社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
字段要具有原子性,不可以继续拆分,一般根据实际需求来去决定
例如此例,每个字段在此需求不可拆分,因此满足第一范式
建立在第一范式的基础上,每一列数据必须可以被唯一的区分,依赖于主键 每一张表至少要有一个主键
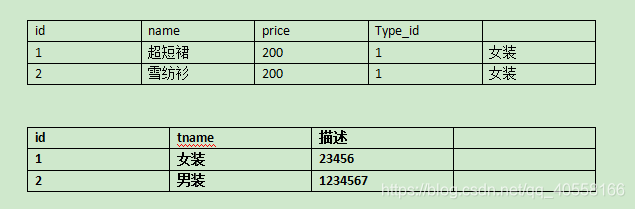
建立在第二范式的基础之上,一般应用于设计多表关系中,要求一个数据表中不包含已在其他表中已包含的非主键字段,因为会出现冗余,表的信息如果能被推导出来就不应该单独设计一个字段来存储,可以使用外键进行关联,而不是将另一张表中的非主键属性直接写在当前表中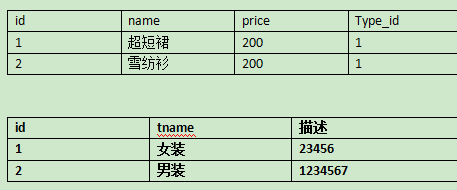
在此例子,如果我们把每个商品后都写分类,会造成数据冗余,因此我们单独建立一个类别表并且和第一个商品表进行关联
允许部分字段冗余
总结:三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
①添加缓存:大多数MySQL服务器都启用了查询缓存。这是提高性能的最有效方法之一,由数据库引擎悄悄地处理。当同一查询多次执行时,结果将从缓存中获取,这是相当快的。(般使用非关系数据库做为缓存数据库 将数据存到内存中)
①允许部分字段冗余,使用逻辑外键避免使用物理外键
②添加索引:给查询频繁的条件添加索引,使用索引最左原则
③查询时 select 后面不使用*
④避免修改where后面字段
⑤sql关键字尽量大写
⑥使用关联查询替代嵌套子查询
⑦使用where条件过滤 避免全表查询
⑧Update修改时,避免修改索引字段所在的列
⑨将ip地址存储为无符号int
当单个库或者表中的数据量大时 数据库的性能会变慢
解决:分库分表:垂直拆分和水平拆分
————————————垂直拆分————————————————
①垂直拆分表
当一个表中的数据量比较大字段比较多时,创建一个附属表,将表中不常用的字段存入附属表,通过创建外检进行关联
②垂直拆分库
根绝不同的业务需求,将不同的表放入不同的库中,一般会放到多个服务器上
————————————水平拆分————————————————
①水平分库分表
单表数据量太大 将数据水平拆分成多个表,多个表组合在一起才能组成一个完成的数据
将拆分的表放到不同的库中
??????????????水平拆分面临的问题: 主键如何保证唯一性????????
1.制定每张表的id取值范围
2.通过时间或者地理位置
3.通过趋势递增 雪花算法
水平分库 会面临 多表查询会受到影响 事物也会受到影响
目前没有人能解决这些问题,我们可以使用开源的框架产品来解决
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
