社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
百度指数在改版之前它的获取逻辑可以说是非常复杂。。。算是比较经典的了。。。看过很多人的文章,人们有用图片截取然后识别,有的是用 比例计算。。。都算是可用的方法,一个偶然的机会,在github上面找到一个百度指数的爬虫项目,方法算是比较新颖,给了我一点启发,selenium还可以这样用,真的是学到了,附上链接,有兴趣的小伙伴可以去研究一下 https://github.com/longxiaofei/spider-BaiduIndex
改版后反而改简单了,就获取而言,本人也没有大规模抓取,不知道有没有其他什么坑,有兴趣对小伙伴自行尝试吧,我们只说获取的逻辑办法啊,代码什么的,就要靠你自己了。。fighting !!
首先,改版之后现在没有了图片的形式,直接接口就会返回数据,不过有趣的是

这里的这个日均值是可以直接获取的,但是下面的具体每天的指数数据,确实一堆加密的乱码
这里就是重点了,这个接口同时还会返回一个uniqid, 第一张图里面可以看到的啦,
看到了吧,这里还会有这个接口回去请求 另一个加密的参数
然后呢, 这两个接口里面的参数经过一段js代码的解密之后就可以得到每天的数据了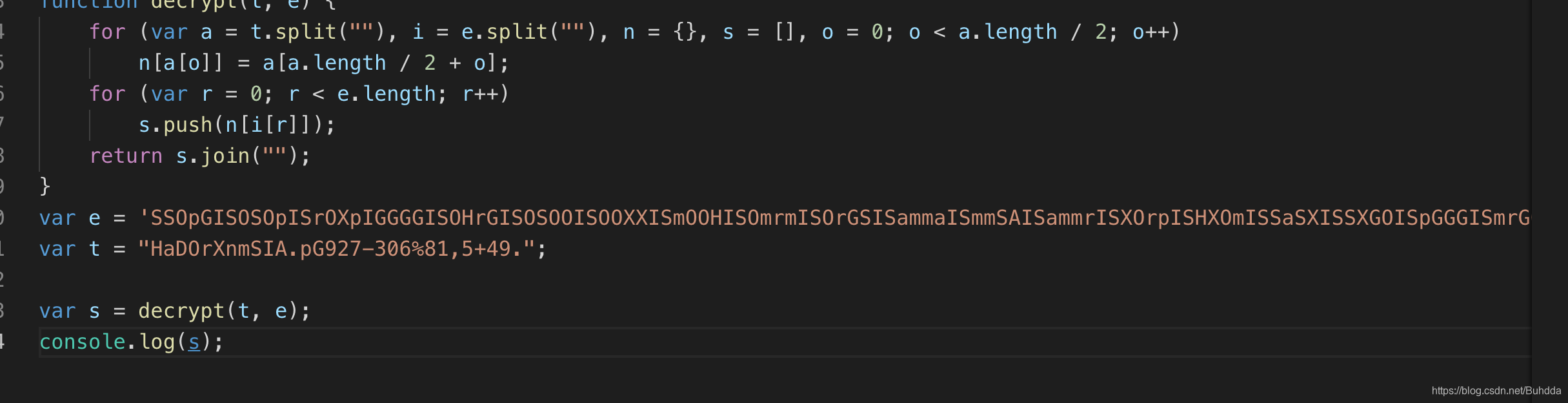
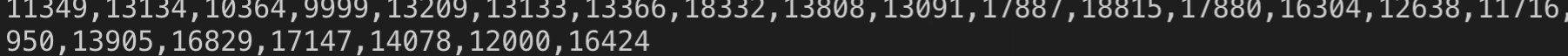
这就是执行上面的代码得到的结果了,至于这段js代码的位置具体在哪,请看下一张截图: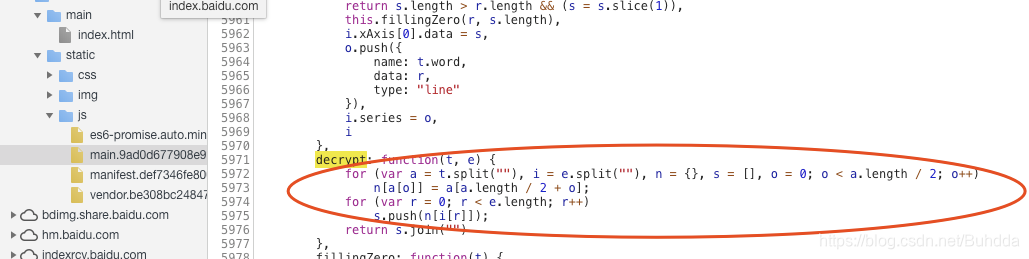
就是再这个位置了,然后我们按这个去解密,就可以得到正确的结果啦,是不是改版之后的弯弯绕少了好多呀,
####### 新旧比较
个人感觉其实旧版挺好的,界面也很舒服,现在数据的获取难度可以说是低了很多,当然如果大量爬取的时候会不会有问题,这可能就需要你自己去测试了,见招拆招嘛,如果没招了,那就算啦,
哈哈 0.0 (个人很推荐ghithub的那个项目,虽然简单,但是有一些思路其实是值得学习的,向作者致敬啦!!!!!!!)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
