社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
想了解决策树的原理,可以看我关于决策树理论的介绍
| 共同参数 | 含义 |
|---|---|
| max_depth | 决策树最大深度:默认可以不输入,决策树在生成的时候不会限制树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。 |
| max_features | 划分时考虑的最大特征数:默认是”None”,意味着划分时考虑所有的特征数。可以使用很多种类型的值,如果是”log2”意味着划分时最多考虑个特征;如果是”sqrt”或者”auto”意味着划分时最多考虑个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。一般来说,如果样本特征数不多,比如小于50,我们用默认的”None”就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。 |
| max_leaf_nodes | 最大叶子节点数:默认是”None”,即不限制最大的叶子节点。通过限制最大叶子节点数,可以防止过拟合,数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。 |
| min_samples_split | 内部节点再划分所需最小样本数:默认是2,适合样本量不大的情况。这个参数限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。如果样本量数量级非常大,则推荐增大这个值。 |
| min_samples_leaf | 叶子节点最少样本数:默认为1,这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。 |
| min_weight_fraction_leaf | 叶子节点最小的样本权重和:默认为0.0,就是不考虑权重问题。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。 |
| min_impurity_split | 节点划分最小不纯度:默认为None。这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点,即为叶子节点 。 |
| presort | 数据是否预排序:默认是False,不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。 |
| splitter | 特征划分点选择标准:默认的”best”,适合样本量不大的时候。可以使用”best”或者”random”。前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。而如果样本数据量非常大,此时决策树构建推荐”random” |
| 不同参数 | 含义 | 分类 | 回归 |
|---|---|---|---|
| criterion | 特征选择标准 | 可以使用”gini”或者”entropy”,前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数”gini”就可以了,即CART算法。除非你更喜欢类似ID3, C4.5的最优特征选择方法。 | 可以使用”mse”或者”mae”,前者是均方差,后者是和均值之差的绝对值之和。推荐使用默认的”mse”。一般来说”mse”比”mae”更加精确。除非你想比较二个参数的效果的不同之处。 |
