社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
从url对列中拿到url,下载页面,返回html的内容,然后解析就可以拿到需要的信息,但是微博的页面不是这样的,如果按照这个做法,返回html的body中什么都没有,得到的内容会是: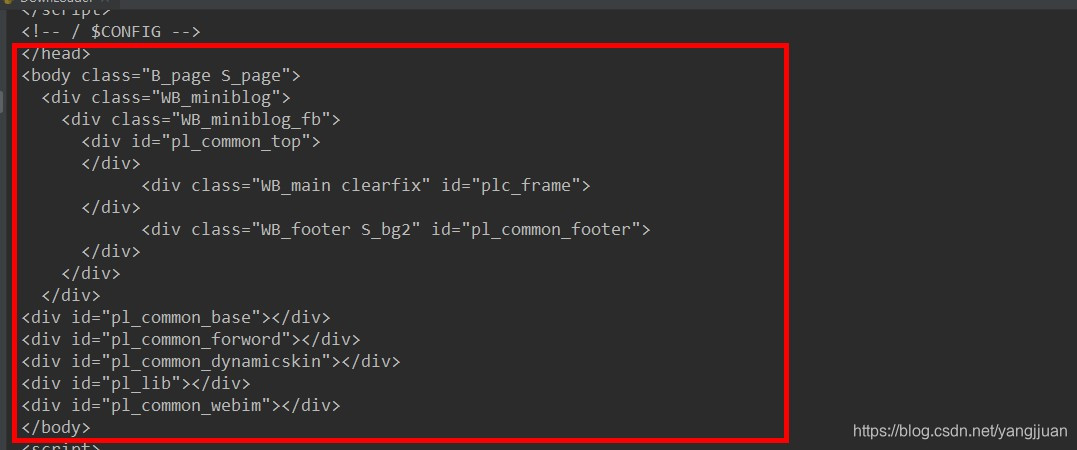
遇到这种情况,就会考虑这些页面的内容是动态加载,可以有以下两种方式
1,可以使用selenium模拟浏览器,加载完页面后,再用selenium提供的方法定位就可以获取内容。,
2,模拟ajax发送request,从response中获取内容。
通过分析页面加载的过程,没有发现有ajax异步请求加载,但是selenium又不太稳定,有时会加载很久。那怎么获取内容呢?想了想,如果木有ajax异步请求,那么其实在第一次请求页面的时候,页面上的信息就已经返回了,只是没有显示出来,所以,是通过js显示response的内容?后面发现页面有很多<script>…<script>,内容都是相同的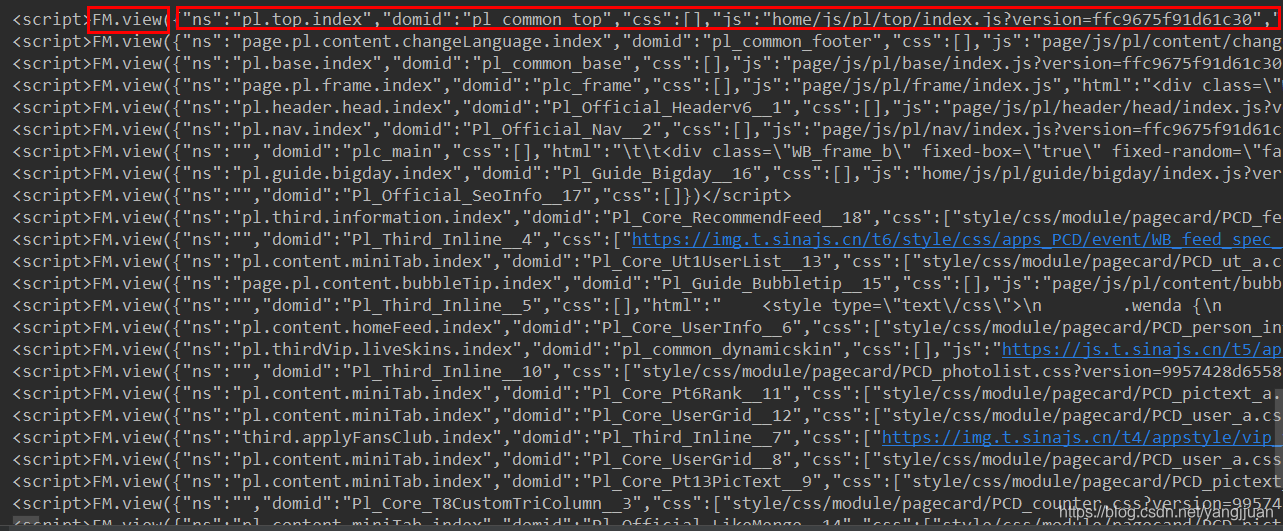
FM.view中哟参数是json格式的数据,json数据中还有‘html’的key,value就是对应页面加载的内容。所以,要做的就是解析这些<script>中json数据中html的内容。每个<script>对应的内容是不一样的,经过对比,文章页和列表页都是以这种方式进行加载。
总结下:页面通过js加载内容,内容是js中json的‘html’的value,而且可以通过json中的‘domid’定位到对应的内容。
<script>FM.view(
{"ns":"page.pl.frame.index",
"domid":"plc_frame",
"css":[],
"js":"page/js/pl/frame/index.js",
"html":"<div class="WB_frame">rn <textarea node-type="skin_style" style="display: none" readonly>//img.t.sinajs.cn/t6/skin/skin048/skin.css?version=65a933199b3fb416</textarea>rn t<div class="WB_frame_a">rn t<div id="Pl_Official_Headerv6__1"></div>rn t<div id="Pl_Official_Nav__2" name="place" anchor="-50"></div>rn t </div>rn tt<div id="plc_main"></div>rnt</div>"}
)</script>
一,解析列表页得到文章页url,以及下一页列表的url
detail_url_html = re.search(r'{(.*?)"domid":"Pl_Core_F4RightUserList__4"(.*?)}', text)
if detail_url_html:
# print(detail_url_html.group())
data = json.loads(detail_url_html.group(), strict=False)
html = etree.HTML(str(data.get('html')))
#判断返回的页面内容是否为空
error_selector = html.xpath('//div[@class="WB_empty"]')
if len(error_selector) == 0: #内容不为空
urllist_selectors =html.xpath('//dt[@class="mod_pic"]/a/@href')
# 获取详细页url
for urllist_selector in urllist_selectors:
detail_url = 'https:' + urllist_selector
print(detail_url)
self.lowlevel_db.addUrl(detail_url)
nexturl_selector = html.xpath('//a[@class="page next S_txt1 S_line1"]/@href')
# print(nexturl_selector)
if nexturl_selector :
next_url = 'https://d.weibo.com' + nexturl_selector[0]
print(next_url)
self.highlevel_db.addUrl(next_url)
else:
print('已经是最后一页')
else:#内容为空
print(data.get('html'))
self.highlevel_db.addUrl(page.get('url'))
这里需要注意,在频繁访问时,会返回一个空页面,这还是就需要将对应的url放回队列之中,后面在进行访问。除此之外,还需要判断是否到了最后一页,如果到了最后一个列表页,此时的下一页对应的‘href’会是空的!
比如,解析 https://d.weibo.com/1087030002_2975_1001_0# 的结果,只要一页,没有下一页。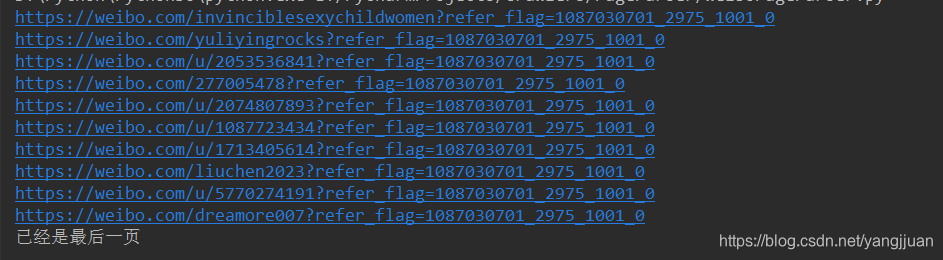
二,解析文章页,获取相关信息。
文章页包含的东西很多,可以F12,定位到对应的’domid’,再使用正则表达式匹配到对应的<script>,解析里面的json数据,获取到‘html’的value后,就可用lxml进行解析。下面的代码是获取关注数,粉丝数,博客数。
#定位<script>
second_part = re.search(r'{(.*?)"domid":"Pl_Core_T8CustomTriColumn__3"(.*?)}', text)
if second_part:
data = json.loads(second_part.group(), strict=False) #解析json数据,获取html的value
html = etree.HTML(str(data.get('html')))
selectors = html.xpath('//a[@class="t_link S_txt1"]/strong') #使用lxml解析
# print(selectors)
if selectors:
# 关注数
self.info_data['followers_num'] = selectors[0].text
# 粉丝数
self.info_data['fans_num'] = selectors[1].text
# 微博数
self.info_data['weets_num'] = selectors[2].text
代码已经上传至GitHub,仅供参考
https://github.com/yangjunjians/Crawlers
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
