社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
 - 通过观察搜索页的URL地址,我们就可以发现对应的搜索内容一样的时候,不同的城市对应的编号不一样。
- 通过观察搜索页的URL地址,我们就可以发现对应的搜索内容一样的时候,不同的城市对应的编号不一样。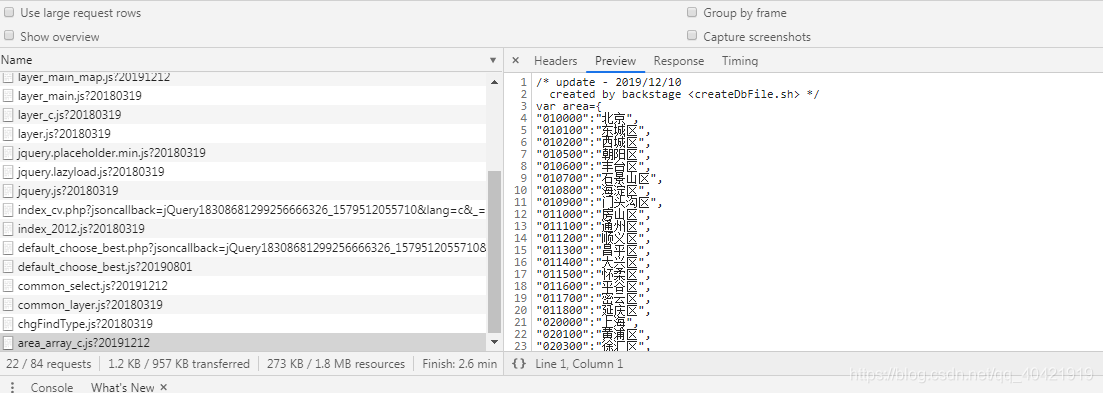
def get_city_code():
url = 'https://js.51jobcdn.com/in/js/h5/dd/d_jobarea.js?20191212'
r = requests.get(url)
begin = r.text.find('var hotcity')
if begin == -1:
print('Not find var hotcity')
# print(begin)
end = r.text.find(';',begin)
if end == -1:
print('Not find ; ')
# print(end)
result_text = r.text[begin : end-1]
#print(result_text)
begin = result_text.find('{')
city_dict_str = result_text[begin:]
# print(city_dict_str)
key,value = "",""
key_list,value_list = [],[]
count = 1
i = 0
while i < len(city_dict_str):
if city_dict_str[i] == '"' and count == 1:
count = 2
i += 1
while city_dict_str[i] != '"':
key += city_dict_str[i]
i += 1
key_list.append(key)
key = ""
i += 1
if city_dict_str[i] == '"' and count == 2:
count = 1
i += 1
while city_dict_str[i] != '"':
value += city_dict_str[i]
i += 1
value_list.append(value)
value = ""
i += 1
i += 1
city_dict = {}
i = 0
while i < len(key_list):
city_dict[value_list[i]] = key_list[i]
i += 1
# print(city_dict)
return city_dict
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'Host' : 'search.51job.com',
'Upgrade-Insecure-Requests' : '1'
}
# 获取职位总页数
def get_pageNumber(city_code,keyword):
url = 'https://search.51job.com/list/' + str(city_code) +
',000000,0000,00,9,99,' + str(keyword) + ',2,1.html'
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.content.decode('gbk'),'html5lib')
find_page = soup.find('div',class_='rt').getText()
temp = re.findall(r"d+.?d*",find_page)
if temp:
pageNumber = math.ceil(int(temp[0])/50)
return pageNumber
else:
return 0
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