| class_weight | 类别权重 | 指定样本各类别的的权重,默认是None。为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别,可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。如果你的样本类别分布没有明显的偏倚,使用默认即可 | 无 |
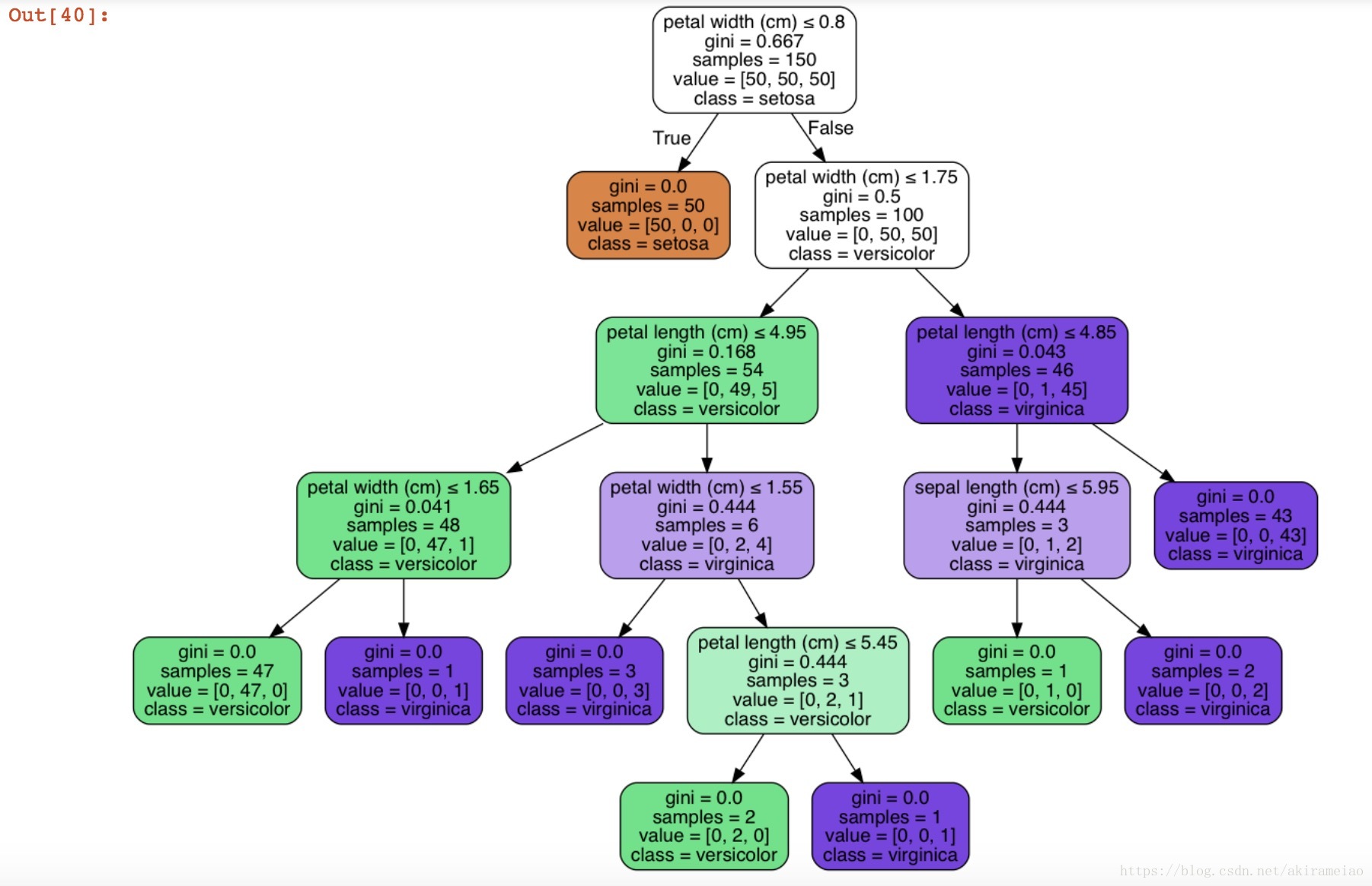
DecisionTreeClassifier 是能够在数据集上执行多分类的类。采用输入两个数组:数组X,用 [n_samples, n_features] 的方式来存放训练样本。整数值数组Y,用 [n_samples] 来保存训练样本的类标签:
Step1:安装Graphviz,graphviz和pydotplus包(如果已经安装Graphviz,请跳过第一步)
brew install Graphviz
pip3 install graphviz
pip3 install pydotplus
Step2:
from sklearn import tree
from sklearn.datasets import load_iris
from IPython.display import Image
import pydotplus
# 使用iris数据
iris=load_iris()
# 生成决策分类树实例
clf = tree.DecisionTreeClassifier()
# 拟合iris数据
clf = clf.fit(iris.data, iris.target)
# 预测类别
clf.predict(iris.data[:1, :])
# 分别预测属于所有类别的可能性
clf.predict_proba(iris.data[:1, :])
# 可视化决策树
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
# 显示图片
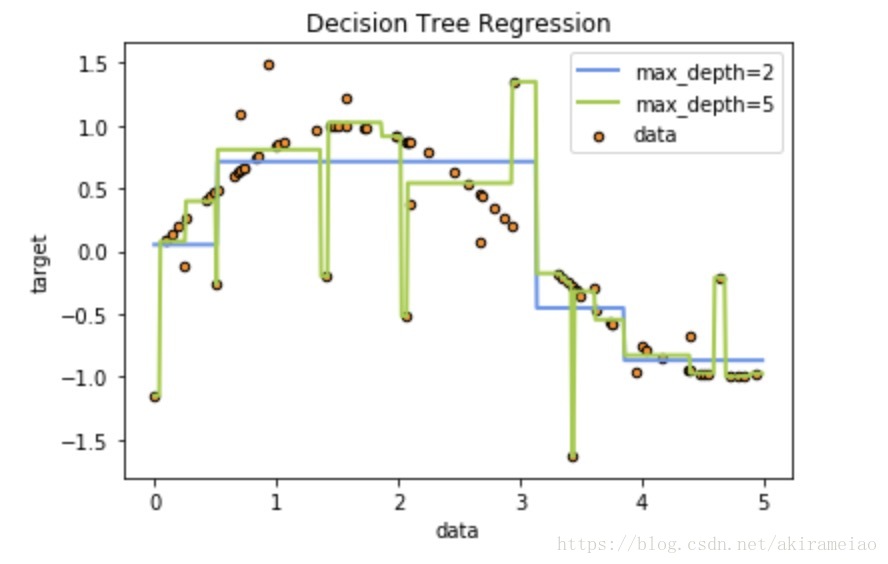
Image(graph.create_png())from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 生成一个随机数据集
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
# 训练模型
tree1 = DecisionTreeRegressor(max_depth=2)
tree2 = DecisionTreeRegressor(max_depth=5)
tree1.fit(X, y)
tree2.fit(X, y)
# 预测
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y1 = tree1.predict(X_test)
y2 = tree2.predict(X_test)
# 画出结果
plt.figure()
plt.scatter(X, y, s=20, edgecolors='black',
c='darkorange', label='data')
plt.plot(X_test, y1, color="cornflowerblue",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!