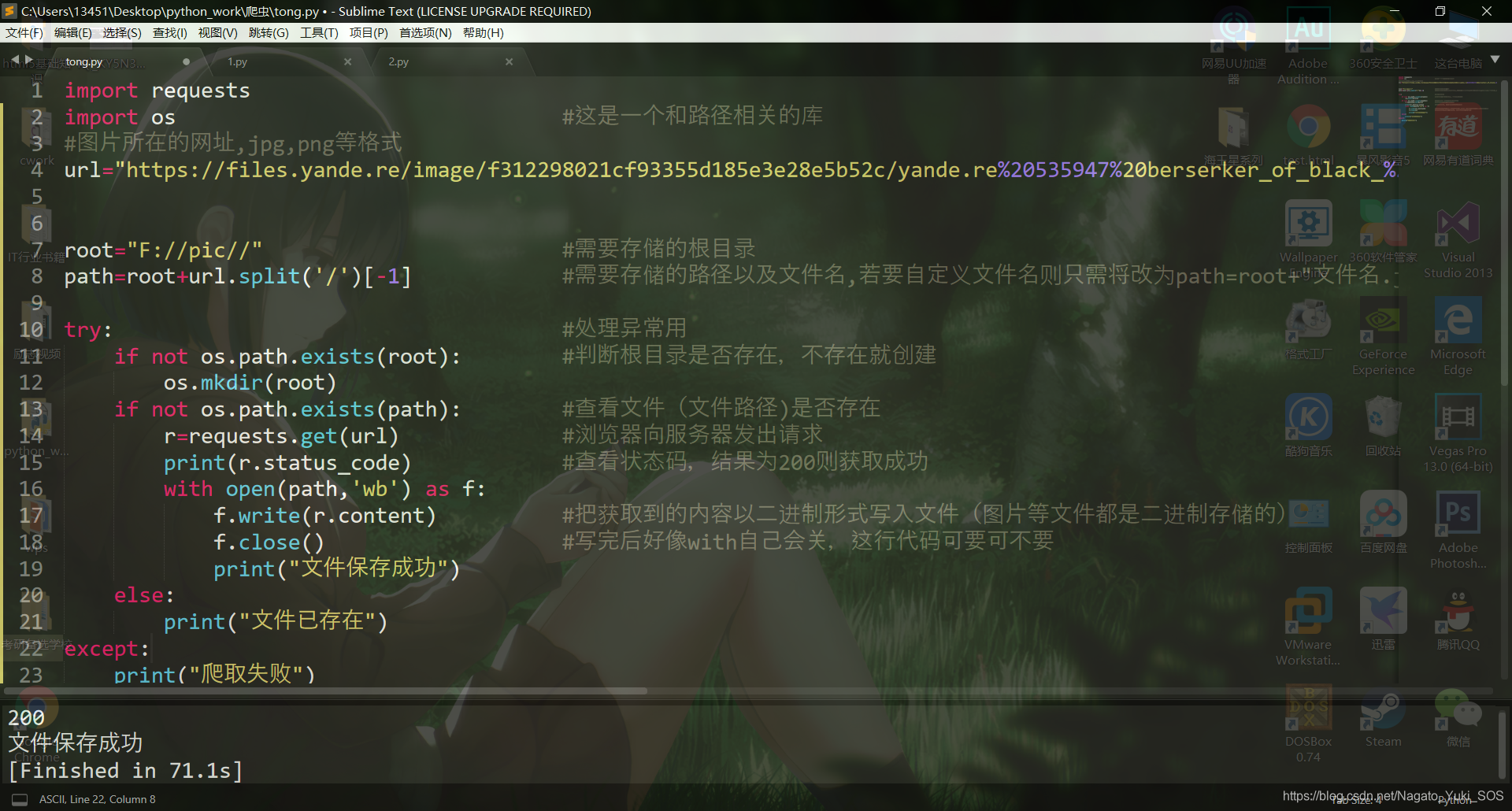
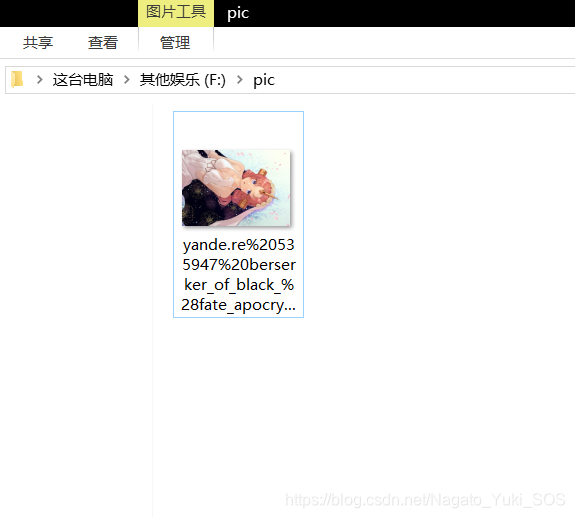
这张图片有2.11M的大小花了71秒,接下来,爬取一个网站的图片。
#图片等文件爬取全代码
import requests
import os
import re
from bs4 import BeautifulSoup
html="https://yande.re/post?tags=fate%2Fstay_night"
res=requests.get(html) #有了网站地址后向服务器发出请求
bs=BeautifulSoup(res.text,'lxml') #运用解析库解析获取的内容
#通过正则表达式和beautifulsoup的find_all函数获取所有图片的地址,并且以列表形式返回给images
images=bs.find_all("a",{"class":"directlink largeimg","href":re.compile(r".jpg")})
for image in images: #在列表中循环
url=image["href"]
root="F://pic//" #需要存储的根目录
path=root+url.split('/')[-1] #需要存储的路径以及文件名,若要自定义文件名则只需将改为path=root+"文件名.jpg"
try:
if not os.path.exists(root): #查看根目录是否存在,不存在就创建
os.mkdir(root)
if not os.path.exists(path): #查看文件(文件路径)是否存在
r=requests.get(url) #浏览器向服务器发出请求
with open(path,'wb') as f:
f.write(r.content) #把获取到的内容以二进制形式写入文件(图片等文件都是二进制存储的)
f.close() #写完后好像with自己会关,这行代码可要可不要
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
#图片等文件爬取全代码
import requests
import os
import re
from bs4 import BeautifulSoup
import random
import time
i=0 #用来计数
#代理ip,针对反爬虫机制
proxylist=[
{"http":"http://182.88.122.115:9797"},
{"http":"http://183.49.87.142:9000"},
{"http":"http://125.32.81.197:8080"}
]
proxy=random.choice(proxylist)
#请求头,针对反爬虫机制
agent1="Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36" #谷歌
agent2="Mozilla/5.0 (Windows NT 6.1; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36" #360
agent3="Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1;
WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5
.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C;
.NET4.0E; QQBrowser/7.0.3698.400)" #qq
agent4="Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11
(KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0" #搜狗
agent5="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36" #UC
list1=[agent1,agent2,agent3,agent4,agent5]
for x in range(0,10):
agent=random.choice(list1) #随机选一个ip地址
header={"User-Agent":agent} #随机选一个user-agent
html="https://anime-pictures.net/pictures/view_posts/"+str(x)+"?search_tag=katou%20megumi&order_by=date&ldate=0&lang=en"
res=requests.get(html,proxies=proxy,headers=header)
time.sleep(1) #有了网站地址后向服务器发出请求
bs=BeautifulSoup(res.text,'lxml') #运用解析库解析获取的内容
#通过正则表达式和beautifulsoup的find_all函数获取所有图片的地址,并且以列表形式返回给images
images=bs.find_all("img",{"src":re.compile(r".jpg")})
for image in images: #在列表中循环
url="http:"+image["src"]
root="F://路人女主1//" #需要存储的根目录
path=root+url.split('/')[-1] #需要存储的路径以及文件名,若要自定义文件名则只需将改为path=root+"文件名.jpg"
try:
if not os.path.exists(root): #查看根目录是否存在,不存在就创建
os.mkdir(root)
if not os.path.exists(path): #查看文件(文件路径)是否存在
r=requests.get(url,proxies=proxy,headers=header) #浏览器向服务器发出请求
time.sleep(1)
with open(path,'wb') as f:
f.write(r.content) #把获取到的内容以二进制形式写入文件(图片等文件都是二进制存储的)
f.close() #写完后好像with自己会关,这行代码可要可不要
print("文件保存成功"+str(i))
i=i+1
else:
print("文件已存在"+str(i))
i=i+1
except:
print("爬取失败"+str(i))
i=i+1
print(i)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
