
列表,元组,字典,集合分别如何增删改查及遍历。
列表是有序的,我们可以用之前学过的for循环遍历它,然后输出列表中的每一个值。元组属于特殊的列表 S=(,,,),其内部元素不可以编辑,只可以S[0]方式查询。字典是python中唯一的映射类型,采用键值对的形式存储数据。
总结列表,元组,字典,集合的联系与区别。
1、列表
列表是处理有序项目的数据结构。创建了一个列表,就可以添加,删除,同时也可以搜索列表中的项目
2、元组
元组和列表十分相似,不过元组是不可变的。元组通常用在使语句或用户定义的函数能够安全的采用一组值。
3、字典
它们的键或者值对用冒号分割,而各个对用逗号分割。另外,记住字典中的键/值对是没有顺序的。
dict1 = { 'key':'value', 'key1':'value1' } a = [('key1','value1'),('key2','value2')] dict1 = dict(a) dict1 = {}.fromkeys(['key1','key2'],'default_value') dict1 = dict(key1='value1',key2='value2')
4、集合
与字典类似,但只包含键,而没有对应的值,包含的数据不重复。
词频统计
(1)下载一长篇小说,存成utf-8编码的文本文件file;
(2)通过文件读取字符串str;
(3)对文本进行预处理;
(4)分解提取单词list;
(5)单词计数字典set,dict;
(6)按词频排序list.sort(key=lambda),turple;
(7)排除语法型词汇,代词、冠词、连词等无语义词;
(8)输出TOP(20);
(9)可视化:词云。
排序好的单词列表word保存成csv文件。
仿照老师的代码如下:
exclude={'me','is','xie','xbk','sd','we','gt','bbq','ty','hr','te','ew','fd','gf','cxv'} #首先定义一个数组#
#读取从网上复制黏贴的英文小说内容#def gettxt():
sep=".,:;?!-_'"
txt=open('wej.txt','r').read().lower()
for ch in sep :
txt=txt.replace(ch,' ')
return txt
#提取小说里面的单词#
bigList=gettxt().split()
print(bigList);
print('big:',bigList.count('big'))
bigSet=set(bigList)
#过滤单词#
bigSet=bigSet-exclude
print(bigSet)
#统计提取出来的单词次数#
bigDict={}
for word in bigSet:
bigDict[word]=bigList.count(word)
print(bigDict)
print(bigDict.items())
word=list(bigDict.items())
#按26个英文字母排列顺序#
word.sort(key=lambda x:x[1],reverse=True)
print(word)
for i in range(20):
print(word[i])
#另存为csv文件#
import pandas as pd
pd.DataFrame(data=word).to_csv('Harry Potter.csv',encoding='utf-8')
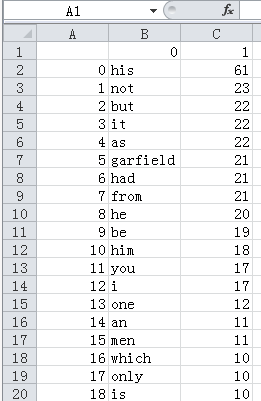
生成的图片如下:

