社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
提示:以下内容是对《Java多线程编程实战指南》的分析与总结,有截选《实战Java高并发程序设计》。
程序在执行过程中,可能会进行指令重排序,重排序后的指令与原指令的顺序未必一致。
重排序是对内存访问有关操作所做的一种优化,可以在不影响单线程程序正确性的情况下提升程序性能。
这里我们知道,重排序是为了优化程序的执行效率,并且在单线程下能够保证程序的正确执行。
先来介绍相关的几个概念知识:
什么时候会发生指令重排序:
由于javac编译器将.java文件编译成.class文件发送的指令重排序基本不会发生,这里就不介绍了。主要介绍下面这两种。
通过一个例子来分析指令重排序的过程。
Object obj = null;
obj = new Object();
1)分配Object实例所需的内存空间,并获取一个指向该空间的引用。
objRef = allocate(Object.class);
2)调用Object类的构造器初始化objRef引用指向的Object实例。
invokeConstructor(objRef);
3)将Object实例引用objRef赋值给实例变量obj。
obj = objRef;
如果JIT编译器按照源代码顺序生成相应的机器码,其逻辑应和上述伪代码逻辑一致。而以JIT编译器的视角来看应当是如下的:
步骤(1)一定是先于步骤(2)(3)之前执行的,步骤(2)和(3)之间没有依赖关系,因此可以对(2)和(3)进行指令重排序,至于谁先谁后就看哪条指令先加载。所以就可能出现步骤(3)先于步骤(2)执行的这种情况。
分析上面重排序后会出现什么问题。
假如一个线程执行了步骤(1),由于重排序导致步骤(3)先执行了,这时另一个线程需要使用到obj变量。比如他执行的代码如下,由于此时obj变量已经不为null(但未完成初始化),因此会调用下面打印函数,最终结果就是报错。
if (obj != null) {
System.out.println(obj.toString());
}
现代处理器为了提高指令执行效率,往往不是按照程序顺序逐一执行指令的,而是动态调整指令的顺序,做到哪条指令就绪就先执行哪条指令,这就是处理器对指令进行的重排序,也称为处理器的乱序执行。
处理器执行程序的过程:
比如我们要做A、B、C三件事(假设都是写操作),那么即使C先于B做了,那么C也得先到重排序缓冲器里等着,等最终做完了再按A、B、C顺序提交。
正由于执行结果是按程序顺序进行提交,因此处理器的指令重排序并不会对单线程从程序的正确性产生影响。
处理器的乱序执行还采用了一种被称为猜测执行的技术,猜测执行可能导致if语句体先于条件语句执行。
那为什么还使用猜测执行?
这就要使用到上面的重排序缓冲器了,如果if语句体先于条件语句执行,那么先把结果存到重排序缓冲器就行了,如果后面判断为true,就将重排序缓冲器中的值刷新到主存或高速缓存中,否则直接抛弃。
上面介绍了编译器和处理器在执行程序的过程中可能对执行进行重排序,我们也知道了重排序是对程序的一种优化手段,对于什么时候会发生重排序我们是不得而知的,但对什么时候不能进行重排序,确实有规定的。
Happen-Before规则(什么时候不能进行重排序)?
以上内容引用自《实战Java高并发程序设计》
总的来说就是要保证语义正确、没有锁和volatile、没有数据依赖关系、没有函数的依赖关系(原谅我这种不规范的称呼 )。
注意:这里提一下控制依赖关系,一条语句的执行结果决定另一条语句能否被执行,那么这两条指令之间就存在控制依赖关系。存在控制依赖关系的语句是可以允许被重排序的。
上面介绍了编译器和处理器的指令重排序,其实还有第三种影响程序有序性的因素:存储子系统重排序。
从上面copy,希望大家还有映像:
感知顺序?什么是感知顺序,感知顺序即——处理器所看到的该处理器和其他处理器的内存访问操作发生的顺序。
这里可能并没有弄懂是什么意思,先来介绍什么是存储子系统。
我们都知道直接从主内存获取数据是相对较慢的,因此我们通常都是通过高速缓存访问主内存。现代处理器还引入了写缓冲器以提高写高速缓存操作的效率。(写缓冲器和高速缓存就可以被称为存储子系统)。
一个处理器执行了写操作A、B,但由于某些处理器的写缓冲器为了提高将内容写入高速缓存的效率而不保证写操作结果先进先出,这就导致了存储子系统的重排序。也就是我这边执行了A、B,别人那可能先看到了B!
----------------------------------------------------------------分割线----------------------------------------------------------------------
从处理器角度来说,读内存操作的实质是从指定的RAM地址加载数据到寄存器,因此读内存也称为Load。
写内存操作的实质是将数据存储到指定地址表示的RAM存储单元中,因此写内存也称为Store。
4种内存重排序:
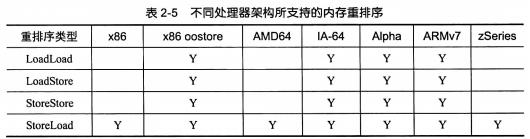
上图引用自《Java多线程编程实战指南》
存储子系统重排序是一种现象而不是一种动作,并没有像处理器重排序以及编译器重排序一样对指令执行顺序进行调整,其重排序的对象是内存操作的结果。
以上内容如有错误,欢迎纠正!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
